LSTM(Long-Short Term Memory)과 GRU(gated Recurrent Unit)(코드 추가해야함)
💛 LSTM(Long-Short Term Memory,장단기기억망)
RNN에 기울기 정보 크기를 조절하기 위한 Gate를 추가한 모델을 LSTM이라고 한다.
최근 많이 쓰이는 모델로 RNN이라고 하면 LSTM이나 GRU를 지칭할 정도로 sequential 데이터를 처리하는 대표적인 모델로 자리매김했다. 전에 정리한 기본적인 RNN을 Vanilla RNN이라고 따로 구별하여 표현할 정도이다.
기울기 소실(Vanashing Gradient)문제를 해결하기 위한 LSTM에 대해 더 자세히 알아보았다.
❗️ 기울기 소실: 역전파 과정에서 입력층으로 갈수록 기울기가 점차 작아지는 현상. 입력층에 가까운 층들에서 가중치들이 업데이트가 제대로 되지 않으면 최적의 모델을 찾을 수 없게 된다.
LSTM의 구조
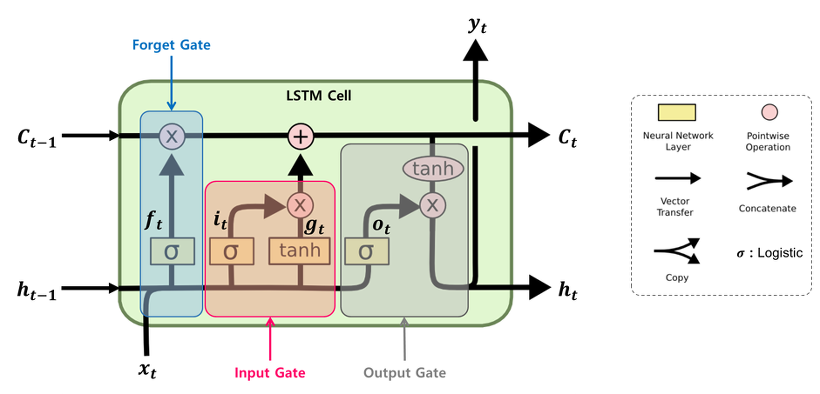
LSTM은 기울기 소실을 해결하기 위해 등장한 신경망 언어 모델이다.
RNN에 기울기 정보 크기를 조절하기 위한 gate를 추가한 모델인데, 이 gate에는 3가지 종류가 있다.
- forget gate (): 과거 정보를 얼마나 유지할 것인가?
- input gate () : 새로 입력된 정보는 얼마만큼 활용할 것인가?
- output gate () : 두 정보를 계산하여 나온 출력 정보를 얼마만큼 넘겨줄 것인가?
hidden-state 말고도 활성화 함수를 직접 거치지 않는 상태인 cell-state가 추가되었다.
cell-state는 역전파 과정에서 역전파 과정에서 활성화 함수를 거치지 않아 정보 손실이 없기 때문에 뒷쪽 시퀀스의 정보에 비중을 결정할 수 있으면서 동시에 앞쪽 시퀀스의 정보를 완전히 잃지 않을 수 있다.
LSTM의 역전파

복잡하기 때문에..나중에 복습하면서 정리하도록 하겠다...
LSTM의 사용
여러 언어 모델에서 LSTM을 사용하고 있다.
gate가 적용되지 않은 RNN, 즉 vanilia RNN은 10~20 단어로 이루어진 문장에 대한 분류/생성/번역 등의 성능이 매우 낮다. 기울기 소실/폭발 문제 때문이다. 언어 모델뿐만 아니라 신경망을 활용한 시계열 알고리즘에는 대부분 LSTM을 사용하고 있다.
💛 GRU(Gated Recurrent Unit)
GRU는 LSTM의 간소화된 버전이라고 할 수 있다.
GRU의 구조
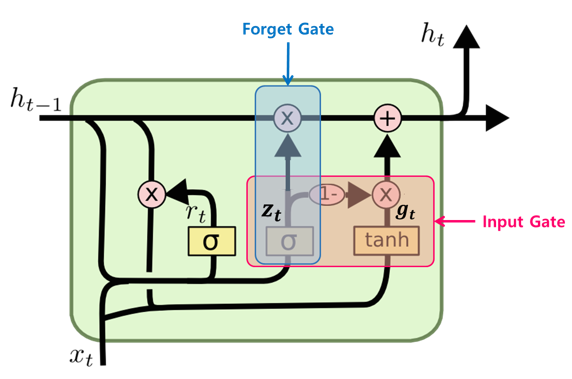
GRU 셀의 특징
- LSTM에 있었던 cell-state가 사라졌다.
cell-state 벡터 와 hidden-state 벡터 가 하나의 벡터 로 통일되었다. - 하나의 gate 가 forget, input gate를 모두 제어한다.
가 1이면 forget gate가 열리고, input gate가 닫히게 되는 것과 같은 효과를 나타낸다.
가 0이면 input gate만 열리는 것과 같은 효과를 나타낸다. - GRU 셀에서는 output gate가 없어졌다.
대신 전체 상태 벡터 가 각 time-stemp에서 출력되며 이전 상태의 의 어느 부분이 출력될지 새롭게 제어하는 gate인 가 추가되었다.
코드
(복습하면서 추가하기)
RNN구조에 Attention 적용하기
RNN이 가진 가장 큰 단점 중 하나는 기울기 소실로부터 나타나는 장기의존성(Long-term dependency)문제이다.
장기의존성 문제란 문장이 길어질 경우 앞 단어의 정보를 잃어버리게 되는 현상으로 장기 의존성 문제를 해결하기 위해 나온 것이 셀 구조를 개선한 LSTM와 GRU이다.
기계 번역에서 기존 RNN 기반의 모델(LSTM, GRU)이 단어를 처리하는 방법은 아래와 같다.

Attention의 등장
기존 RNN 기반의 모델(LSTM, GRU) 구조의 문제점은 고정 길이의 hidden state 벡터에 모든 다어의 의미를 담아야 한다는 점이다. LSTM, GRU가 장기 의존성 문제를 개선했다하더라도 30~50 단어로 구성된 긴 문장이면 모든 단어 정보를 고정 길이의 hidden-state 벡터에 담기 어렵다. 이러한 문제를 해결하기 위해서 고안된 방법이 Attention(attention)이다.
Attention은 각 인코더의 time-stamp마다 생성되는 Hiddn-state 벡터를 간직한다. 입력 단어가 N개라면 N개의 hidden-state 벡터를 모두 간직하게 된다. 모든 단어가 입력되면 생성된 Hidden-state 벡터를 모두 디코더에 넘겨준다.
디코더에서 attention이 동작하는 방법
검색 시스템의 아이디어:
1. 찾고자 하는 정보에 대한 검색어(query)를 입력한다.
2. 검색 엔진은 검색어와 가장 비슷한 키워드(key)를 찾는다.
3. 해당 키워드(key)와 연결된 페이지(value)를 유사도 순서대로 보여준다.
파이썬 딕셔너리도 비슷한 형태로 작동한다.
디코더에서 단어를 생성하는 과정을 정리해보고자 한다.
디코더의 각 time-stamp마다 hidden-state 벡터는 쿼리(query)로 작용한다.
인코더에서 넘어온 N개의 hidden-state 벡터를 키(key)로 여기고 이들과의 연관성을 계산한다.
이 때 계산은 내적(dot-product)을 사용하고 내적의 결과를 attnetion 가중치로 사용한다.
아래의 이미지는 디코더 첫 단어 "I"(time-stamp=4)에 대한 attention 가중치가 구해지는 과정이다.
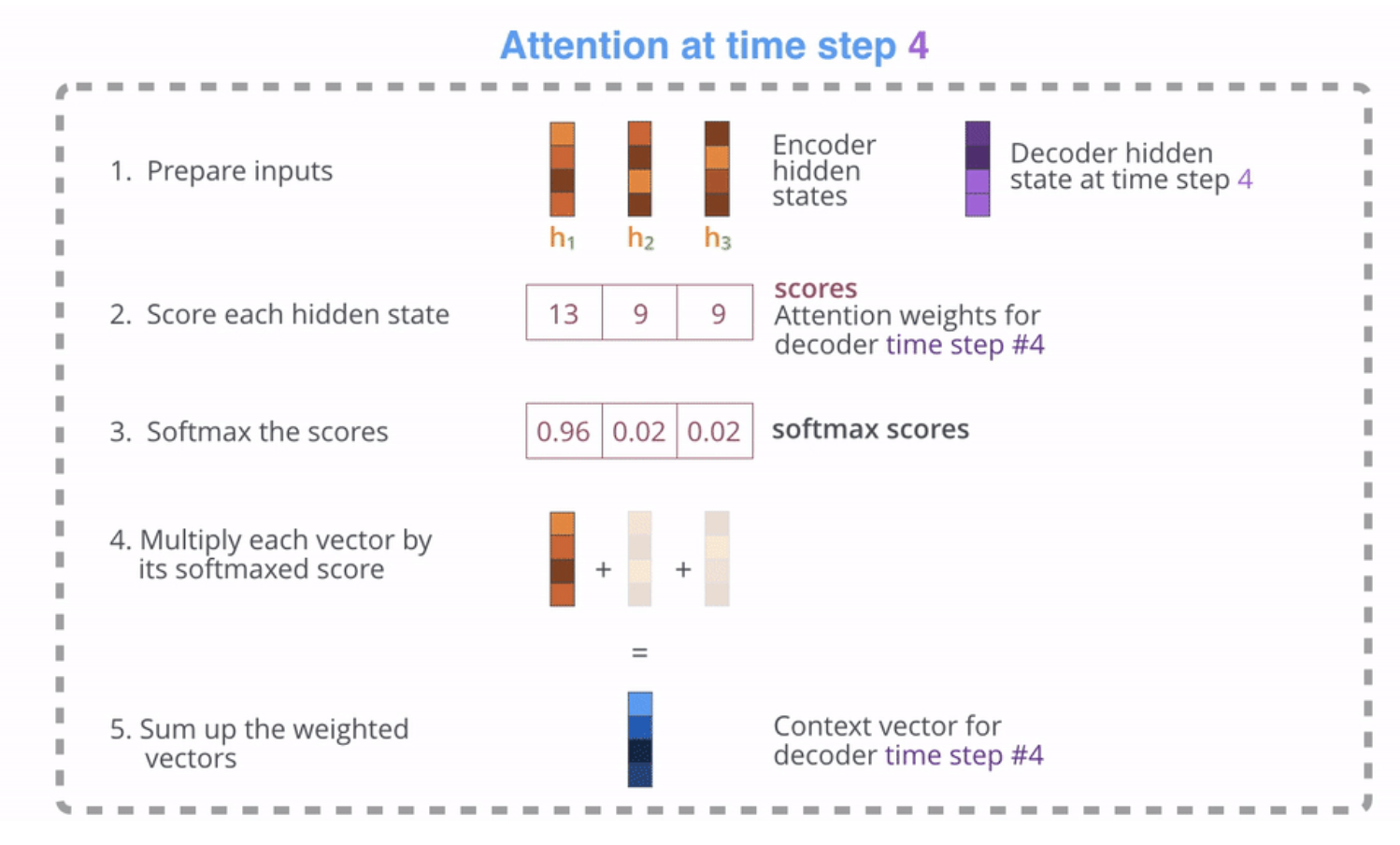
- 쿼리(query, 보라색)로 디코더의 hidden-state 벡터를 준비하고 키(key, 주황색)로 인코더에서 넘어온 각각의 hidden-state 벡터를 준비한다.
- 각각의 벡터를 내적한 값을 구한다.
- 내적한 값에 소프트맥스 함수를 취해준다.
- 소프트맥스를 취해 나온 값에 밸류(value, 주황색)에 해당하는, 인코더에서 넘어온 hidden-state 벡터를 곱해준다.
- 이 벡터를 모두 더하여 context 벡터(파란색)을 만들어준다. 이 벡터의 성분 중에는 쿼리-키 연관성이 높은 밸류 벡터의 성분이 더 많이 들어있게 된다.
- 최종적으로 5에서 생성된 context 벡터와 디코더의 hidden-state 백터를 사용하여 출력단어를 결정하게 된다.
디코더는 인코더에서 넘어온 모든 hidden state 벡터에 대해 위와 같은 계산을 하게 된다.
그렇기 때문에 time-step마다 출력할 단어가 어떤 인코더의 어떤 단어 정보와 연관되어 있는지, 어떤 단어에 집중할 것인지를 알 수 있다.
attention을 활용하면 디코더가 인코더에 입력되는 모든 단어의 정보를 활용할 수 있기 때문에 장기 의존성 문제를 해결할 수 있다.

Je suis etudiant라는 문장이 있다면 이 문장을 번역할 때 각 단어마다의 attention score를 시각화하한 것이 위의 이미지이다. 위의 이미지를 따르면 왼쪽의 단어가 생성될 때 오른쪽 단어와 연관되어있다는 것을 확인할 수 있다.
"I" -> "Je"
"am" -> "suis"
"a" -> "suis", "etudiant"
"student" -> "etudiant"
