논문 길이가 50장이 된다고 하여.. 여러 정리와 블로그를 읽고 정리하는 것으로 ...
본 논문에서는 4억개의 이미지 + 텍스트(caption) 쌍으로 대규모 학습한 모델로, 자연어 supervision을 사용하여 학습하였다. 그리고 많은 vision task에서 굉장히 좋은 결과를 얻었다.
2. Approach
2.1 Natural Language Supervision
CLIP은 자연어를 supervision으로 학습한다. 이는 기존의 많은 image dataset과 달리 별도의 번거로운 labeling 작업이 필요 없다는 강력한 장점을 가지고 있다.
또한, 이미지에 더해 자연어까지 representation learning을 수행할 수 있고, 다른 종류의 task로도 유연하게 zero-shot transfer 이 가능하다.
*자연어로 학습 제어 및 가이드 ex) 명령
2.2 creating a sufficiently large dataset
- 기존의 MS-COCO, visual Genome은 품질은 좋으나 그 양이 매우 적다.
- YFCC100M은 매우 큰 데이터셋이지만, 그 품질이 들쑥날쑥함.
CLIP은 WIT(WebImage Text)라고 명명하는 새로운 데이터셋을 만들었다.
이는 인터넷의 다양한 사이트에서 가져온 4억개의 (image,text)쌍으로 구성되어 있다.
2.3 Selecting and Effieicnt pre-training Method
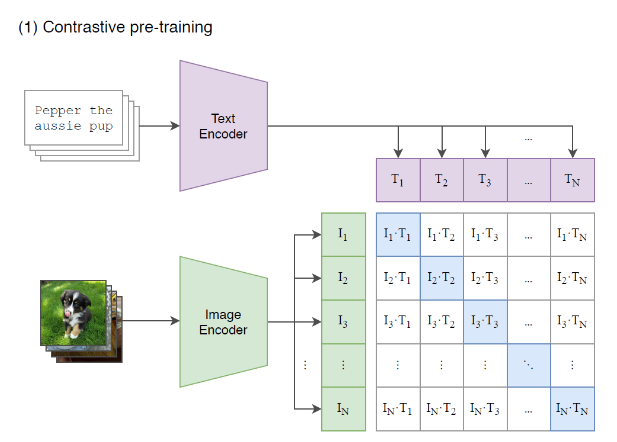
1개의 batch은 N개의 (image, text) 쌍으로 구성된다. 그러면, N개의 쌍을 모든 i,j에 대해서 비교하면 N개의 positive pair과 개의 negative pair을 얻을 수 있다.
그리고
1. image와 text를 하나의 공통된 space로 보낸 다음
2. positive pair에서의 유사도(cosine similarity)는 최대화하고
3. negative pair에서의 유사도는 최소화하도록
4. CE loss를 사용하여 학습한다.
이와 같은 과정을 통해 CLPI은 multi-modal embedding space를 학습하게 된다.
아래 그림에서 파란색 부분이 이미지-해당 이미지와 연관된 텍스트 로 구성된 positive pair이다.

2.4 Choosing and scaling model
image encoder로는 2개를 고려해다.
1. ResNet-50 에서 약간 수정된 버전인 ResNet-D 버전을 사용한다. Global Average Pooling을 Attention Pooling으로 대체하였다.
2. ViT도 사용한다. Layer Norm 추가 외에는 별다른 수정이 없다.
text encoder로는 Transformer을 사용함. max_length = 76
3. Experiments
3.1 Zero-Shot Transfer
3.1.2 Using CLIP for zero-shot transfer
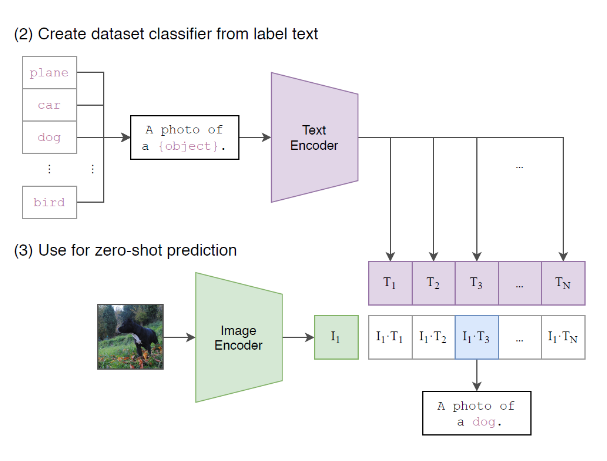
이미지 분류 task의 경우, 이미지가 주어지면 데이터셋의 모든 class와의 (image,text)쌍에 대해 유사도를 측정하고 가장 그럴듯한 쌍을 출력한다.
아래 그림처럼, 각 class name을 "A Photo of {class}" 형식의 문장으로 바꾼 뒤, 주어진 이미지와 유사도를 모든 class에 대해 측정하는 방식이다.
3.1.3 Initial comparison to visual n-grams
이미지 분류 문제에서 Visual N-grams 방식보다 실험한 3개의 데이터셋 모두에서 zero-shot 성능이 훨씬 뛰어나다.
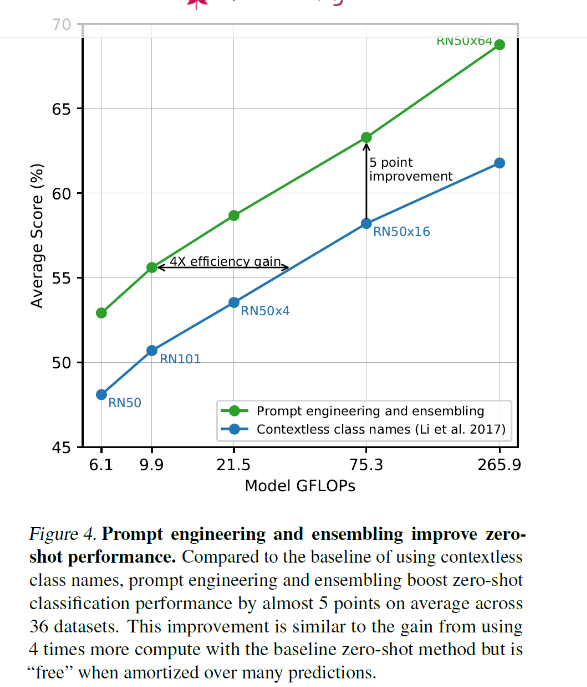
3.1.4 Prompt engineering and ensembling
class이름을 그냥 사용하는 것이 아니라 'a photo of a {class}'형식의 문장을 만들어 유사도를 측정했다. 하지만 이 프롬트는 적절히 선택해주면 분류에 더 도움이 된다.
예를 들어,
"A photo of a {label}, a type of pet."
"a satellite photo of a {label}."
"A photo of big {label}"
"A photo of small {label}"
와 같이 바꾸면 분류를 더 잘할 수 있다.
3.2 Representation Learning
image의 특성을 최대한 잘 설명하는 어떤 feature을 잘 뽑아 이를 다른 downstream task에 활용하겠다는 것. CLIP의 성능이 꽤나 좋음
모델의 representation learning 성능은 뽑아진 representation을 선형 모델에 넣은 성능으로 평가하며, CLIP 논문에서도 이와 같은 방법을 사요함.
학습시킬 때는, 텍스트 n차원 인코딩, 이미지 n차원 인코딩 후 positive pair 잘 맞추도록 constrative learning.
사용할 때는, 텍스트를 pormpt engineering 해서 인코딩 넣은 다음, 이미지 인코딩한 값과 매칭했을 때, positive 쌍 찾도록 하기(Zero-shot)
