Introduction
- 특정 주제와 관련이 있는 여러문장을 생성하고, 그 문장들이 전체적으로 일관성있고 담화적인 관련성을 갖추는 것은 여전히 도전과제이다.
- 특히, 과학적 글쓰기에서 복잡 > 가능한 주제의 다양성이 매우 큼
- 과학적 커뮤니케이션은 프로세스와 현상에 대한 정확하게 구성된 설명을 필요로 하기 때문에 문서 구조에 강력한 제약 사항이 있음
- 이를 해결하기 위해 > 구조화된 입력을 다루는 방식을 적용 ex) 테이블 구조화된 입력에 의존. 좋지만, 제한된 도메인에서만 사용 가능
- 현재의 연구는 정보추출(IE)시스템을 사용하여 긴 텍스트 생성에 대한 맥락을 자동으로 제공하는 가능성을 탐구함. 견고한 IE시스템은 다양한 텍스트 도메인에서 지원되며 종종 단일 문장의 범위를 넘어선 관계에 대한 풍부한 annotation을 제공한다.
- 본 연구에서는 과학기사의 추상문에서 추출한 데이터 사용.
- 최신정보추출 시스템(Luan et al., 2018)을 사용하여 각 추상문에 대한 entity, coreference, relation 어노테이션을 추출하고, 어노 테이션을 공유 참조 개체를 축소시키는 지식 그래프로 표현함.
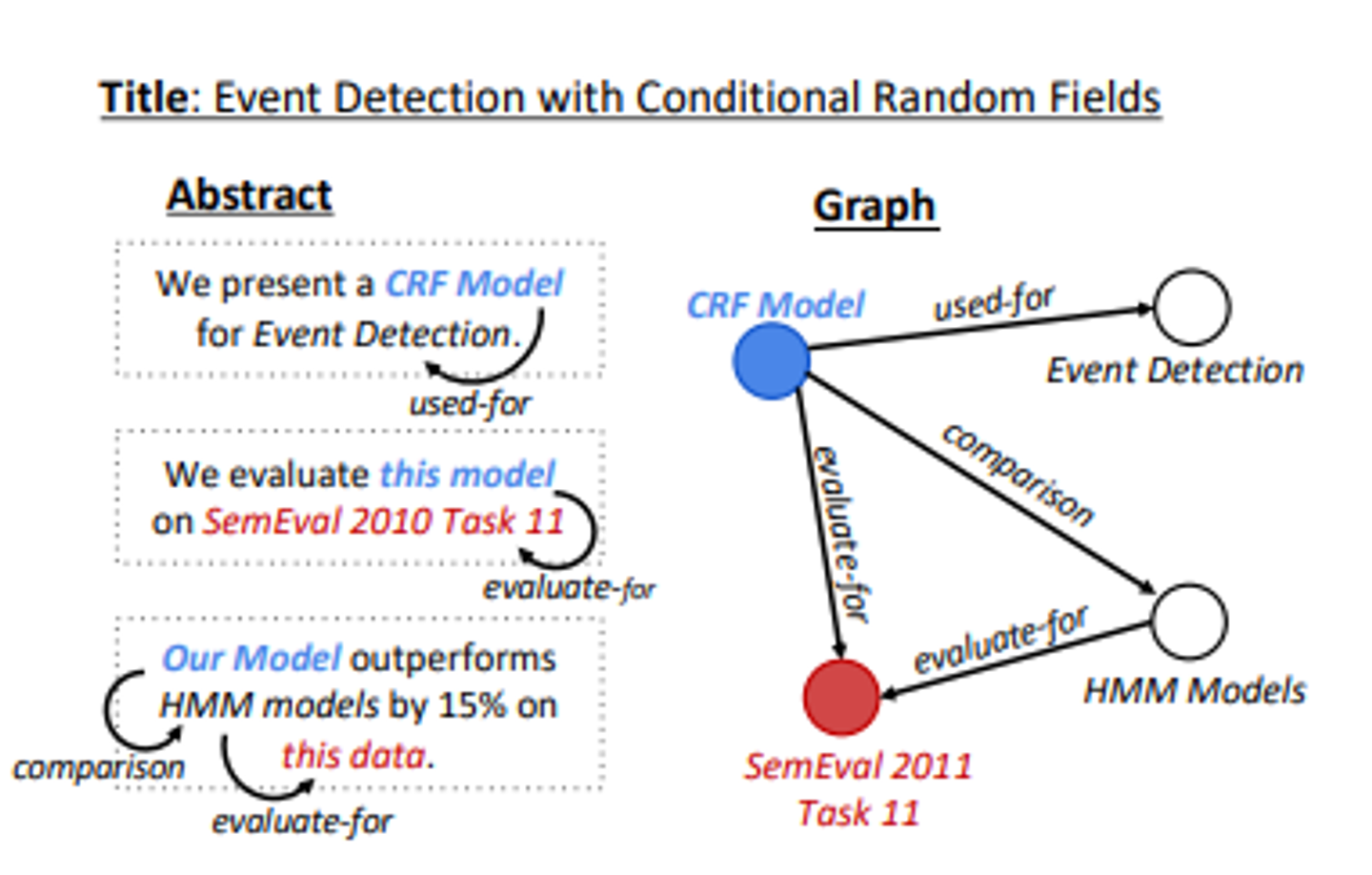
- 위와같은 텍스트-그래프 쌍을 사용하여 지식 그래프에서 텍스트를 생성하기 위한 attention기반 인코더 디코더 모델인 GraphWriter을 훈련시킨다.
- 본 연구의 모델은 텍스트 인코딩을 위해 성공적인 Transformer를 그래프 구조화된 입력에 확장하며, 최근의 Graph Attntion Network아키텍처에 기반한다.
- 결과, 지역 이웃에서 정점을 문맥화하는 동안 전역 구조적 정보를 포함할 수 있는 강력한 그래프 인코딩 모델이 만들어진다.
- 다음은 주요 기여
(-) 성공적인 시퀀스 Transformer를 그래프 구조화된 입력에 적용하는 새로운 그래프 Transformer 인코더를 제안
(2) attention기반 인코더에서 사용하기 위해 연결된 무라벨 그래프 형태로 IE출력을 형성하는 방법
(3) 과학텍스트와 짝지어진 지식 그래프의 대규모 데이터
The AGENDA Dataset
해결해야 하는 문제는 자동으로 추출된 정보(지식)로부터 텍스트를 생성하는 문제이다.
정보 추출 시스템은 문장 및 문서의 경계를 넘어서서 다양한 도메인에 대한 고품질 지식을 생성할 수 있다.
지식으로부터 일관된 텍스트를 생성하기 위해서는 지식의 전역적인 특성과 각 개체의 지역적인 특성을 모두 고려하는 모델이 필요함.
이 작업의 특징은 지식을 표현하기 위해 그래프를 사용하는 데에서 나온다.
그래프는 인접한 노드들이 중요한 정보를 지역화하고, 그래프를 통한 경로는 중간 노드를 통해 먼 노드를 통해 먼 노드들 간의 연결을 형성한다.
💡 문제정의 : 과학 논문의 제목과 자동 정보 추출 시스템에 의해 생성된 지식 그래프가 주어졌을때, 목표는 주어진 제목에 적합한 추상문을 생성하고, 지식 그래프의 내용을 자언어 텍스트로 표현하는 것이다.모델이 이 목표를 얼마나 잘 달성하는지 평가하기 위해, Abstract Generation Dataset(AGENDA)를 도입한다.
AGENDA는 지식 그래프와 과학적인 추상문의 데이터셋이다.
12개의 주요 인공지능 학회의 논문 제목과 초록에서 추출된 40,000개의 샘플로 구성되어 있으며, Semantic Scholar Corpus에서 가져온 것 (Ammar et al., 2018).
각 추상문에 대해, 우리는 두 단계로 지식 그래프를 생성함.
(1) Luan et al .(2018)의 ScilE 시스템을 적용함.
- 이 시스템은 최신의 과학 도메인 정보 추출 시스템으로, 과학 용어에 명명된 개체 인식과 개체 유형(Task, Method, Metirc, Material 또는 Other Scientific Term)을 제공한다.
- 이 모델은 공동 참조 주석 및 서로 다른 개체 간에 발생할 수 있는 일곱 가지 관계(Compare, Used-for, Feature-of, Hyponym-of, Evaluate-for 및 conjunction)도 생성함.
- 아래 그림에서 SemEval2011Task11이라고 표시된 노드는 Task유형이고, HMM Models는 Model유형이며, Evaluate-For 관계가 모델이 작업에 대해 평가된다는 것을 타나냄
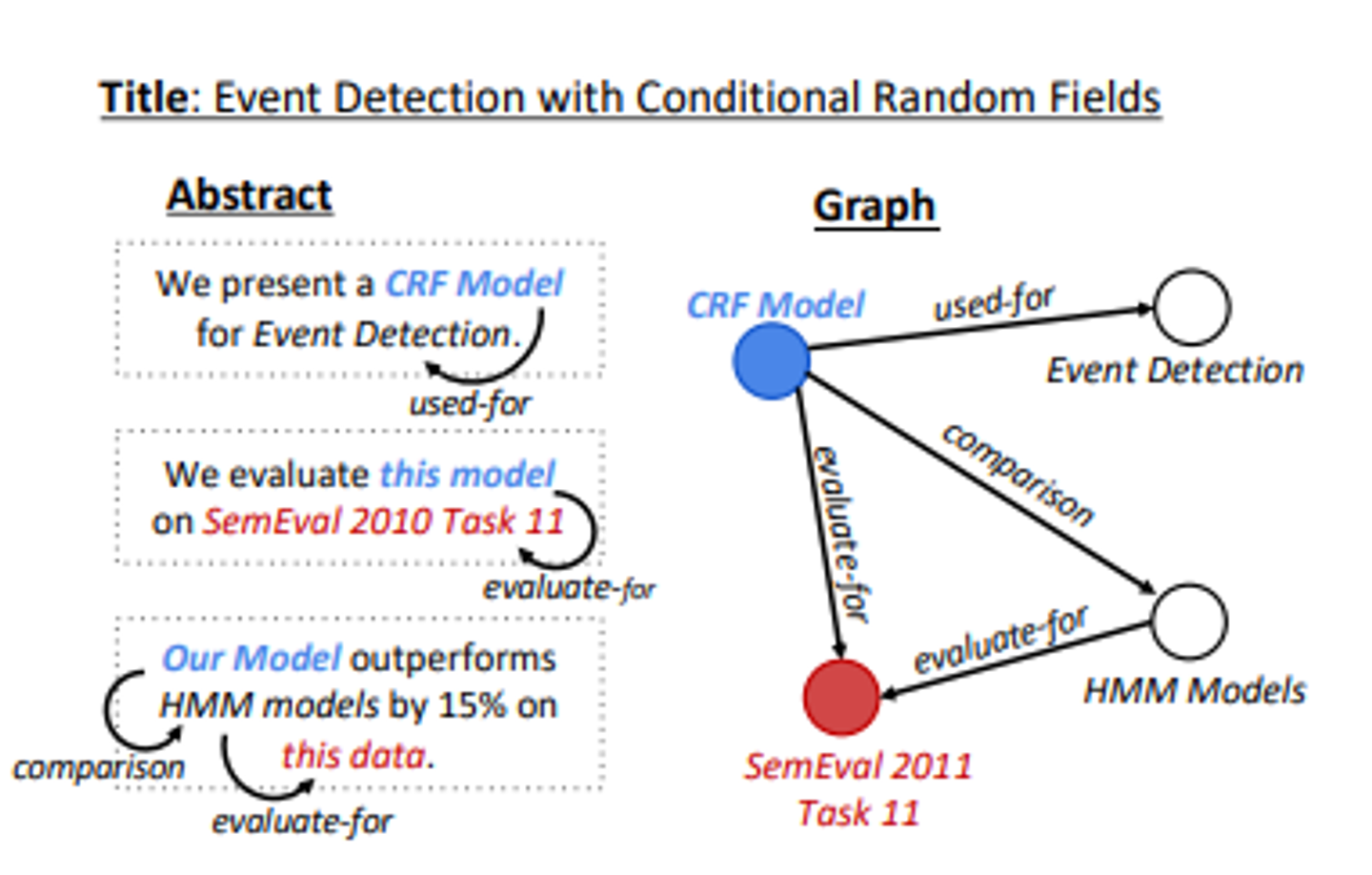
(2) 이러한 주석들은 지식 그래프로 구성한다.
- 공동 참조 개체를 가장 긴 언급과 관련된 단일노드로 축소한다. (가장 정보가 풍부할 것으로 가정)
- 그런 다음 관계 주석을 사용하여 노드를 서로 연결하고, 이를 그래프의 레이블이 지정된 엣지로 처리한다.
- 이 결과는 주어진 추상문에 대해 ScilE 주석의 연결되지 않을 수 있는 그래프 표현이다.
AGEDA 데이터셋의 통계는 다음과 같음
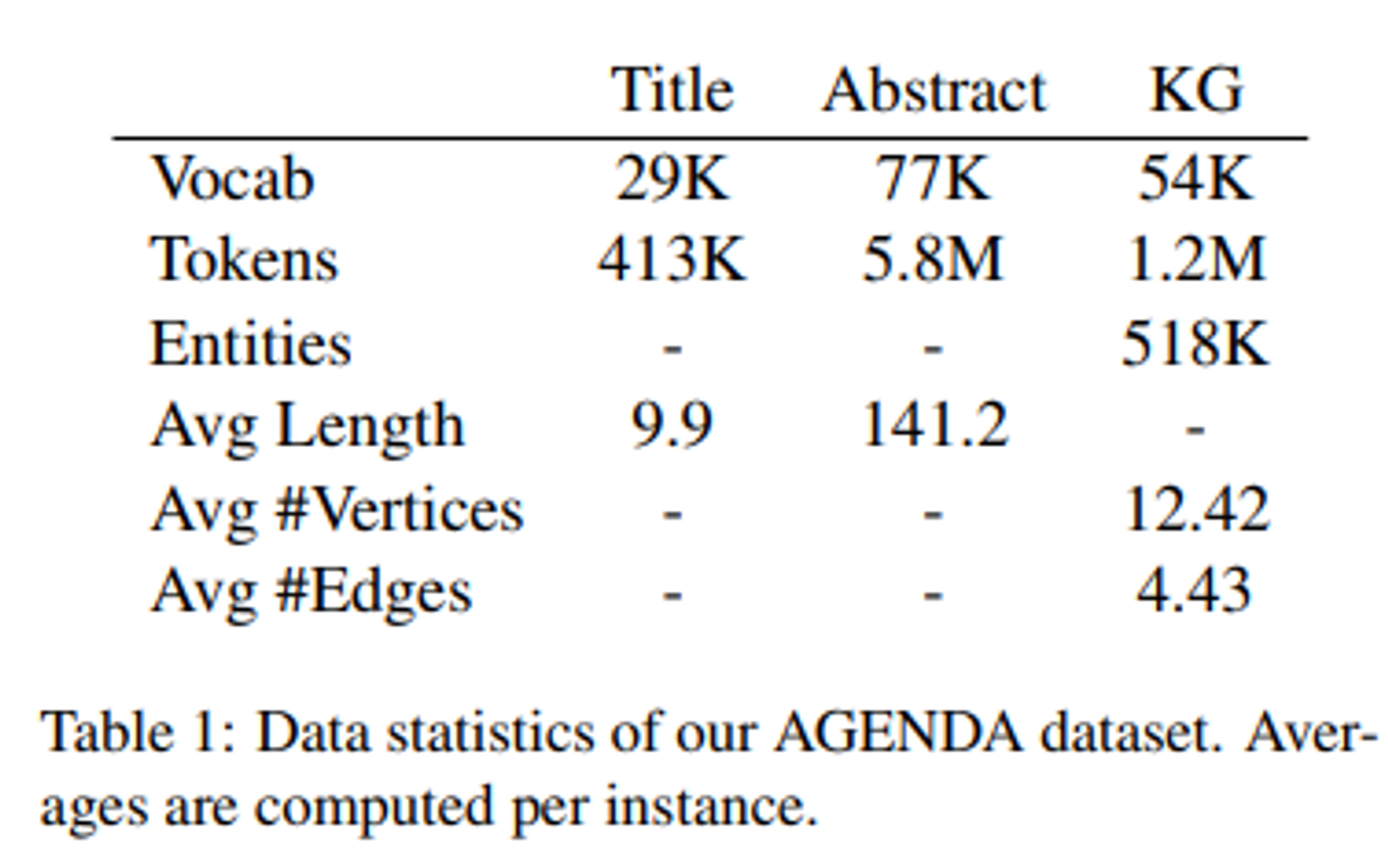
AGENDA데이터셋을 38,720개의 학습 데이터, 1000개의 검증 데이터 및 1000개의 테스트 데이터로 분할한다.
Model
대부분의 neural generation과정을 따라, 아래 그림에 나와있는 Encoder-Decoder 아키텍처인 GraphWriter를 채택한다.
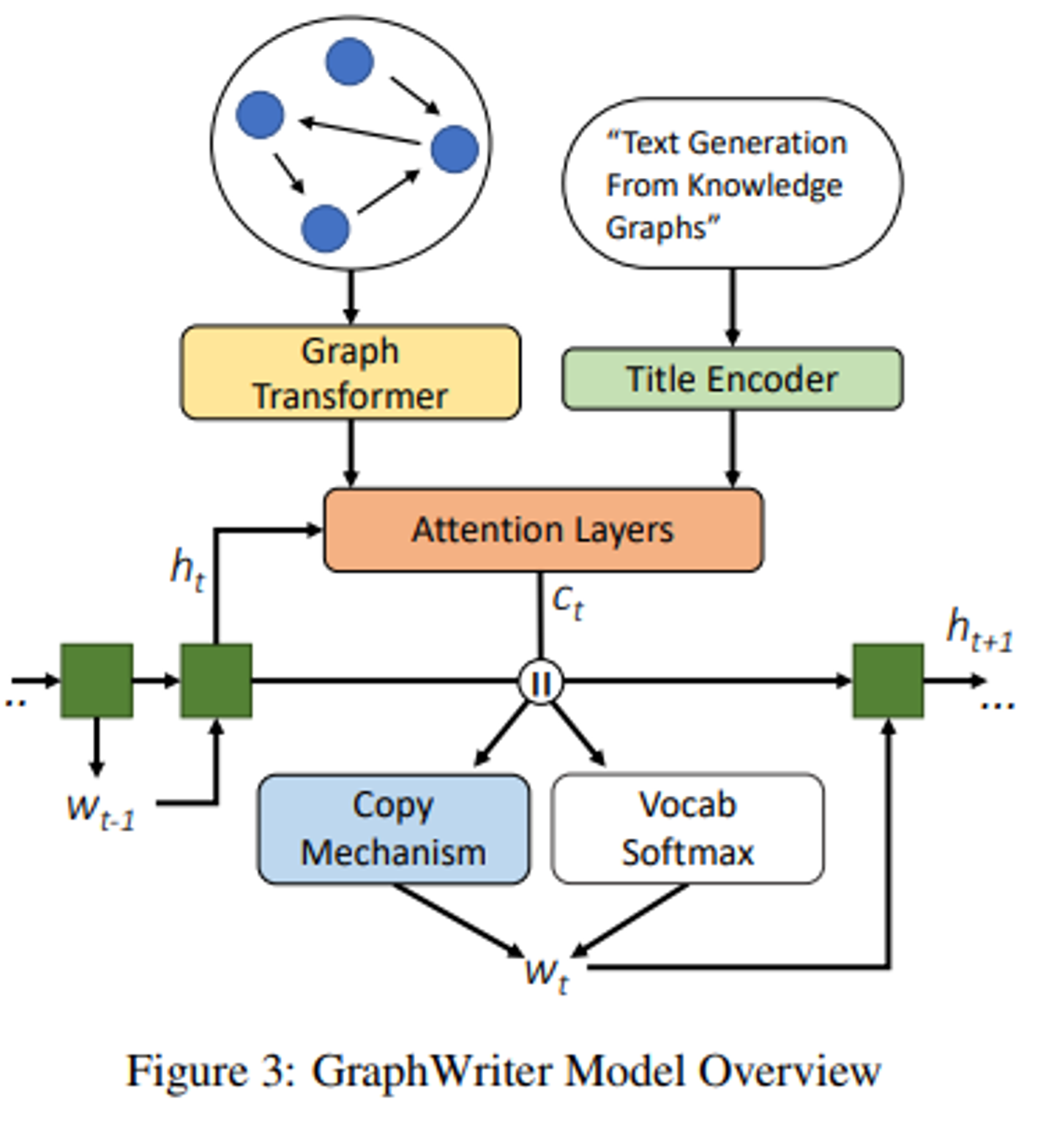
GraphWirter의 입력은 제목과 지식 그래프로 구성된다.
각각 양방향 순환 신경망과 새로운 그래프 변환기 아키텍처(4.1)로 인코딩됨.
각 디코더 시간 단계에서는 디코더의 은닉 상태 를 사용하여 지식 그래프와 문서 제목의 인코딩에 어텐션을 적용한다.
이를 통해 생성된 벡터는 디코더의 어휘 또는 지식 그래프에서 개체를 복사하여 출력 w_t를 선택하는데 사용됨.
디코딩 프로세스의 자세한 프로세스는 4.2
이 모델은 혼합 복사 및 어휘 확률 분포와 인간이 작성한 텍스트의 음의 로그 우도를 최소화하기 위해 end-to-end로 훈련된다.
Encoder
- AGENDA데이터셋은 각 데이터 포인트에 대한 지식 그래프를 포함하고 있지만, 우리 모델은 라벨이 없는 연결된 그래프를 입력으로 필요한다.
- 따라서, 이 모델을 사용하여 지식 그래프를 인코딩하기 위해, 아래 그림에 스케치된 방법을 사용한다. > 각 그래프를 라벨이 없는 연결된 이분 그래프로 재구성한다.
![attention기반 인코더에서 사용하기 위해 연결되지 않은 라벨이 있는 그래프로 변환하는 과정. Vi는 정점을 나타내고, Rij는 관계를 나타내고, G는 전역 컨텍스트 노드. ]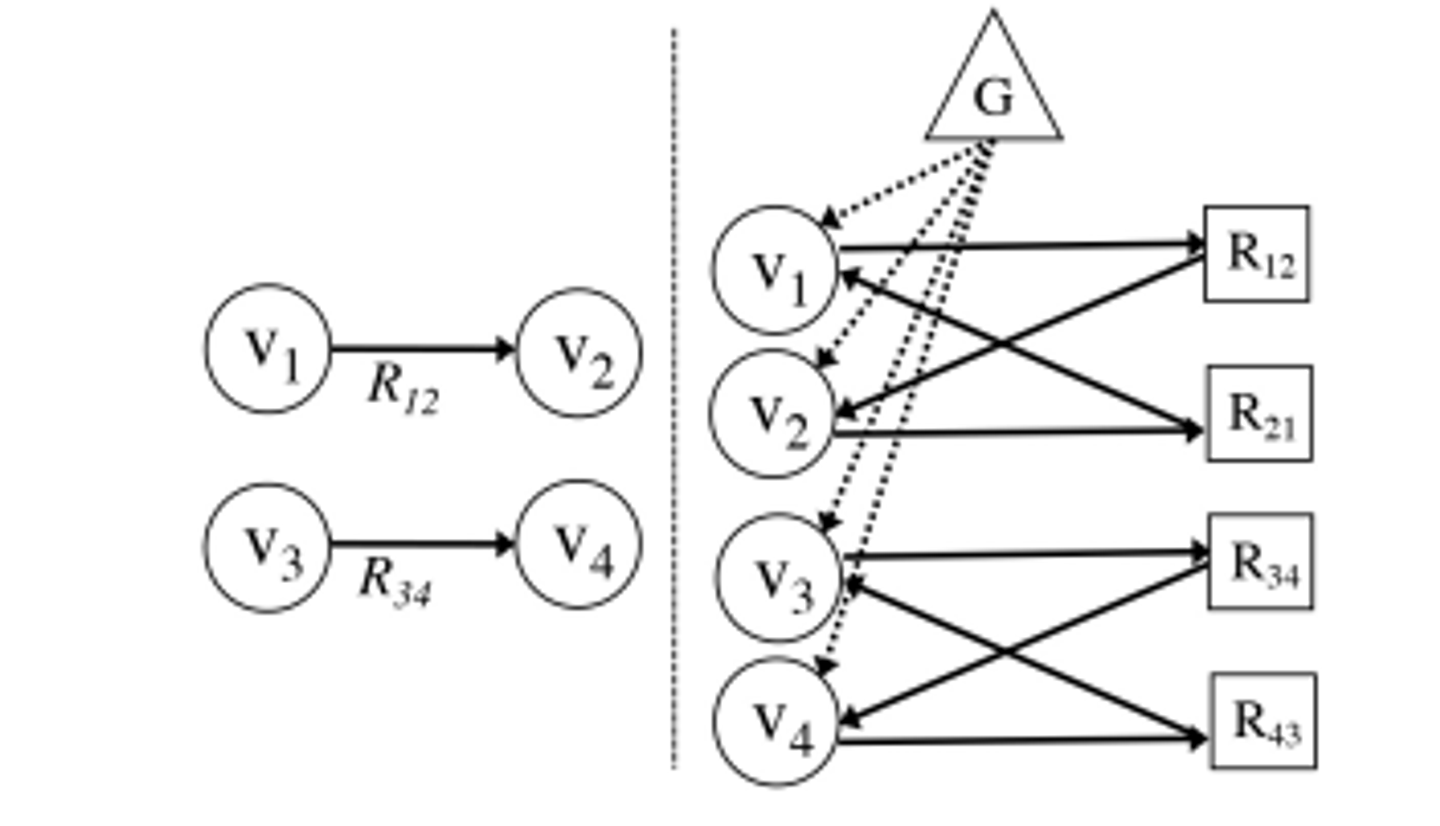
attention기반 인코더에서 사용하기 위해 연결되지 않은 라벨이 있는 그래프로 변환하는 과정. Vi는 정점을 나타내고, Rij는 관계를 나타내고, G는 전역 컨텍스트 노드.
Graph Preparation
- 각 그래프를 라벨이 없는 연결된 이분 그래프로 변환해야한다.
- 이 과정에서 각 라벨이 있는 엣지는 두 개의 정점으로 대체된다.
- 하나는 관계의 정방향을 나타내고, 다른 하나는 역방향을 나타낸다.
- 이 새로운 정점들은 그래프의 엔티티 정점들과 연결되어 원래 엣지의 방향성을 유지한다.
- 이렇게 하면 원래 지식 그래프가 라벨이 없는 방향 그래프로 재구성되며, ScilE주석에서의 모든 정점이 엔티티와 관계에 해당하면서도 정보의 손실 없이 표현된다.
- 그래프가 분리된 부분 간의 정보 흐름을 촉진하기 위해, 모든 엔티티 정점과 연결된 전역 정점을 추가한다.
- 이 전역 정점은 디코더를 초기화하는데 사용될 것이며, 기존의 sequence - to-sequence모델에서 최종 인코더가 숨겨진 상태에 해당한다.
- 이 재구성 작업의 최종 결과는 연결된 라벨이 없는 그래프 G=(V,E)이다. V는 엔티티, 관계 및 전역 노드의 목록이고, E는 방향성을 나타내는 인접 행렬이다.
Graph Transformer
- 이 모델은 Velicković 등의 Graph Attention Network (GAT, 2018) 과 가장 유사하다.
- GAT는 self-attention전략을 따라 이웃들에게 주목하여 그래프의 각 노드의 숨겨진 표현을 계산한다.
- GAT는 그래프 컨벌루션을 기반으로 한 이전 방법들의 단점을 해결하기 위해서 self-attention을 사용하지만, 정점 업데이트는 인접 노드로부터의 정보에 한정된다.
- 저희 모델은 Transformer스타일의 아키텍처를 사용하여 각 정점의 더 전역적인 문맥화(global contextualization)을 가능하게 한다.
- 최근 제안된 트랜스포머는 순환 신경망의 내재적인 순차 계산 단점을 해결하여 self-attention mechanism을 통해 효율적이고 병렬화된 계산을 가능하게 한다.
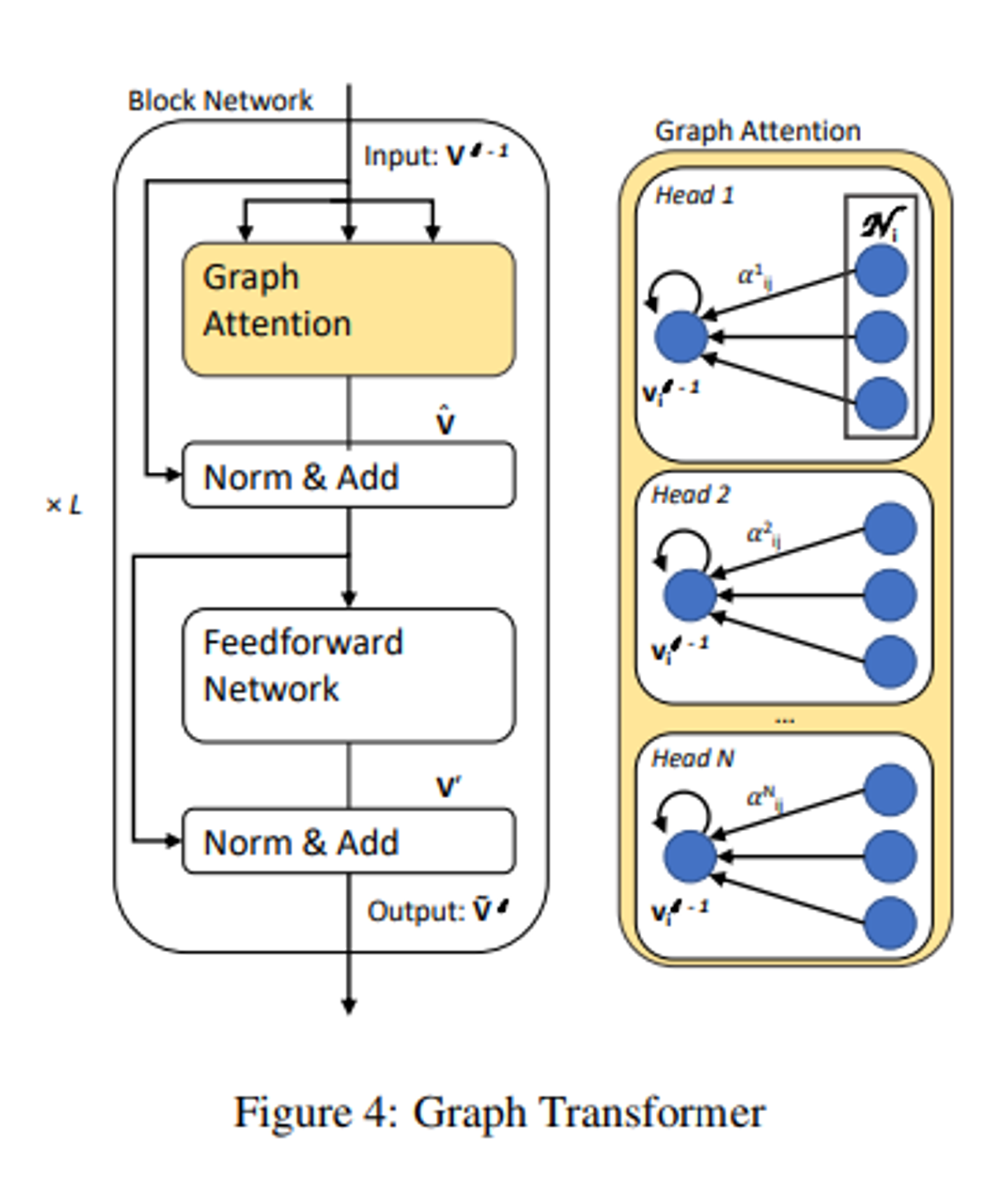
- 저희의 그래프 트랜스포머 인코더는 정점의 지역 이웃들에 대한 self attention으로 시작한다.
- GAT와 주요 차이점은 저희 모델이 전역 문맥을 포착하기 위해 추가적인 매커니즘을 포함한다는 점이다.
- 이러한 추가적인 모델링 기능은 그래프 트랜스포머가 주변 이웃의 내용을 고려하여 정점을 어떻게 업데이트해야 하는지, 모델의 목표에 관련된 그래프 구조의 전역적인 패턴을 학습하는데 도움이 된다.
- 구체적으로 V는 이 섹션 맨 끝에서 설명된 임베딩 과정을 통해 밀집된 연속 공간에 임베딩된다.
- 이 과정에서 라는 메트릭스가 생성됨
- 이는 위의 사진에 나와있는 그래프 트랜스포머 모델의 입력으로 사용됨
- 각 정점 표현인 Vi는 G에서 vi와 연결된 다른 정점들에 대해 self-attention을 해 문맥화된다.
- 저희는 N개의 헤드를 가진 self-attention을 사용
- N개의 독립적인 어텐션을 계산하고, 이를 concatenate한 후, 잔차 연결 (residual connection)이 적용
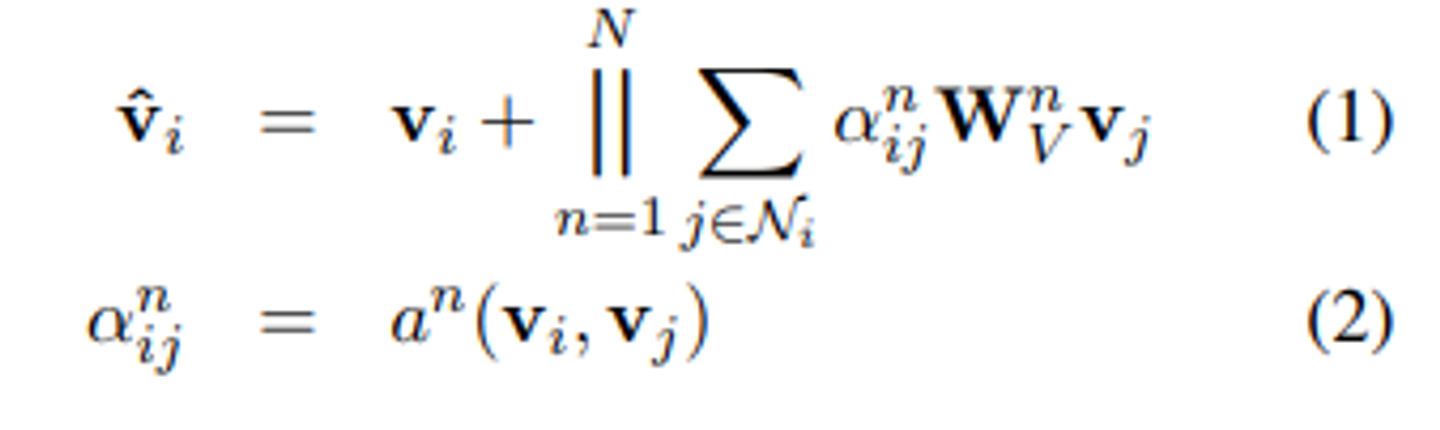
- 여기서 ||는 N개의 self-attention head를 concatenate한다는 의미
- 는 의 G에서의 이웃을 나타낸다.
- 는 attention메커니즘의 파라미터화된 매개변수이고, a^n은 각 헤드에 대해 매개변수화 된 attention메커니즘이다.
- 이 작업에서는 아래와 같은 형식의 attention 함수를 사용한다.
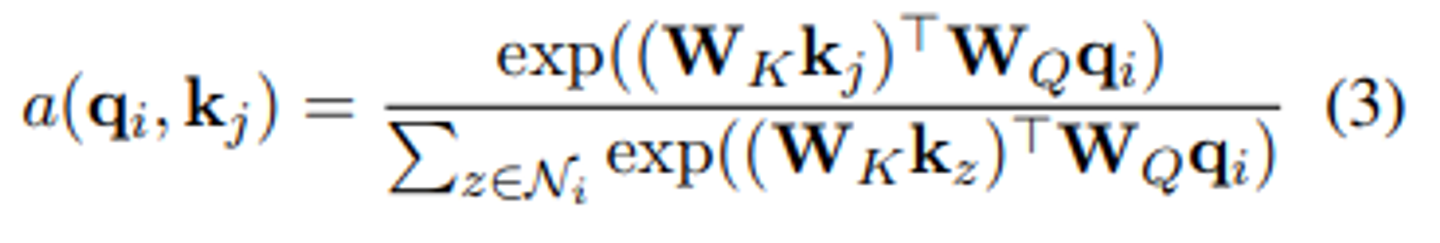
- 각각의 a는 q와 k에 대해 독립적인 변환 를 학습한다. 이들은 모두 크기의 행렬이다.
- 그리고 이러한 곱셈의 결과는 모든 연결된 엣지에 대해 정규화된다.
- 이러한 점곱의 경향이 gradient flow를 방해하는 경향을 줄이기 위해, 우리는 이를 Vaswani et al. (2017)에 따라 로 스케일링한다.
- 그래프 트랜스포머는 이 다중 헤드 어텐션 레이어를 블록 네트워크와 함께 확장한다. 각 블록은 다음과 같은 변환을 적용함.

- FFN(x)은 비선형 변환 f가 두개의 레이어로 구성된 피드포워드 네트워크이다.
- 즉, f(xW1+b1)W2+b2로 표현된다.
- 여러개의 블록을 쌓으면 정보가 그래프를 통해 전파될 수 있다.
- 블록은 L번 반복해서 쌓이며, l-1번째 레이어의 출력이 l번째 레이어의 입력으로 사용된다.
- 결과적으로 vertex encoding V_L=[V_i^L]는 그래프 구조에서 entity,관계 및 전역 노드에 관계에 기반한 정보를 나타낸다.
- 우리는 이러한 인코딩을 그래프 콘텍스트화된 버텍스 인코딩이라고 부른다.
Embedding Vertics, Encoding Title
- 앞에서 언급한 바와 같이, 그래프의 정점은 ScilE 주석에서 entity와 관계에 해당한다.
- 각 관계는 전방향 및 후방향 정점으로 표현되므로, 각 관계에 대해 두 개의 임베딩 및 전역 노드의 초기 임베딩을 학습한다.
- entity는 종종 여러 단어 표현으로 구성된 과학 용어에 해당한다.
- 각 구문에 대해 단일 d차원 임베딩을 생성하기 위해, entity구문의 각 단어 임베딩을 사용하여 양방향 RNN을 실행한 후의 마지막 은닉 상태를 사용한다.
- 즉, 밀집 임베딩 x와 구문 길이 m에 대해 BiRNN()을 사용한다.
- 임베딩 단계의 출력은 V의 각 정점을 나타내는 d차원 벡터의 컬렉션인 V0이다.
- 타이틀 입력은 짧은 문자열이기 때문에 다른 BiRNN으로 인코딩하여, T=BiRNN()을 생성한다.
Decoder
- 우리는 지식 그래프와 제목에서 입력을 복사하기 위해 어텐션 기반 디코더와 복사 메커니즘을 사용하여 디코딩한다.
- 각 디코딩 타임스텝 t에서 디코더의 은닉상태 를 사용하여 그래프 및 제목 시퀀스에 대한 문맥 벡터 와 를 계산한다.
- 는 에 의해 문맥화된 멀티헤드 어텐션을 사용하여 계산된다.
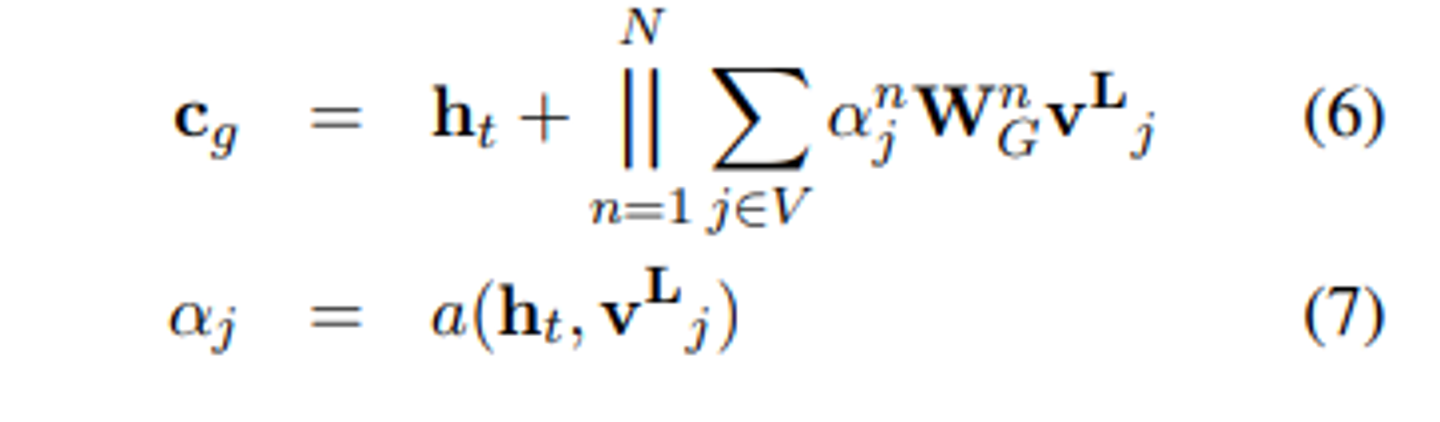
- 식 (1)에서 설명한 대로, 그래프 콘텍스트화된 인코딩 에 대해 어텐션을 적용하여 를 계산한다.
- 마찬가지로 제목 T에 대해 어텐션을 적용하여 를 계산한다.
- 그런다음, 연결(concatenation)을 통해 최종 문맥 벡터를 구성한다.
- 로 표기한다.
- 우리는 input-feeding decoder(Luong et al., 2015)를 사용하여 와 를 다음 RNN타임스텝의 입력으로 전달한다.
- 입력에서 복사 확률 p를 계산하기 위해 와 를 사용하는 방식은 다음과 같다.
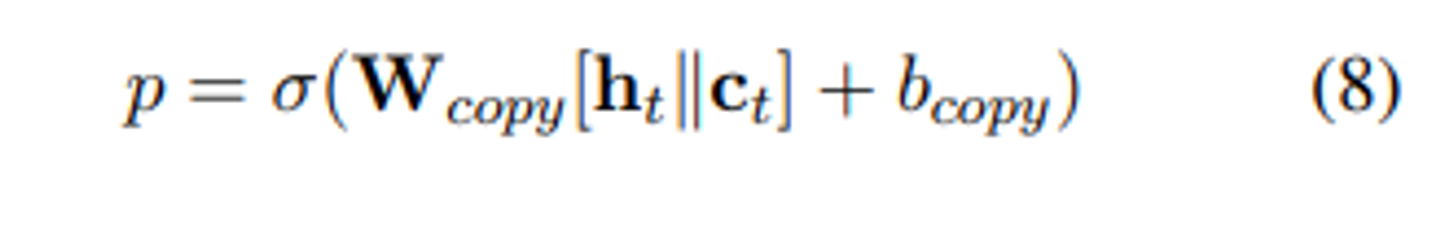
- 마지막 다음 token의 확률분포는 다음과 같이 계산된다.
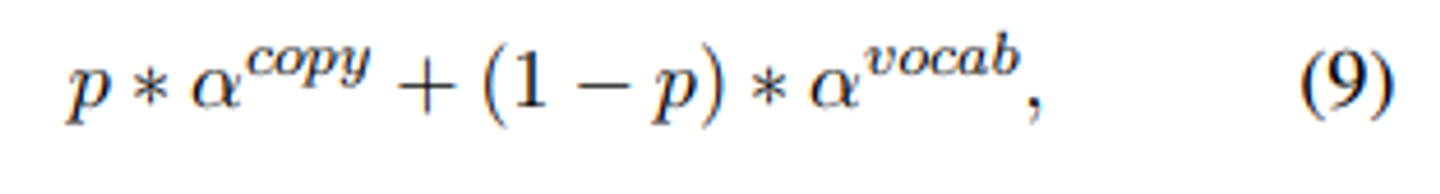
확률분포 \alpha는 entity와 입력토큰에 대한 복사를 나타낸다.
- entity 및 입력 토큰에 대한 \alpha의 확률분포는 로 계산되고, 이다.
- 나머지 1-p의 확률은 \alpha_vocab에 할당되며, 이는 [h_t||c_t]를 어휘 크기로 스케일링하고 소프트맥스를 취하여 계산된다.
Experiments
Evaluation Metrics
평가는 인간과 자동 평가의 조합으로 이루어진다.
인간 평가를 위해 참가자들에게 다양한 모델로 생성된 초록과 과학논문의 저자가 작성한 초록을 비교하도록 요청했다.
우리는 best-worse Scaling(BWS)를 사용했다.
이는 페어 비교에 비해 덜 노동 집약적이면서도 평가 척도보다 신뢰성이 높은 결과를 얻는 것으로 알려져 있다.
참가자들에게 두개 또는 세개의 초록을 제시하고
- 문법와 유창성(초록이 문법적으로 올바른 영어로 작성되었는가?),
- 일관성(초록이 소개, 문제 또는 작업설명, 해결책 설명, 평가 또는 결과 토론이 있는가?),
- 정보 전달력(초록이 제공된 제목과 관련이 있으며 적절한 과학용어를 사용했는가?)
의 순서대로 어느 것이 더 좋은지, 더 나쁜지 결정하도록 요청함.
좋은 예와 나쁜 예를 제시하고 정의된 기준을 충족하거나 미달하는 방식으로 그들이 성공하거나 실패하는지 설명한다.
우리의 데이터셋이 과학적인 성격을 가지고 있기 때문에, 전문가들에 의해 평가되어야 하며, 이러한 고품질의 데이터 포인트를 제한적으로 수집할 수 밖에 없다.
이 연구는 초록작성 작업과 평가 대상 초록의 내용에 익숙한 15명의 전문가에 의해 수행됨.
이를 보완하기 위해 자동 평가 지표도 제공.
텍스트 생성 작업에서 널리 사용되는 n-gram, 중복 측정인 BLEU와 문장 재구성과 언어 특정 고려 사항이 포함된 기계 번역 평가 지표인 METEOR를 사용한다.
comparisons
우리는 GraphWriter를 강력한 기준선과 비교했다.
GAT에서는 Graph Transformer인코더를 (Velickovi ˇ c et al. ´ , 2018)의 Graph Attention Network로 대체했다.
이 인코더는 6개의 self-attention 레이어 사이에 쌓인 PReLU 활성화함수 함수로 구성된다.
그래프 관계를 포함하는 것의 유용성을 판단하기 위해, 엔티티와 제목만 사용하는 모델인 EntityWriter와 비교했다.
마지막으로, Wang et al. (2018)의 gated rewriter모델과 비교했다.
이 모델은 문서 제목만을 사용하여 출력의 초안을 반복적으로 다시 작성한다.
Implementation Details
우리 모델은 대상 텍스트 어휘와 복사된 개체 인덱스의 negative joint log like-lihood를 최소화하기 위해 end-to-end로 훈련된다.
우리는 SGD 최적화와 모멘텀을 사용하고, “warm restarts”, 라는 주기적인 규칙을 사용한다.
이 규칙은 5개의 epoch동안 학습률을 0.25에서 0.05로 감소시킨 후 다음 에포크를 위해 초기화한다.
모델은 early stopping을 기반으로 15epoch 동안 훈련되며, 대부분의 모델은 8에서 14개의 epoch에서 훈련을 중지한다.
우리는 재귀 신경망으로 단일층 LSTM을 사용한다.
self attention레이어에서는 dropout을 0.3으로 설정
은닉상태와 임베딩 차원은 500으로 고정되며, 어텐션은 500차원으로 프로젝션을 학습한다.
Block레이어에서 feed forward network는 중간 크기가 2000이먀, PReLU활성화함수를 사용한다.
GraphWriter 와 GAT는 L=6레이어를 사용한다.
어텐션 헤드의 수는 4로 설정된다.
모든 모델에서 입력과 출력모두에서 단어 빈도가 5보다 작은 단어는 토큰으로 대체한다.
빔 서치를 사용하여 디코딩을 수행하며, 빔크기는 4로 설정한다.
후처리단계에서는 반복된 문장과 반복된 동등 절을 삭제한다.
