💛 순환 신경망(RNN, Recurrent Neural Network)
인공 신경망 언어모델에서 사용되는 RNN(순환 신경망)은 연속형 데이터를 처리하기 위해 고안된 신경망 구조이다.
연속형 데이터(Sequential Data)
- 연속형 데이터(Sequential Data): 어떤 순서로 오느냐에 따라서 단위의 의미가 달라지는 데이터
예) 자연어, 시계열 데이터- 불연속형 데이터(Non-sequential Data): 순서에 따라 단위의 의미가 달라지지 않는 데이터
예) 일반적인 사진
연속형 데이터는 순서에 따라 단위의 의미가 달라지는 데이터이다. 상담사의 질의응답, 한국어-영어 번역(병렬) 말뭉치나 도서자료 요약 등은 일반적으로 순서에 따라 데이터의 의미가 달라져버린다. 반면 일반적인 사진 등은 순서를 바꾸어도 내용이 크게 달라지지 않는다.
RNN의 구조
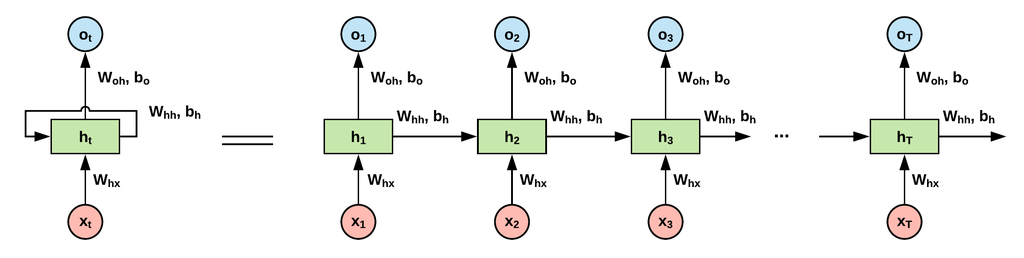
등호의 왼쪽은 RNN의 전체적인 구조이다.
전체적인 구조의 3개의 화살표를 나눠보면 아래와 같다.
- 입력 벡터가 은닉층에 들어가는 것을 나타내는 화살표
- 은닉층으로부터 출력 벡터가 생성되는 것을 나타내는 화살표
- 은닉층에서 나와 다시 은닉층으로 입력되는 것을 나타내는 화살표
기존 신경망에서는 은닉층에서 나와 다시 은닉층으로 입력되는 과정은 없었다.
이 화살표는 특정 시점에서의 은닉 벡터가 다음 시점의 입력 벡터로 다시 들어가는 과정을 나타내고 있다.
이처럼 출력 벡터가 다시 입력되는 특성으로 인해 이러한 신경망을 순환 신경망(RNN, Recurrent Neural Network)이라고 부른다.
time-stemp별로 펼쳐서 RNN 알아보기
기본 네트워크가 등호 왼쪽처럼 표시되지만 신경망을 시점에 따라 펼쳐보면 등호 오른쪽의 그림처럼 나타낼 수 있다.
- 시점:
와 가 입력, 이 출력. - 시점:
와 입력, 이 출력 - 시점:
와 가 입력, 이 출력
t시점의 RNN 계층은 그 계층으로의 입력 벡터 와 1개 전의 RNN 계층의 출력 벡터 를 받아들인다. 입력된 두 벡터를 바탕으로 해당 시점에서의 출력을 아래와 같이 계산한다.
t시점에서 RNN 계층이 출력 벡터를 만드는 과정
가중치는 2개가 있다.
가중치 는 입력 를 출력벡터 h로 변환하기 위한 것이고
가중치 는 RNN의 은닉층의 출력을 다음 로 변환하기 위한 것이다.
는 각 편향(bias)을 단순화하여 나타낸 항이다.
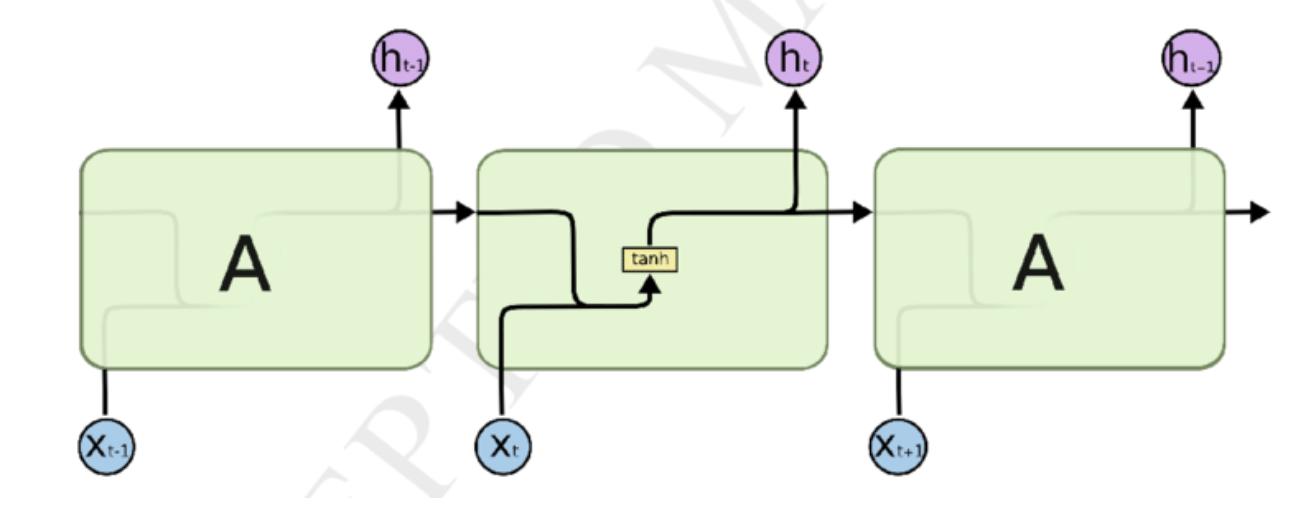
이렇게 하면 t 시점에 생성되는 은닉층 벡터인 는 해당 시점까지 입력된 벡터 의 정보를 모두 가지고 있다.
이러한 sequential(연속형) 데이터의 순서 정보를 모두 기억하기 때문에 Sequential 데이터를 다룰 때 RNN을 많이 사용한다.
다양한 RNN 형태들
RNN에는 다양한 형태들이 있다. 아래의 그림에서 가장 왼쪽에 있는 one-to-one은 실질적으로 순환되는 것이 아니라는 점을 유의해야한다. 따라서나머지 4개의 RNN이 각각 어떤 분야에 있는지 정리해보고자 한다.
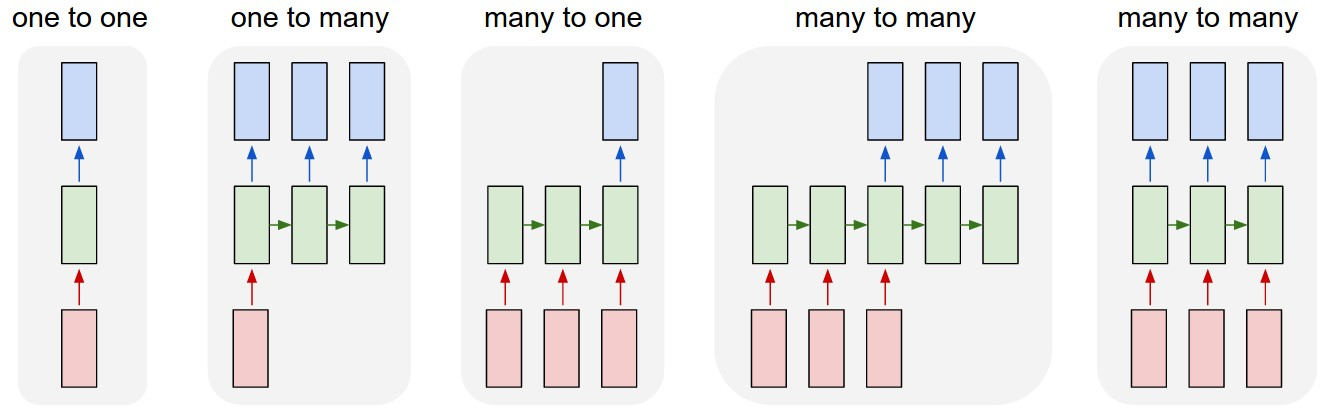
- one-to-many
1개의 벡터를 받아 sequential한 벡 터를 반환한다.
이미지를 입력받아 이를 설명하는 문장을 만들어내는 이미지 캡셔닝(Image Captioning)에 사용된다. - many-to-one
sequential한 벡터를 받아 1개의 벡터를 반환한다.
문장이 긍정인지 부정인지 판단하는 감성 분석(sentiment analysis)에 사용된다. - many-to-many(Sequence-to-Sequence, Seq2Seq)
sequential한 벡터를 받아 모두 입력한 뒤 sequential한 벡터를 출력한다.
시퀀스-투-시퀀스(Sequence-to-Sequence, Seq2Seq)라고도 불린다.
번역할 문장을 입력받아 번역된 문장을 내놓는 기계 번역(Machine translation)에 사용된다. - many-to-many
sequential 벡터를 입력받는 즉시 sequential 벡터를 출력한다.
비디오를 프레임별로 분류(video classification per frame)하는 곳에 사용된다.
RNN의 장단점
RNN의 장점
RNN은 모델이 이론적으로 모델이 간단하고 어떤 길이의 sequential 데이터라도 처리할 수 있다는 장점을 가지고 있다.
RNN의 단점
RNN의 단점 1: 병렬화(paralleization)불가능
RNN 구조가 가지고 있는 단점 중 하나는 벡터가 순차적으로 입력된다는 점이다.
이는 sequential 데이터 처리를 가능하게 해주는 요인이지만, 이러한 구조는 GPU연산의 장점인 병렬화를 불가능하게 만든다. 그렇기 때문에 RNN 기반의 모델은 GPU 연산을 했을 때 이점이 거의 없다는 단점을 가지고 있다.
RNN의 단점2: 기울기 폭발(exploding Gradient), 기울기 소실(Vanashing Gradient
단순 RNN의 치명적인 문제점은 역전파 과정에서 발생한다.
역전파 과정에서 RNN의 활성화 함수인 tanh의 미분값을 전달하게 되는데 tanh를 미분한 함수는 아래처럼 나타난다.
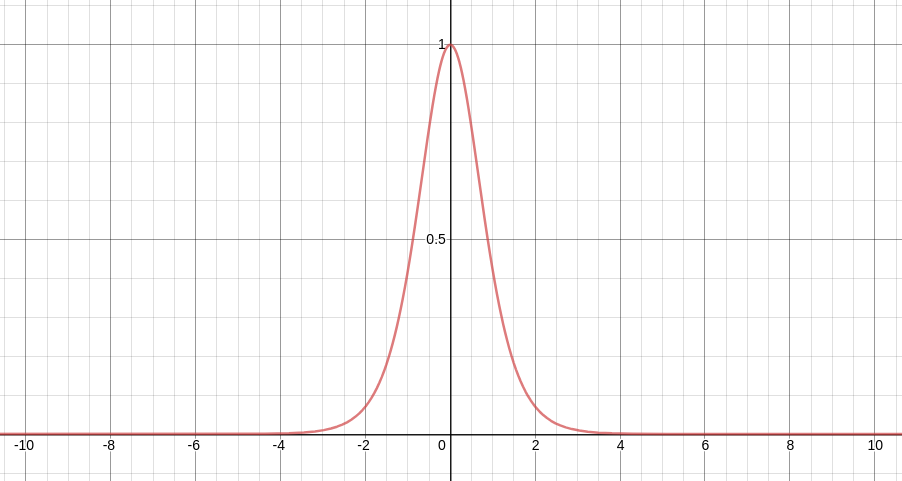
위 그래프에서 최댓값이 1이고 (-4, 4)이외의 범위에서는 거의 0에 가까운 값을 나타내는 것을 알 수 있습니다.
문제는 역전파 과정에서 이 값을 반복해서 곱해주어야 한다.
이 recurrent가 10회, 100회 반복된다고 보면, 이 값의 10제곱, 100제곱이 식 내부로 들어가게 된다.
만약 이 값이 0.9 일 때 10제곱이 된다면 0.349가 된다. 이렇게 되면 시퀀스 앞쪽에 있는 Hidden-state 벡터에는 역전파 정보가 거의 전달되지 않는다. 이런 문제를 기울기 소실(Vanishing Gradient)이라고 한다.
반대로 이 값이 1.1이면 10제곱만해도 2.59배로 커지게 된다. 이렇게 되면 시퀀스 앞쪽에 있는 hidden-state 벡터에는 역전파 정보가 과하게 전달되는데 이러한 문제를 기울기 폭발(Exploding Gradient)라고 한다.
기울기 정보의 크기가 문제라면 기울기 정보의 크기를 조정하여 문제를 해결하는 방법을 생각해볼 수 있다.
이러한 아이디어에서 고안된것이 바로 장단기 기억망(Long-Short Term Memory, LSTM)이다,
