💛 머신러닝의 방법
머신러닝은 특정한 문제를 주어진 상황으로부터 기계가 스스로 학습을 해서 풀 수 있게 하는 기술이다. 이러한 머신러닝에는 매우 다양한 방법들이 있으며 지금도 개발되고 있다.
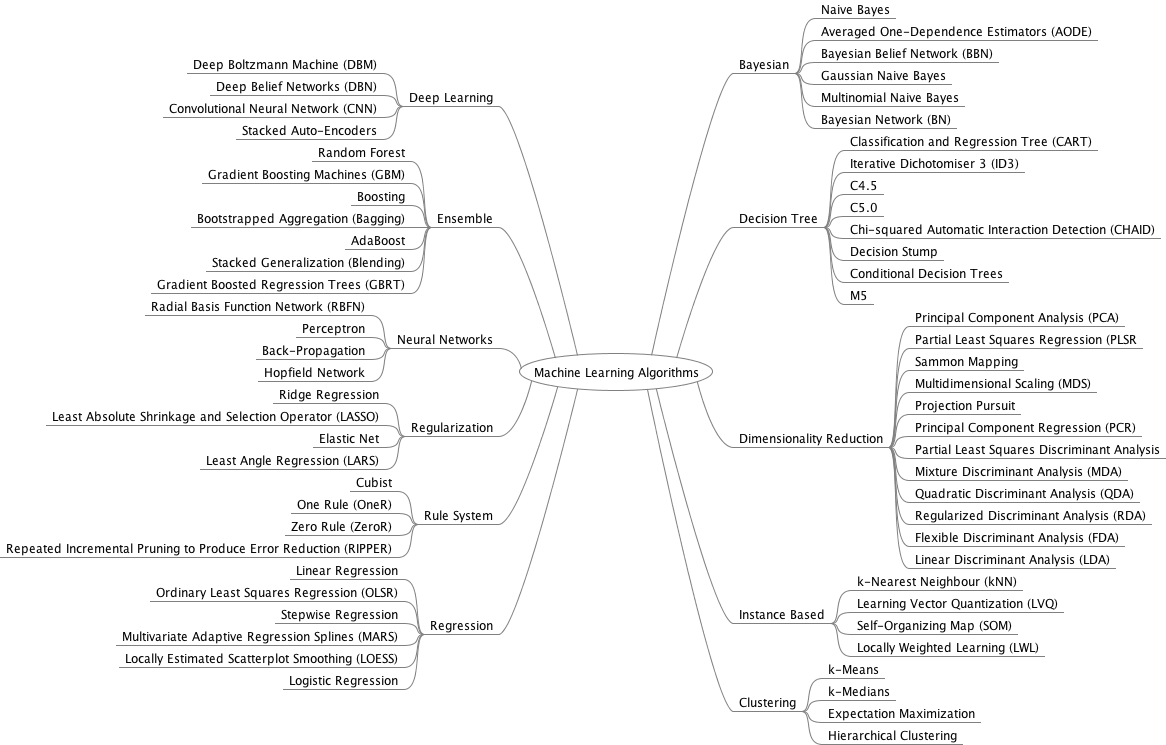
위의 그림보다도 훨씬 많은 방법들이 있지만 머신러닝은 크게 두 가지 기준으로 분류할 수 있다.
💜 데이터의 특징(input): 답(label 혹은 target)의 유무
💜 데이터의 목적(output): 예측(prediction) 혹은 분류(classification)
⭐️ 지도학습(Supervised Learning)
트레이닝 데이터에 답(label 혹은 target)이 있을 때 사용할 수 있다.
-
분류 (Classification)
분류 알고리즘은 주어진 데이터의 category 혹은 class를 예측한다.
-
회귀 (Prediction)
회귀 알고리즘은 연속형 데이터를 바탕으로 결과를 예측하기 위해 사용
⭐️ 비지도학습(Unsupervised Learning)
트레이닝 데이터에 답(label 혹은 target)이 없을 때 사용할 수 있다.
-
클러스터링 (Clustering)
데이터의 연관된 feature를 바탕으로 유사한 그룹을 생성한다.
-
차원 축소 (Dimensionality Reduction)
높은 차원을 갖는 데이터셋을 사용하여 feature selection / extraction 등을 통해 차원을 줄인다.
-
연관 규칙 학습 (Association Rule Learning)
데이터셋의 feature들간의 관계를 발견하는 방법이다. (feature-output 이 아닌 feature-feature)
예) 기저귀를 구매한 사람은 높은 확률로 맥주를 구입했다.(예전에 통계학 수업을 들었을 때 들었던 예시인데 기저귀와 맥주라는 feature는 별개의 특성이지만 아기를 키우는 사람이 둘을 구매했다는 것을 연관지어서 분석할 수 있다.(육아를 하는 사람은 쇼핑할 때 육아에 필요한 물건도 사고 육아 스트레스를 풀만한 물건도 사는구나 등))
⭐️ 강화학습(reinforcement Learning)
머신러닝의 한 형태로, 기계가 좋은 행동에 대해서는 좋은 행동을 하게 만든 파라미터에 가중치를 두는 '보상'같은 피드백을 통해 행동에 대해서 학습해 나가는 형태이다.
위의 비지도학습과 지도학습과는 결이 다르지만 이러한 머신러닝도 있다!
❤️ Clustering(클러스터링, 군집화)
Clustering: 연관된 feature를 바탕으로 유사한 데이터들을 그룹을 만드는 것.
- nsupervised Learning Algorithm(비지도학습)의 한 종류이다.
- Train Data에 대해서 label도 없고, 몇 개의 클러스터가 정확한지조차도 없는 경우도 있다.
- 주어진 데이터들이 얼마나, 어떻게 유사한지 살펴볼 수 있는 방법
- 주어진 데이터셋을 요약/정리하는데 있어서 매우 효율적인 방법.
- cluster의 결과나 정답을 보장하지 않기 때문에 EDA와 시각화를 위한 방법으로 많이 사용.(production의 수준, 혹은 예측을 위한 모델링에는 잘 쓰이지 않음.)
🍒 Clustering의 종류
Hierarchial
- Agglomerative: 개별 포인트에서 시작후 점점 크게 합쳐감
- Divisive: 한 개의 큰 cluster에서 시작 후 점점 작은 cluster로 나눠감
Point Assignment
시작 시에 cluster의 수를 정한 다음, 데이터들을 하나씩 cluster에 배정시킴
Hard vs Soft Clustering
- Hard Clustering: 데이터를 하나의 cluster에만 할당.
- Soft Clustering: 데이터를 여러 cluster에 확률을 가지고 할당.
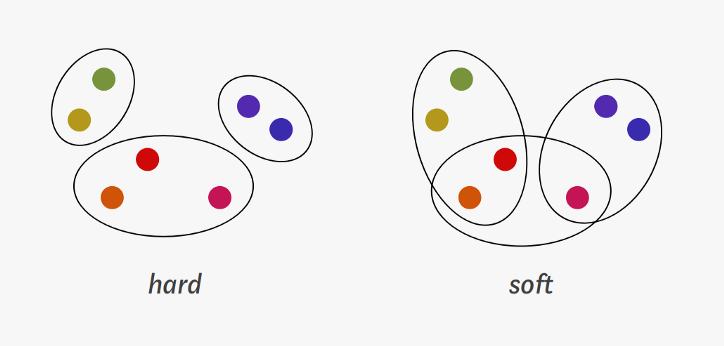
일반적으로는 Hard Clustering을 clustering이라고 한다.
Similarity
Euclidean, Cosine, Jaccard, Edit Distance 등을 통해 데이터 간의 거리(distance)를 측정하여 유사한 정도를 파악하여 clustering을 한다.
일반적으로 많이 쓰이는 방식은 Euclidean 이지만 각 목적에 따라 다른 방식들도 자주 사용되기 때문에 clustering 알고리즘이나 distance 방식을 공부하는 게 좋다.
Euclidean

이 그림에서 pq의 길이 즉, d(p,d)
- 수동으로 구하기
import numpy as np
x = np.array([1, 2, 3])
y = np.array([1, 3, 5])
dist = np.linalg.norm(x-y) #놂을 배운 이유
dist- 라이브러리 사용해서 구하기
from scipy.spatial import distance
distances = distance.cdist(df, centroids, 'euclidean')❓ 클러스터는 비슷한 것끼리 묶는 것이라면 데이터가 비슷하다는 것은 어떤 의미일까?
데이터가 비슷하다 = 차이가 작다 = 흩어진 정도가 작다 = 분산이 작다 = 거리가 짧다 정도로 생각이 되는데 점검할 필요 있음.
💛 K-means Clustering
주어진 데이터를 k개의 클러스터로 묶고 클러스터의 중심을 평균에 기반해 설정하는 알고리즘으로, 각 클러스터끼리의 유클리드 거리 차이의 분산을 최소화하는 방식으로 동작한다.
중심점(centroid)
중심점(centroid)을 기준으로 clustering되는 형식이기 때문에 centroid-based clustering이라고도 불린다.Centroid란, 주어진 cluster 내부에 있는 모든 점들의 중심부분에 위치한 (가상의) 점이다.
k-means는 centroid를 어떻게 선택하느냐에 따라서, clustering의 결과가 안 좋거나 끝없이 반복해야 하는 경우도 있다.
Process of K-means Clustering
n-차원의 데이터에 대해서:
1️⃣ k 개의 랜덤한 데이터를 cluster의 중심점으로 설정
2️⃣ 해당 cluster에 근접해 있는 데이터를 cluster로 할당
3️⃣ 변경된 cluster에 대해서 중심점을 새로 계산
cluster에 유의미한 변화가 없을 때 까지 2-3을 반복
python with K-means Clustering
from sklearn.cluster import KMeans
#3개의 클러스터로 구하기
kmeans = KMeans(n_clusters = 3)
kmeans.fit(x)
labels = kmeans.labels_
print(labels)
>>>[1 1 0 0 2 0 0 2 2 0 0 0 0 0 2 2 0 1 0 2 1 2 0 1 1 1 0 0 1 2 2 2 1 1 1 0 1 2 0 2 2 0 1 2 1 2 2 1 0 0 1 0 2 2 2 1 1 0 1 2 1 0 2 2 2 1 1 1 0 1 2 0 1 0 1 2 1 2 1 0 0 0 0 2 0 2 2 2 2 2 1 0 1 1 1 2 1 0 1 0]
new_series = pd.Series(labels)
df['clusters'] = new_series.values
df.head()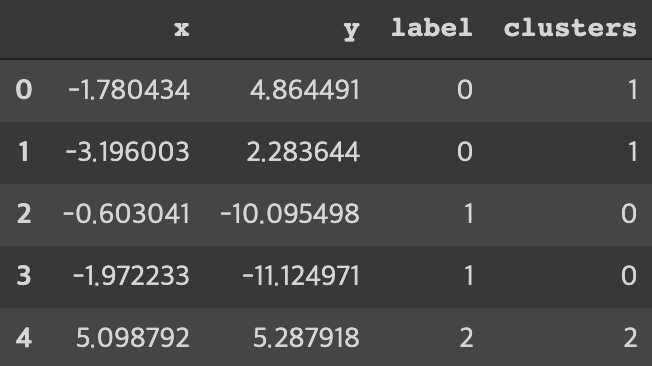
이것을 시각화하면 아래와 같다.
centroids = get_centroids(df, 'clusters')
plot_clusters(df, 'clusters', centroids)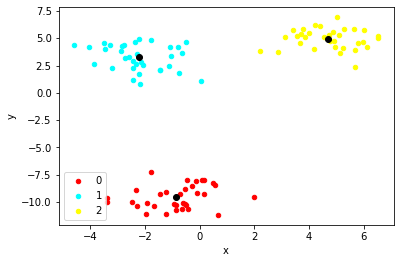
python with K-means Clustering (manual)
0️⃣ 데이터 불러오기 및 표준화
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
#0-1) 샘플의 개수가 100개이고 센터가 3개인 feature가 2개인 데이터 만들기
x, y = make_blobs(n_samples = 100, centers = 3, n_features = 2)
df = pd.DataFrame(dict(x = x[:, 0], y = x[:, 1], label = y))
#0-2)시각적으로 확인해서 데이터 파악하기
colors = {0 : '#eb4d4b', 1 : '#4834d4', 2 : '#6ab04c'}
fig, ax = plt.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax = ax, kind = 'scatter', x = 'x', y = 'y', label = key, color = colors[key])
plt.show()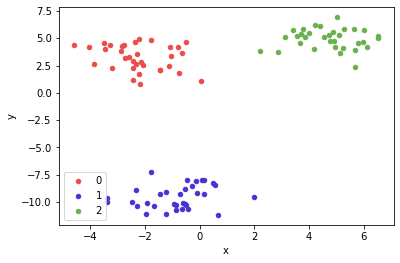
이러한 데이터들을 담은 데이터프레임은
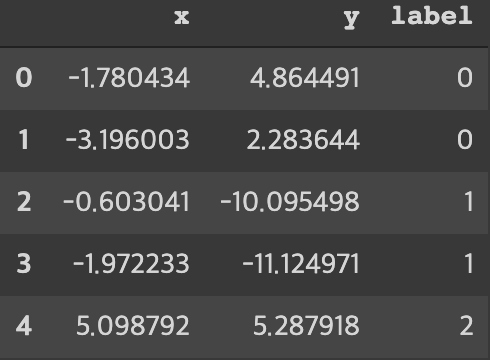
이런 식이다. 이때, 비지도학습인 K-means clustering을 하기 위해서 label을 일부러 없애서 K-means clustering을 해본다.
points = df.drop('label', axis = 1) # label 삭제
points
1️⃣ k개의 랜덤한 데이터를 cluster의 중심점으로 설정
#각 평균의 값은 다음과 같을 것이다.
dataset_centroid_x = points.x.mean()
dataset_centroid_y = points.y.mean()
#이 실제 평균의 값에 해당하는 데이터가 없을 수 있기 때문에 k개의 랜덤한 데이터를 cluster의 중심점으로 설정한다.(여기에서는 센터가 3개인 데이터라는 것을 알고 있기 때문에 3개라고 했다.)
centroids = points.sample(3) # k-means with 3 cluster
centroids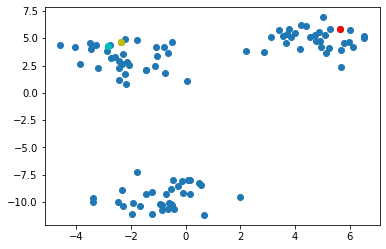
색깔이 있는 점들은 랜덤하게 뽑은 값인데 보다시피 각 클러스터의 중심에서 멀 수 있다.
2️⃣ 해당 cluster에 근접해 있는 데이터를 cluster로 할당
import math
import numpy as np
from scipy.spatial import distance
def find_nearest_centroid(df, centroids, iteration):
# 포인트와 centroid 간의 거리 계산
distances = distance.cdist(df, centroids, 'euclidean')
# 제일 근접한 centroid 선택
nearest_centroids = np.argmin(distances, axis = 1)
# cluster 할당
se = pd.Series(nearest_centroids)
df['cluster_' + iteration] = se.values
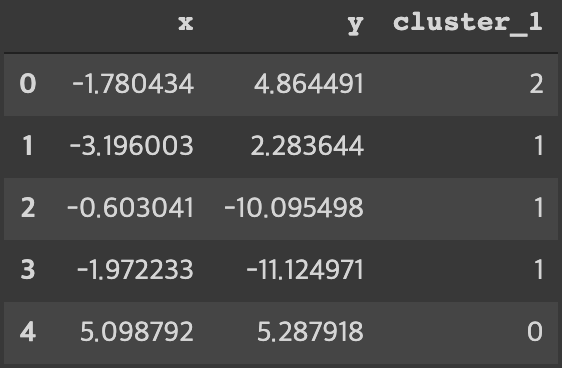
return dffirst_pass = find_nearest_centroid(points.select_dtypes(exclude='int64'), centroids, '1')
first_pass이 함수의 결과값은 아래와 같다.
import math
import numpy as np
from scipy.spatial import distance
def find_nearest_centroid(df, centroids, iteration):
# 포인트와 centroid 간의 거리 계산
distances = distance.cdist(df, centroids, 'euclidean')
# 제일 근접한 centroid 선택
nearest_centroids = np.argmin(distances, axis = 1)
# cluster 할당
se = pd.Series(nearest_centroids)
df['cluster_' + iteration] = se.values
return df3️⃣ 변경된 cluster에 대해서 중심점을 새로 계산
기존의 cluster와 중심점 그려서 확인해보기
def plot_clusters(df, column_header, centroids):
colors = {0 : 'red', 1 : 'cyan', 2 : 'yellow'}
fig, ax = plt.subplots()
ax.plot(centroids.iloc[0].x, centroids.iloc[0].y, "ok") # 기존 중심점
ax.plot(centroids.iloc[1].x, centroids.iloc[1].y, "ok")
ax.plot(centroids.iloc[2].x, centroids.iloc[2].y, "ok")
grouped = df.groupby(column_header)
for key, group in grouped:
group.plot(ax = ax, kind = 'scatter', x = 'x', y = 'y', label = key, color = colors[key])
plt.show()
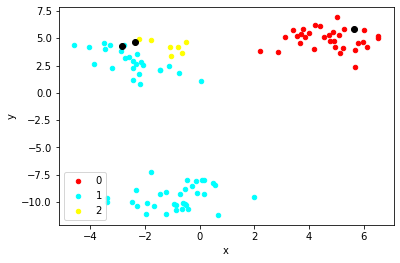
plot_clusters(first_pass, 'cluster_1', centroids)이 이미지는 기존의 클러스터와 중심점을 잡은 것을 그린 것이다. 분류가 잘 되어있지 않은 것을 색깔을 통해 확인할 수 있다.
🍎 새로운 centroid를 계산하고 넣는 식 만들기
def get_centroids(df, column_header):
new_centroids = df.groupby(column_header).mean()
return new_centroids
centroids = get_centroids(first_pass, 'cluster_1')
centroids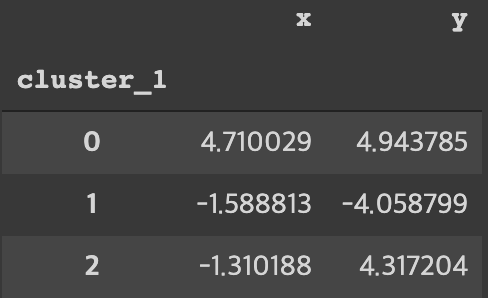
🍎 변경된 cluster에 대해 centroid 계산하기
# 변경된 cluster에 대해 centroid 계산
centroids = get_centroids(first_pass, 'cluster_1')
second_pass = find_nearest_centroid(first_pass.select_dtypes(exclude='int64'), centroids, '2')
plot_clusters(second_pass, 'cluster_2', centroids)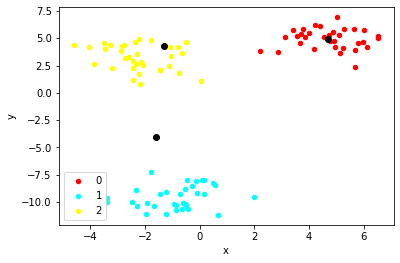
이런 식으로 유의미한 차이가 없어질 때까지 반복해준다.
데이터가 아주 크면 PCA로 전처리를 하고, K-means를 메인 "머신러닝"으로 사용하는 파이프라인도 있다.
K-means에서 K를 결정하는 방법
아래의 방법 외에도 K를 결정하는 방법은 다양하다.
- The Eyeball Method :사람의 주관적인 판단을 통해서 임의로 지정하는 방법. 도메인 지식을 통해 직관적으로 설정하는 것이다.
- Metrics : 객관적인 지표를 설정하여, 최적화된 k를 선택하는 방법입니다.
- Elbow methods
해석은 scree plot과 비슷하다.
sum_of_squared_distances = []
K = range(1, 15)
for k in K:
km = KMeans(n_clusters = k)
km = km.fit(points)
sum_of_squared_distances.append(km.inertia_)
plt.plot(K, sum_of_squared_distances, 'bx-')
plt.xlabel('k')
plt.ylabel('Sum_of_squared_distances')
plt.title('Elbow Method For Optimal k')
plt.show()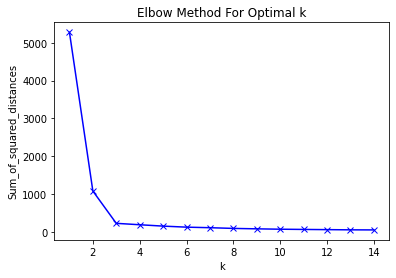
주어진 데이터에 대해서 k개로 클러스터링을 잘했다는 말은 클러스터 내부에 있는 데이터끼리 유사성이 높다는 말이므로 클러스터 내의 데이터끼리의 거리의 합이 작아야 좋다.
위의 엘보우 메소드에 의하면 3개 정도로 k가 설정되면 유의미하게 줄어든다.
💎 clustering은 매우 다양하다.
클로스터링에는 상당히 많은 방법이 있다. 계산 속도와 데이터 형식에 따라 클러스터링의 방식이 다르다.
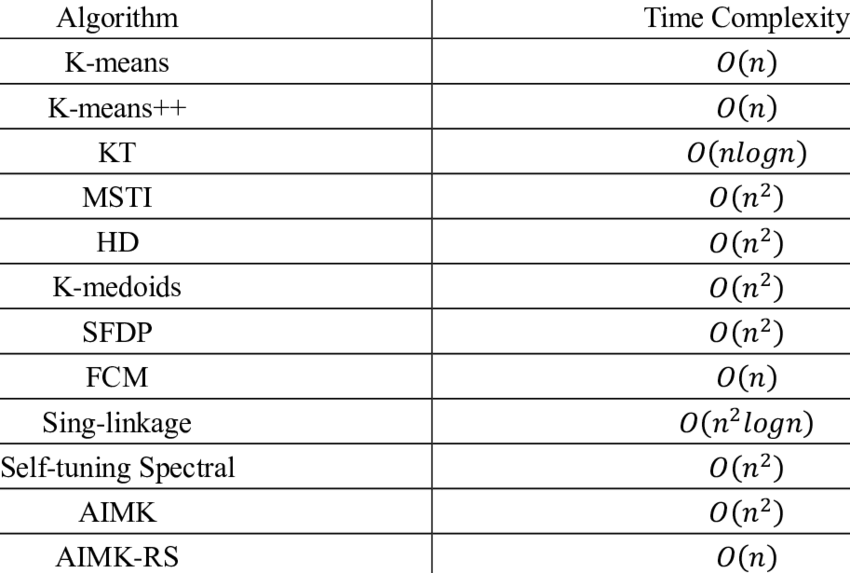
k-means clustering을 보완하기 위해서 다른 방법들을 쓸 수 있기도 하고 어떠한 문제를 푸는 데에는 k-means clustering이 최적화되어있지 않을 수 있다. 즉, 각각의 알고리즘은 각자 풀고자 하는 문제에 대해서 최적화되어있기 때문에 최적화된 문제를 제외한 다른부분에는 장점을 보이지 못한다.
❓ Hierarchical Clustering Visualization 중 dendrogram 그리기
