논문
1.[논문리뷰]REPLUG: Retrieval-Augmented Black-Box Language Models
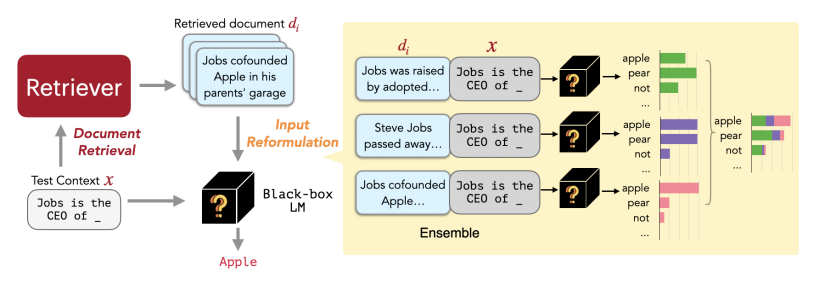
접근방식과 훈련 방식부분만 정리해보겠다. 간단하게 replug모델은 retrieval을 강황한 언어 모델 패러다임으로 , 언어 모델을 블랙 박스로 취급하고 검색 구성 요소를 조정 가능한 모듈로 추가하는 방식이다. 위 사진이 이 논문 모델 구조의 전체적인 패러다임이다.
2.[논문 리뷰]: A Survey of Vision-Language Pre-Trained Models

VL-PTMs는 대규모 이미지-텍스트 말뭉치에서 사전 훈련함으로써 모든 방향에서 얻어진 표현을 학습할 수 있다. 이는 하위 V-L 테스트에서 강력한 성능을 달성하는 데 도움이 된다. 예를 들어 LXMERT는 이중 스트림 퓨전 인코더를 사용하여 V-L 표현을 학습하며,
3.[논문리뷰]R-CNN, Fast R-CNN, Faster R-CNN
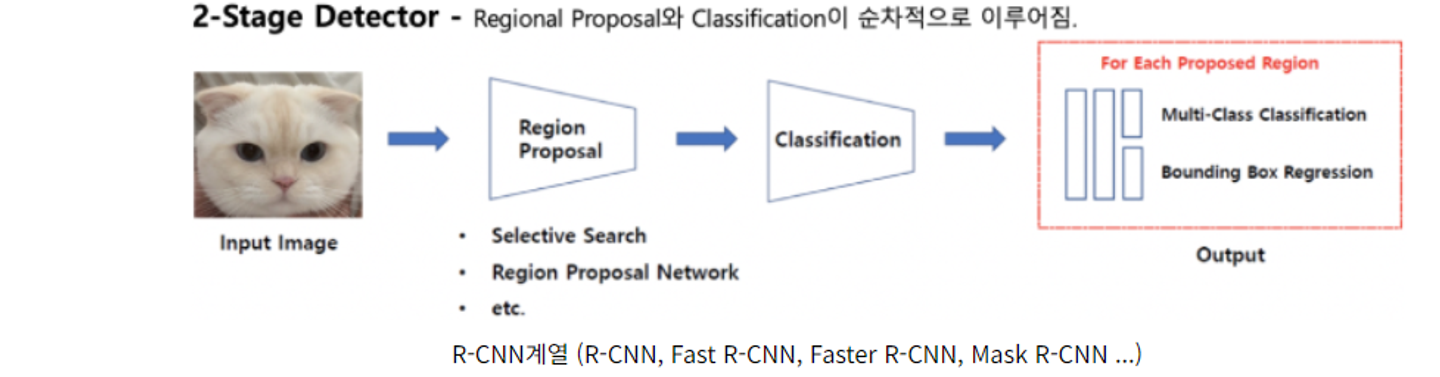
논문 제목이 faster로 시작한다. 더 빠른, 즉 성능을 향상시켰다는 말이다. 그렇다면 그 이전의 덜 빠른 모델, 그리고 빠르지도 않은 원형 모델이 존재할 것이다. R-CNN과 fast R-CNN에 대해 정리한 뒤, 이를 보완한 faster R-CNN에 대해서 알아보
4.[논문리뷰]Oscar : Object-Semantics Aligned Pre-training for Vision-Language Tasks

최근 나오는 V+L 모델들은 다층 transformer를 기반으로 한다. 이러한 모델을 사전 훈련하기 위한 기존 방법은 이미지 영역 특징과 텍스트 특징을 간단히 연결하고, self-attention mechanism 을 사용하여 이미지 영역과 텍스트 간의 의미적인 정렬
5.[논문리뷰] Text generation from knowledge Graphs with Graph Transformers
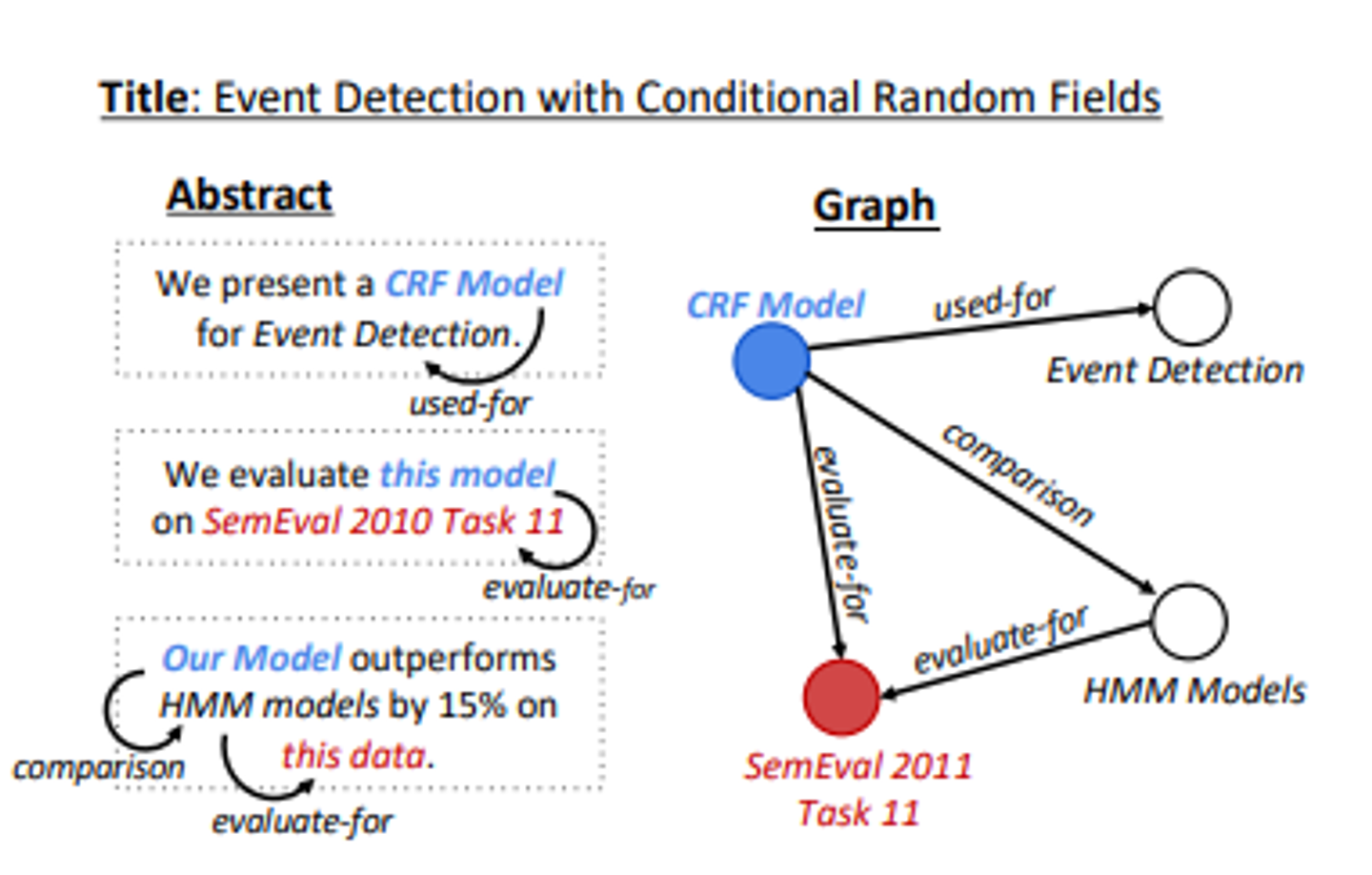
특정 주제와 관련이 있는 여러문장을 생성하고, 그 문장들이 전체적으로 일관성있고 담화적인 관련성을 갖추는 것은 여전히 도전과제이다.특히, 과학적 글쓰기에서 복잡 > 가능한 주제의 다양성이 매우 큼과학적 커뮤니케이션은 프로세스와 현상에 대한 정확하게 구성된 설명을 필요로
6.[논문리뷰]Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents
인간과 유사한 챗봇을 만들기 -> 대화속에 내포된 암묵적인 정보를 효과적으로 이해 -> 상식적인 추론을 사용해야 함하지만 이런 한가지 연결에서의 핵심 증거를 식별하고 통합하는 작업은 상당히 어려움why?\-> 대화에서의 상식적 추론은 multi-hop reasoning
7.[논문리뷰]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
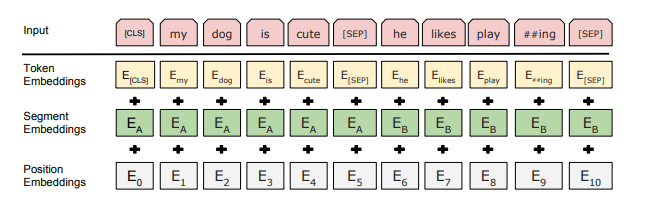
맨날 BERT쓰면서 생각해보니까 BERT 찐 논문을 한번도 안읽어본거 같아서 읽어보는 BERT..드루와 BERT의 가장 큰 문제는 인코더만 사용하기 때문에 단방향석이라는 점. 따라서 BERT는 "마스킹된 언어 모델"MLM을 사전 훈련 object function으로
8.[논문리뷰] Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring
항상 코딩하고 부랴부랴 다시 논문 리뷰하는 나란 녀석..하지만 논문 다 제대로 읽고 코딩까지 하기엔 시간이 없는걸 어케ㅠㅠ ㅠ논문 순서가 정말 뒤죽박죽이지만.. 일단 업로드만 하자 (논문 인트로 특 : 자랑) poly-encoder 라는 구조를 소개하는데, 이는 학습된
9.[논문리뷰]Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
기존 BERT에 poolying layer 을 추가한 간단한 논문이다. 빨리 해치워보자. 간단하다. BERT 임베딩을 하고 나서 이 표현을 어떻게 사용할지에는 2-3가지정도의 방법이 있다.BERT output layer을 평균내는 것이나(CLS 토큰) 첫번째 토큰의 출
10.SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
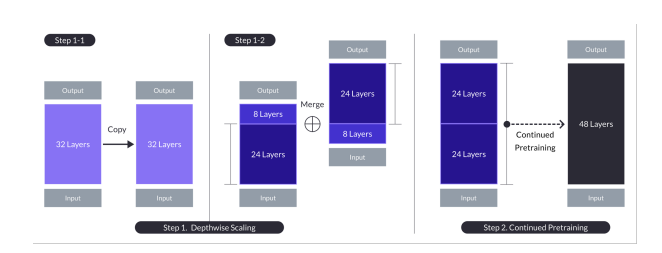
이 논문의 주된 관점은 DUS인듯 하다. DUS는 Depth Up-Scaling의 약자로 깊이 별로 다른 스케일링을 진행한다는 뜻인듯 하다. n개의 층을 가진 트랜스포머 구조의 모델은 무엇이든지 사용될 수 있지만,논문에서는 32 layer의 Llama 2 구조를 bas
11.[논문리뷰]clip: Learning Transferable Visual Models From Natural Language Supervision
논문 길이가 50장이 된다고 하여.. 여러 정리와 블로그를 읽고 정리하는 것으로 ... 본 논문에서는 4억개의 이미지 + 텍스트(caption) 쌍으로 대규모 학습한 모델로, 자연어 supervision을 사용하여 학습하였다. 그리고 많은 vision task에서 굉
12.[논문리뷰]HOTPOTQA:ADataset for Diverse, Explainable Multi-hop Question Answering

질문응답(QA) 작업은 지능 시스템의 추론 능력을 테스트하기 위한 측정가능하고 객관적인 방법을 제공한다. 이를 위해서 몇가지 대규모 QA 데이터셋이 제안되었지만, 이에는 추론 학습을 발전시키는데 제한이 있다. \-> 특히 QA 시스템이 다중 문맥에서 추론을 수행하는 능
13.[논문리뷰]Reflexion : Language Agents with Verbal Reinforcement Learning
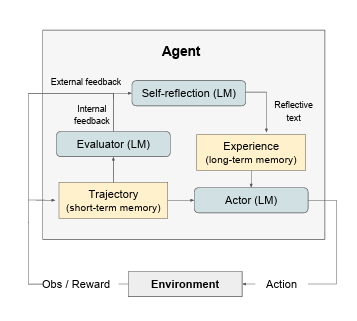
ReAct 30, SayCan 1, Toolformer 22, HuggingGPT 23, generative agents 19, 그리고 WebGPT 17와 같은 최근 연구들은 대규모 언어 모델(LLM) 코어 위에 구축된 자율 의사 결정 에이전트(feasibility o
14.[논문리뷰] VisionMamba : EfficientVisualRepresentationLearningwithBidirectional StateSpaceModel

최근 작업인 Mamba는 SSM에 시간 변동 매개변수를 통합하고 매우 효율적인 훈련 및 추로늘 가능하게 하는 하드웨어에 대한 인식 알고리즘을 제안한다. 이는 Transformers의 유망한 대안이다. 하지만 시각데이터를 처리하기 위한 일반적인 순수 SSM 기반 back