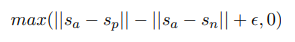기존 BERT에 poolying layer 을 추가한 간단한 논문이다.
빨리 해치워보자.
1. Introduction
간단하다. BERT 임베딩을 하고 나서 이 표현을 어떻게 사용할지에는 2-3가지정도의 방법이 있다.
BERT output layer을 평균내는 것이나([CLS] 토큰) 첫번째 토큰의 출력을 사용하는 것이다.
하지만, 이 방법은 종종 좋지 않은 임베딩을 생성하여 GloVe 임베딩을 평균하는것 보다 나쁠 수도 있다.
이 문제를 해결하기 위해 개발된 것이 SBERT 이다.
입력 문장의 고정 크기 벡터를 도출하게 해준다.
3. model
SBERT는 BErT/RoBERTa의 출력에 pooling 연산을 추가하여 고정 크기의 문장 임베딩을 얻는다.
pooling 전략으로는 3가지가 있다.
(1) CLS 토큰의 출력을 사용하는 방법
(2) 모든 출력 벡터의 평균을 계산하는 mean 전략
(3) 출력 벡터의 max-over-time 을 계산하는 MAX 전략
-> 이 논문의 default은 mean 이다.
사용하는 구조와 object functions을 사용한다.
- classification objection function
우리는 문장 임베딩 와 와 element-wise-difference 를 concat하고,
이를 학습 가능한 가중치 와 곱한다.
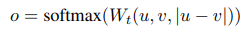
여기서 n은 문장 임베딩의 공간차원이고, k는 라벨의 개수이다.
cross-entropy loss를 최적화한다.
구조는 다음과 같다.
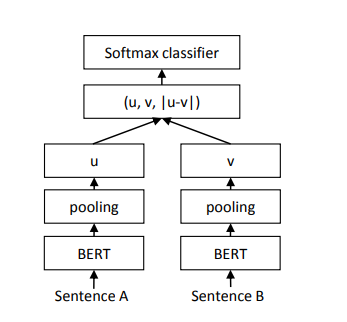
-
Regression Objective Function
두 문장 임베딩 과 의 코사인 유사도가 계산된다. object function으로 mse를 사용한다.
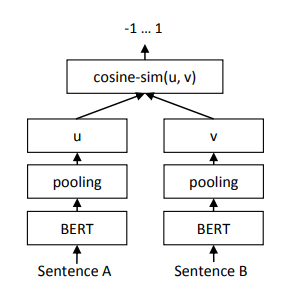
-
Triplet Objective Function
주어진 기준 문장 a, 긍정적인 문장 p, 부정적인 문장 n에 대해 triplet loss는 네트워크를 조정하여 a와 p간의 거리가 a와 n간의 거리보다 작아지도록 하는 손실함수를 최소화한다.