이 논문의 주된 관점은 DUS인듯 하다.
DUS는 Depth Up-Scaling의 약자로 깊이 별로 다른 스케일링을 진행한다는 뜻인듯 하다.
2. Depth Up-scaling
2.1 Base Model
n개의 층을 가진 트랜스포머 구조의 모델은 무엇이든지 사용될 수 있지만,
논문에서는 32 layer의 Llama 2 구조를 base model로 사용하였다.
그런다음, Llama 2 구조에서 가장 성능이 좋았다고 밝혀진 Mistral 7B의 사전훈련 가중치로 초기화를 시킨다.
Llama 2 를 사용하여 기존의 좋은 광범위한 성능을 사용하면서, 새로운 수정을 도입하여 더 좋은 성과를 얻고자 한다.
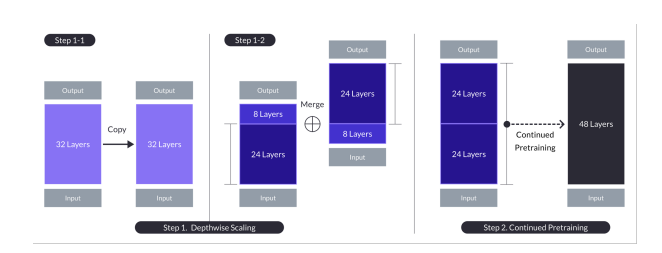
2.2 Depthwise scaling
n개의 층을 가진 base model로 부터, scaled model을 위한 target layer 수 s를 선택한다.
이는 주로 사용가능한 하드웨어에 따라 결정된다.
- n층의 모델을 복제한다.
- 첫번째 모델에서(original)는 마지막 m개의 층을 제거한다.
- 두번째 모델에서(복사본)는 초기의 m개의 층을 제거한다.
-> 각 두개의 모델은 n-m 만큼의 층을 가진다. - 이 두개의 모델들은 concat되고, 이것이 scaled model이 된다. 이 경우 s=2이다.
n=32, s=48, m=8로 설정함.
2.3 Continued pretraining
위의 그림에서 step 2 에 해당한다.
DUS모델의 성능은 초기에 많이 떨어지게 된다. 그렇기 때문에, 우리는 우리는 계속적인 사전훈련 단계를 거쳐야 한다.
경험적으로, 우리는 continued pretraining을 할때, scaled modle의 급속한 성능 향상이 일어나는 것을 보았다.
scaled model을 자세히 살펴보면, 문제는 layer distance에 있다.
n개의 층을 두개로 복사하면 2n개의 층이 되고, layer distance는 n+1이 된다.
근데 이렇게 되면, 두개의 모델 연결부분에서 가장 큰 layer distance가 발생하고, 이는 빠르게 회복되기에는 너무 먼 거리일 수 있다.
그렇기 때문에, Deep wise scaling은 중간의 2m개의 층을 해결함으로써, 연결 부분의 차이를 줄이고 계속된 사전 훈련이 성능을 빠르게 회복하기 쉽도록 만든다.
3. Traning Details
fine-tuning과정은 크게 1. instruction tuning 2. alignment tuning 두가지로 나뉜다.
3.1 Instruction tuning
우리는 모델이 QA format에 맞게 훈련되도록 하였다. 대부분이 오픈소스 데이터에지만 math QA도 추가하였다.
3.2 Alignment tuning
instruction-tuned 모델이 더 강해지기 위해 추가적으로 튜닝된다.
이에 DPO (direct preference optimization)을 사용했다.
이에도 우리는 오픈소스 데이터를 대부분 사용했지만, 합성된 math 데이터도 사용하였다.
우리는 재구성된 질문을 프롬프트로 설정하고, 재구성된 답변을 선택된 응답으로, 원래 답변을 거부된 응답으로 설정하여 {프롬프트, 선택된, 거부된} DPO 튜플을 만듭니다.
