
Textual QA problems
텍스트의 정보를 얻을 수 있는 곳은 다음과 같다.
- text passage
- all web documents
- knowledge base
- tables
- images
질문의 종류에는 다음과 같은 것들이 있다.
- factoid vs non-factoid
- open-domain vs closed-domain
- simple vs compositional
답변의 종류에는 다음과 같은 것들이 있다.
- short segment of text
- a paragraph
- a list
- yes or no
딥러닝을 이용하여 해결하는 text QA에는 보통 knowledge base QA와 visual QA가 있는데 요번 강의에서는 전자만 다룬다.
지식 베이스 큐에이는 매우 큰 데이터베이스 기반에서 답할 수 있는 질문들에 답하는 시스템을 구축하는 것이다.
이를 해결하기 위해서는 질문을 일정한 로직폼으로 바꾸어여 한다.
Reading comprehension
reading comprehension이란, 주어진 passage를 이해하고, 그 콘텐츠에 대한 질문에 답하는 것이다.
따라서 input으로는 (P,Q) 즉, passage 와 question의 세트가 들어가고 output으로 답변이 나온다.
큐앤애이 문제는 크게 보면 컴퓨터가 사람의 언어를 얼마나 잘 이해하였는지를 테스트 하는 것과 같다.
- 정보를 추출하고
- semantic role labeling (의미 역할 부여)
하는 두 가지 작업으로 축소 할 수 있다.
Standford question answering dataset(SQuAD)
물론 얘네 학교가 만든거여서 보여주는 것이겠지만 대표적인 질문-답변 데이터셋이라고 한다.
(passage,question,answer)로 주석이 처리되어있고, passage는 영어이고 wikipedia에서 100~150단어로 가져왔다고 한다.
질문들은 crowded-sourcing으로 여러 사람들이 모여서 만들었다.
각각의 답변들은 passage안에서 찾을 수 있는 텍스트나 단어로 구성됨. 하지만 다 그런건 아니다..
평가하는 방법은 정확한 match(0 또는 1) 그리고 F1 score(partial credit)로 진행된다.
답이 여러개일 수도 있기 때문에 각 development, test set마다 3개의 gold answer이 수집된다.
각각의 gold answer와 predicted answer을 비교하여 평가한다(관사나 구두점은 제외한다)
아래는 예시이다.

Neural models for reading comprehension
SQuAD를 위한 모델을 build해볼 것이다.
input 데이터는 passage(=context) 과 question이다.
여기서 n은 100이내이고 m은 15이내이다. 확실한건 m이 무조건 더 짧다
output은 start와 end의 위치(?) 이다.
QA를 위한 대표적인 모델은 두개가 있다.
- A family of LSTM-based models with attention
- Fine-tuning BERT-like models for reading comprehension
Recap: seq2seq model with attention
1번 모델은 attention을 적용한 seq2seq 모델과 굉장히 비슷하므로 기억을 상기시켜주고 가드라 ( 아주 친절)
두 모델의 공통점이라고 하면,,source&target sentence를 가지는 것이다.
기본적으로 두개의 문장들이고, QA에서는 passage와 question이렇게 한 쌍이다. 길이는 다소 언발란스 하더라도…
QA모델에서 우리가 필요한 것은 어떤 passage의 단어가 question과 가장 유사한지 찾아주는 것이다.
이 부분에서 machine translation model과 굉장히 유사하다.
translation model은 source sentence의 어떤 문장이 현재의 target word와 가장 유사한지 찾는 것이기 때문이다.
따라서 QA모델에서 우리는 passage와 question사이의 attention을 모델링 해야하는 것이다.
가장 큰 차이점은 seq2seq모델은 decoder( autoregressice decoder)을 쌓아햐 한다는 것이다. 타겟 문장을 생성해야하기 때문.
하지만 QA모델은 generate할 필요가 없기 때문에 decoder가 없다.
1. BiDAF : Biderectional Attention flow model
전체적인 플로우는 다음 사진과 같다.
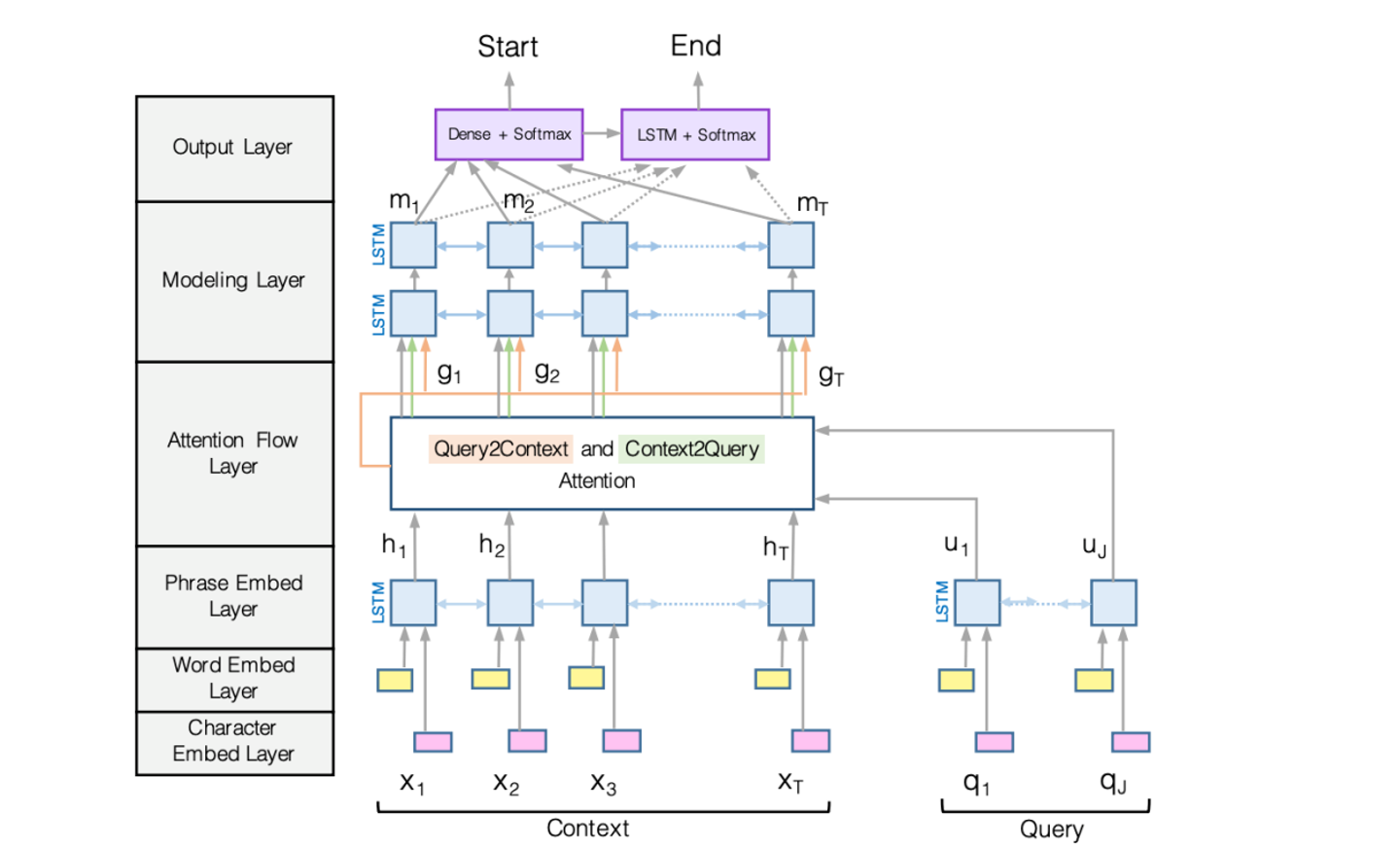
(1) BiDAF : Encoding
인코딩은 맨 아래 3가지의 순서를 거치는 것이다.
첫번째로 해야 할 것은 각 context와 query의 단어에서 Glove를 통한 word embedding과 CNN을 통한 character embedding을 concate하는 것이다.
수식으로 표현하면 다음과 같다.
f는 high-way network라고 한다 (논문참조하래)
각각의 단어를 인코딩한 후, 우리는 이것을 두개의 분리된 bidirectional LSTMs에 넣어줘야 한다.
그래야 context와 query 둘다에 대한 contextualized embeddings를 만들어 낼 수 있다.

이 양방향 LSTM은 context를 왼쪽과 오른쪽 방향 모두에서 capture하게 해준다.
(2) BiDAF: Attention(Attention Flow Layer)
아까전에도 말했지만 attention의 아이디어는 context와 query사이의 interaction을 capture하는 것이다.
attention에는 두 가지의 타입이 있다.
- context-to-query attention
context에 있는 문장에서 query로 화살표가 뻗어가는 유형.
각각의 context 단어들과 가장 유사한 query단어를 선택한다.

- query-to-context attention
위와 반대로 query에서 context로 화살표가 뻗어간다.
각각의 query 단어들과 가장 유사한 context 단어를 찾아 선택한다.

그래서 어떻게 하는데?
첫번째로 모든 context, query 쌍의 similarity score을 계산한다.
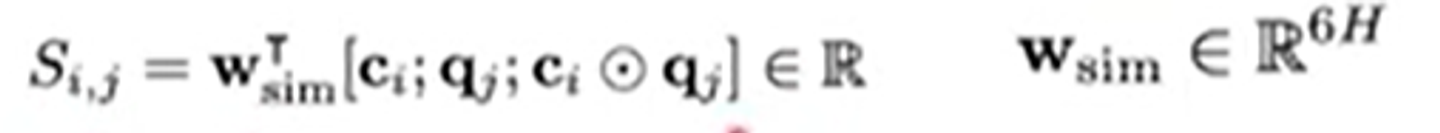
저 동그라미는 element-wise multiplication of and 라고 한다.
이 세가지 벡터들을 다 concate하면 된다.
output은 6H의 dimension을 가진 vector가 된다.
이를 dot product하여 learnable vector로 만들어준다.
두번째 과정에서 위에 말한 attention유형에 따라 계산이 달라진다.
- context-to-query유형( 어떤 질문의 단어가 문장과 가장 관련이 있을까?)
,
softmax를 각 행마다 게산해준다. 각 행마다 context word 한개가 대응하기 때문.
알파는 모든 question word의 확률분포가 된다.
마지막으로 와 weighted-combined 해주면 된다.
- query-to-attention(어떤 passage의 단어가 질문단어와 가장 관련이 있을까?)
,
…위 공식과 다른 점은 소프트맥스를 끼우기 전에 max를 취했다는 점이다.
각 행에서 가장 유사한 passage의 단어 쌍만을 찾은 뒤 소프트 맥스 해주는 것이다.
와 곱해 weighted-combined 해준다.
따라서 final output은 다음과 같다.

(3) BiDAF : Modeling and output layers
모델링 layer단계는 위에서 구한 g_i를 서로 다른 두 개의 층의 bi-directional LSTM에 넣는 것이다.
다시 말하지만 우리 모델의 attention은 query와 context사이의 상호작용을 모델링하는 것이다.
따라서 서로 다른 두 개의 bidirectional LSTM에 집어넣음으로서, modeling interaction within context words한다.
output layer은 start 와 end position을 예측하는 분류기로서 제공된다 ㅋ ㅋ
.이 값은 answer string이 시작되는 position을 제공한다.
..반대로 이 값은 answer string이 끝나는 position을 제공한다.
여기서는 신기하게 ’를 사용하는 데 이 값은 를 BiLSTM에 한번 집어넣고 나온 값이다.
’ 를 사용하는 이유는 무엇이냐? 라고 묻는다면..
start 와 end 사이의 dependece를 capture하기 위해서다.
start 와 end가 너무 멀어지면 안된다..따라서 이 처리를 해줌으로써 start 와 end를 각각 독립적으로 예측할 수 있게 하는 것이다.
final training loss는 다음과 같다.
2. BERT for reading comprehension
BERT는 deep bidirectional Transformer encoder ..이다 근데 이제 large amout of text에 pre-trained된…
BERT는 두가지 훈련 목적에 의해 pretrained 되었다.
- masked language model(MLM)
- next sentence prediction(NSP)
다음은 BERT의 간단한 모형도이다.
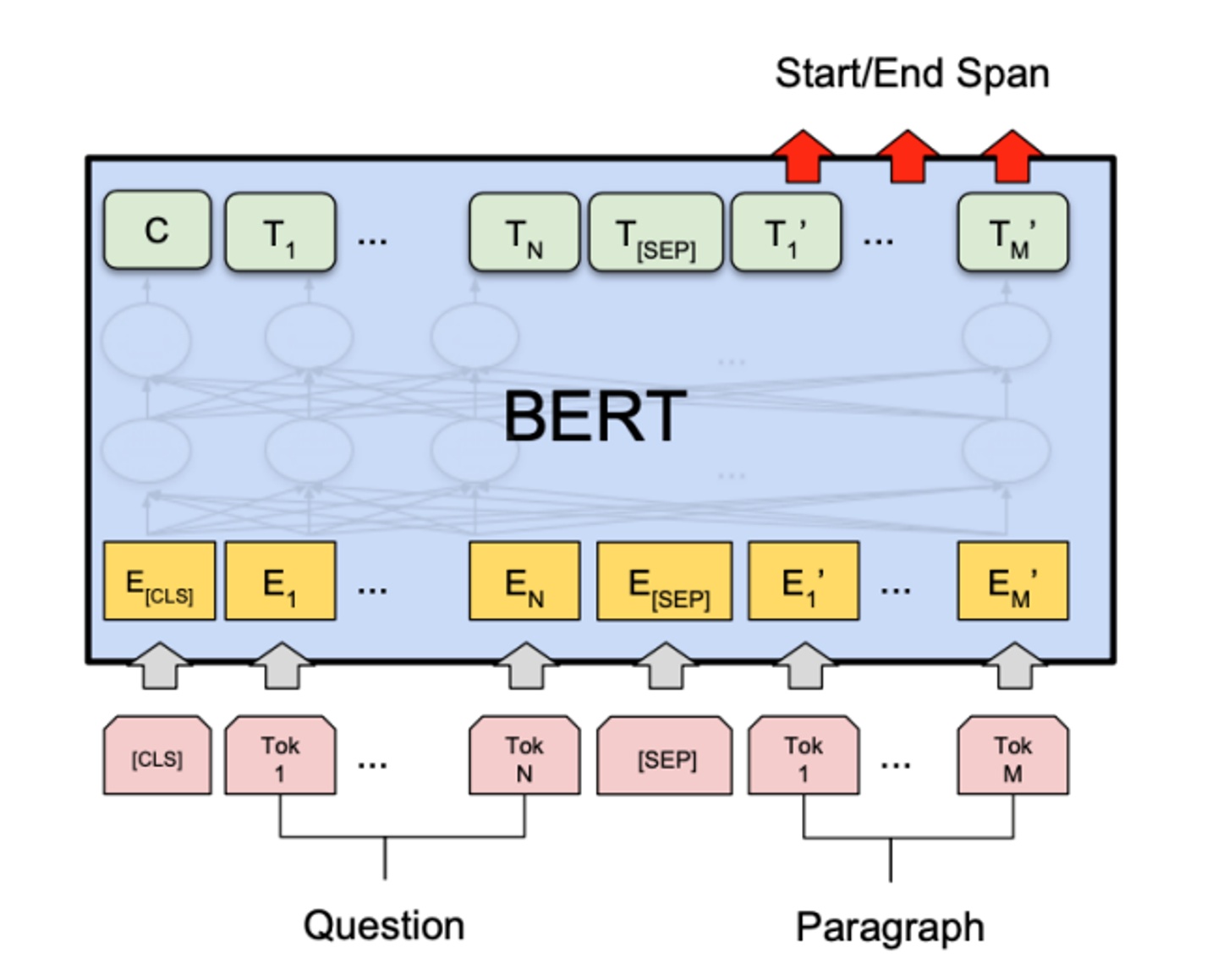
원래 BERT처럼 문장 시작에 [CLS]토큰, 연결할 때 [SEP]을 넣어준다.
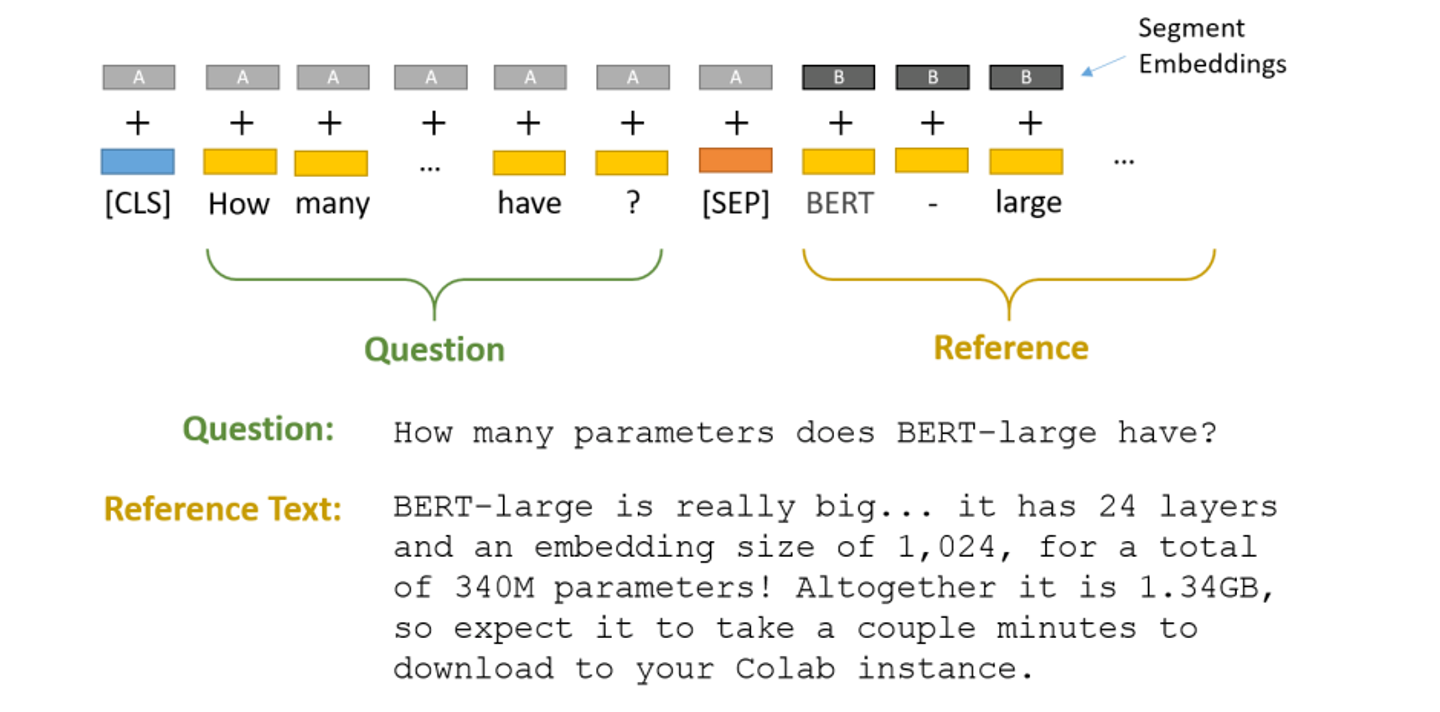
당연히 question과 passage가 함께 들어간다.
그리고 나서 segment embedding을 더해준다.
qustion에는 segment A를, passage에는 segment B를 임베딩 해준다.
Answer은 전의 모델과 마찬가지로 segment B에서의 두 가지 endpoints를 예측한다.
loss function과 start와 end 토큰의 확률값 계산은 다음과 같다.
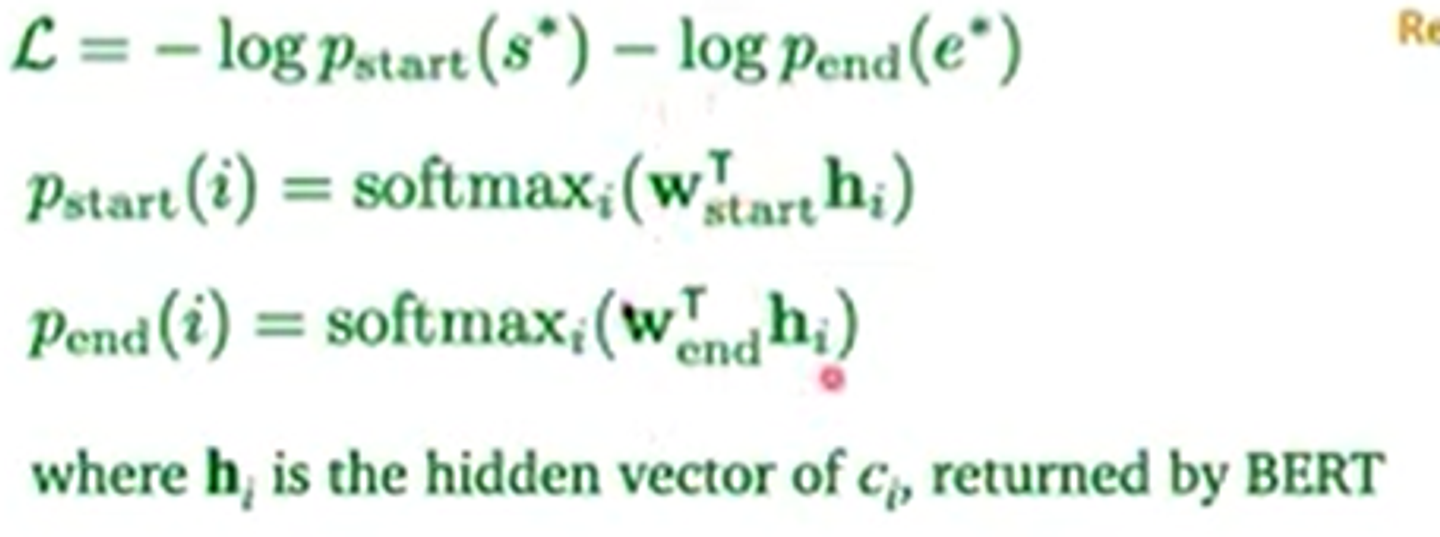
여기서 h_i는 BERT가 hidden vector로써 제공한다. (BERT 인코더의 output)
context word c_i에 대응하는 hidden vector을 주는 것이다.
원래 BERT의 엄청나게 많은 파라미터들과 새롭게 생긴 파라미터( ) 는 loss function과 함께 optimized 됩니당
3. Comparison between BiDAF and BERT models
가장 큰 차이점은 BERT가 파라미터가 무진장 더 많다는 것과
BIDAF는 마지막에 BiLSTM을 쌓지만, BERT는 transformer를 쌓는다는 것이다. (덕분에 recurrence architecture가 없고, parallelize하기 쉽다)
또한 BERT는 pre-trained된 모델이지만, BiDAF는 Glove로 시작한다.
하지만 근본적으로 비슷하다.
BiDAF는 question과 passage의 interaction을 모델링 하는 것이 목표이다
BERT는 question과 passage를 concat한 것에 self attention을 이용한다.
ex) =attention {(p,p)+(p,q)+(q,p)+(q,q)} (BERT는 self-attention을 무진장 추가 할 수 있기 때문)
4. Can we design better pre-training objectives?
당연하다.
이것에는 두 가지 아이디어가 있다.
원래 BERT는 무작위로 15% 를 mask하는데, 이렇게 하지 말고 contiguous spans을 masking한다.
그리고 두개의 end point(start,end)를 이용하여 그 사이에 있는 masked word를 예측한다.
이는 두 endpoints안의 정보를 압축하는 것과 같다.
이를 spanBERT라고 한다.
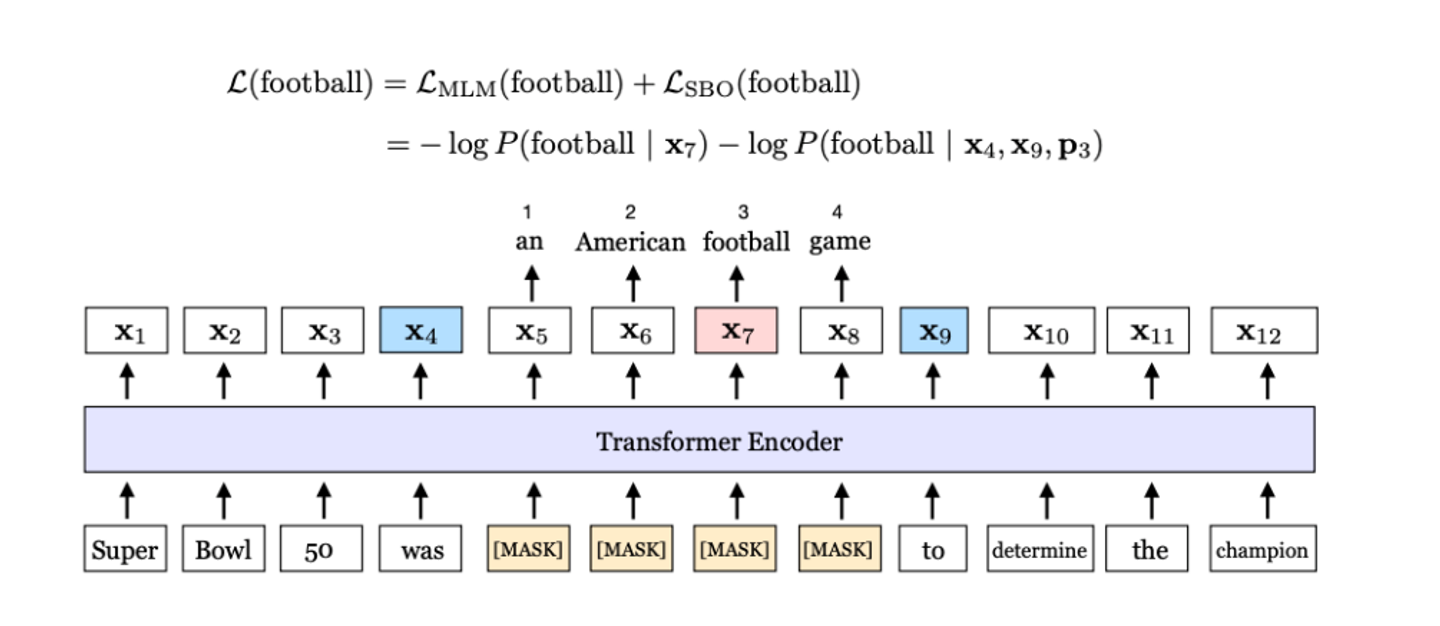
Open-domain question answering
이는 주어진 passage가 없다고 가정한다.
우리는 단지 엄청나게 큰 documents의 collection에 접근할 수 있다. 위키피디아 같은..
주된 아이디어는 바로 1) retrieval 와 2)reader component이다.
retrieval은 question과 관련이 있는 document들을 찾아내는 것이다. 물론 적은 숫자의 document
reader은 그 documents를 모두 읽어서 정확한 답을 찾아내는 것이다.
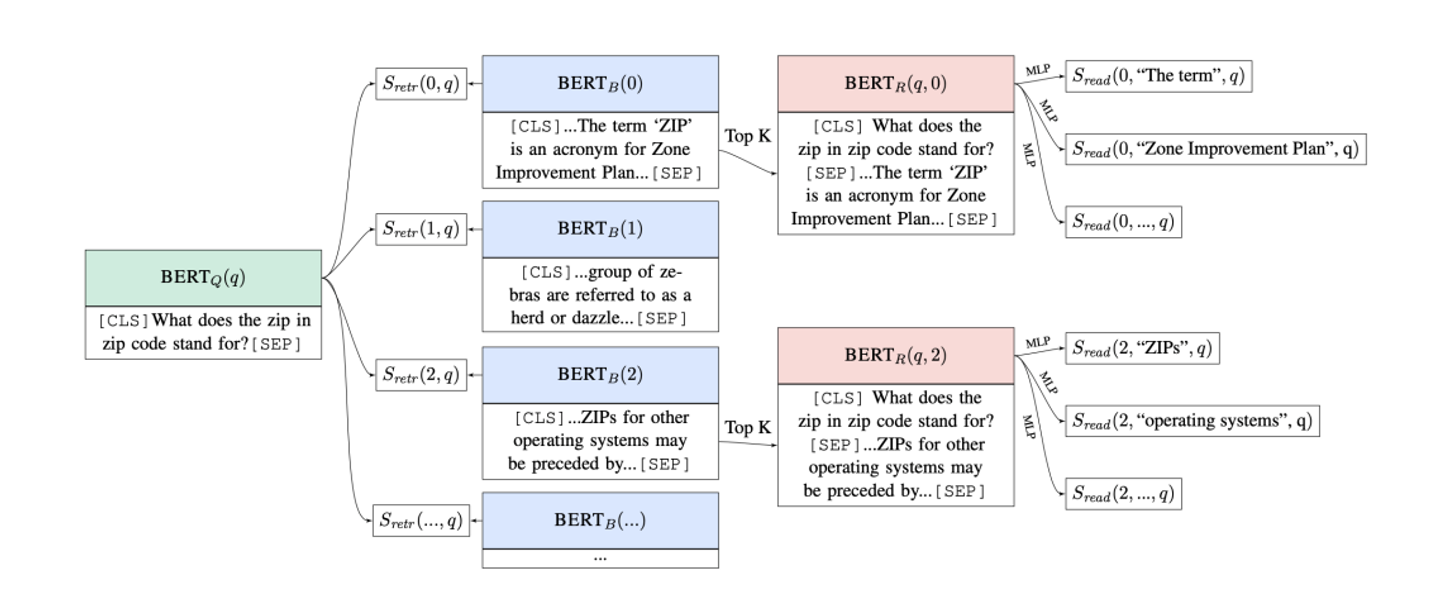
Retriever-reader framework
input은 a large collection of documents 과 이다.
output은 answer string A이다.
Retriever은 에서 documents 후보군 를 도출한다. 여기서 K는 미리 정해놓아야 한다.
Reader은 에서 A를 도출해낸다.
DrQA에서 retriever는 TF-IDF 기반의 information -retrieval sparse model이다.
reader은 앞에서 배운 neural reading comprehension model이다.
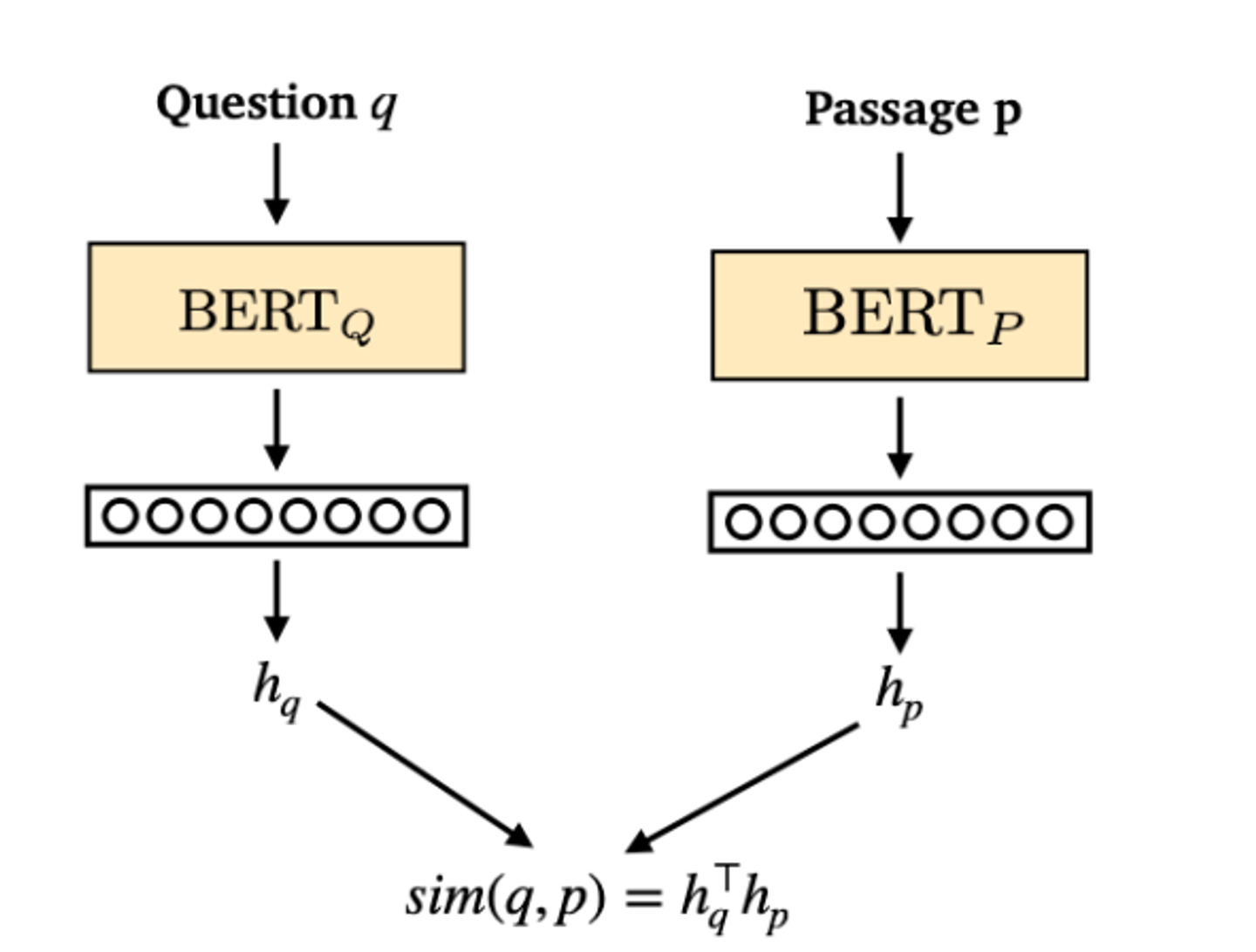
we can train retriever too
BERT를 이용해서 passage와 question을 encoding하고 나서, question과 pasage를 dot product하여 relevance를 모델링한다. (q와 p의 similarity를 구하는 것)
따라서 우리는 BERT를 train하면 되므로, retriever를 train 할 수 있다 ! !
Dense passage retrieval(DPR)이란 것도 있다.
retrieval를 두 개의 BERTmodel와 question과 answer 쌍만을 이용하여 train한다.
Large-language models can do open-domain QA
우리는 심지어 retrieval 단계가 필요하지 않을수도 있다.
당신이 매우 큰 language 모델을 사용한다면 그냥 이것을 쓰면 되는 것이다.
pre-trained language model T5를 가져와서 fine tune 하는 것
question을 input, answer을 output으로 하여..
Maybe the reader model is not necessary too!
그냥 answer space에서 nearest neighbot search를 하면 됨.
위키피디아의 모든 phrase와 질문들을 encode하여 벡터화하고 knn같은거 하면 된다는 소리임.
