1.Introduction
인간과 유사한 챗봇을 만들기 -> 대화속에 내포된 암묵적인 정보를 효과적으로 이해 -> 상식적인 추론을 사용해야 함
하지만 이런 한가지 연결에서의 핵심 증거를 식별하고 통합하는 작업은 상당히 어려움
why?
-> 대화에서의 상식적 추론은 multi-hop reasoning 을 가지기 때문
핵심 근거가 여러 대화 턴에 흩어져 있고, 암묵적으로 명시되어 있기 때문이다.
모든 필요한 정보를 single hop 에 해결하는 것이 쉽지 않음.
-
해결 : LLMs의 성공에서 영감을 받아 multi-hop reasoning 을 대화 응답 생성을 위한 chain-of-Thought(Cot) 추론으로 정의함 -> Dialogue Cot
-
목표 : 언어 모델이 상식적 추론을 여러 단계로 분해하고 응답 생성에 필요한 상식적 지식의 추론된 시퀀스로 rationale(이유,근거)을 생성하는 것이다.
-
LLMs에 프롬프트를 제공하는 것에 대한 한계점 :
- LLMs은 암묵적 지식을 찾기 위해 과제 특정 제약 조건이 필요한 명시적 신호에 지나치게 의존한다.
- LLMs는 레이셔널과 대화 사이에 부적절하고 도움이 되지 않는 일관성 없는 정렬을 나타내는 경햠이 있음
-> LLMs로부터 CoT 능력을 선택적으로 전달하는 강력한 symbolic distillation mechanism이 필요하다.
이 논문의 기여
- propose dialogue chain -of -thought distillation framework
-> 신뢰할 수 없는 LLMs에서 plausible한 rationale들을 추출 해내고
-> 반복적인 질문 응답 및 정렬 필터링을 통해 high-quality CoT rationale을 수집함 - 이 framework를 사용함으로써, DONUT을 수집 -> a dialogue dataset annatated with highquality CoT rationales.
- DONUT을 사용하여 DOCTOR(DialOgue Chian of thought Commonsense)을 훈련
-> integrates implicit information in dialogue into rationale for generating
2. Dialogue Chain-of-Thought Reasoning
2.1 Preliminaries
최근의 연구는 dialogue agents에 상식적인 지식을 부여하여 대화 모델링을 향상시키는 것을 목표로 하고 있다. 이를 통해 대화에서 암묵적인 정보를 추론할 수 있다.
구체적으로, 대화 모델 는 상식적인 지식 를 추가 입력으로 받아 t-1 턴의 대화 context 에 대한 다음 응답 를 예측한다.
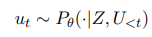
이러한 접근에서, 상식적인 지식 Z은 주로 상징적 지식 베이스(KBs)에서 검색되거나 (ATOMIC), COMET과 같은 neural KBs(신경망 지식 베이스)로부터 생성된다.
그러나 이런 방법들은 종종 대화에서 미묘하면서도 암묵적인 세부 사항을 간과할 수 있으며, 둔하고 일관성 없는 응답으로 이어질 수 있다.
따라서 이 논문은,
대화에서의 상식적 추론이 여러 점프를 필요로 하며, 이러한 암묵적 세부 사항을 여러 턴에 걸쳐 흩어져 있는 것을 포착해야 한다고 주장한다.
2.2 Formulating Chain-of-Thought Reasoning
multi reasoning task에서의 rationale-augmented LLMs의 성공에 영감을 받아, 우리는 dialogue CoT 추론 대화에서 multi-hop reasoning을 정립한다.
이는 추론(reasoning) 을 여러 단계로 분해하고, 추론된 상식 지식을 응답 생성을 지원하는 rationale과 결합시킨다.
dialogue CoT reasoning 을 사용하면, 대화 사용자는 대화에서 관련 있는 문맥적 단서를 식별하고, 문맥적 기저에 있는 암묵적 정보를 활용하여 일관된 응답을 생성할 수 있다.
dialogue CoT reasoning의 일반적인 접근 방법은 LLMs에 CoT prompt를 적용하는 것이다.
하지만 이 방법에는 몇가지 한계가 있다. (최적의 방법이 아니다. 위에랑 비슷한 말)
1 LLMs은 추론을 위해 대화에서 명시적인 신호(ex:어휘적 중첩)에 더욱 집중하며, 암묵적인 정보를 추론하기 위해 모델을 안내하는 task 특정 제약이 필요하다.
2. rationale은 종종 대화와 정렬이 맞지 않아(misaligned) 맥락과 일관성이 없거나, 응답 생성에 도움이 되지 않는다.
--> 대화 agent를 위해 고품질의 rationale을 생성하는 신뢰할 수 있는 CoT 추론기를 구축하는 것을 목표로 한다.
3. Dialogue Chain-of-Thought Distillation(증류,정제)
이 섹션에서는 신뢰 할 수 있는 CoT reasoning 을 (재)훈련시키기 위해 신뢰할 수 없는 LLM에 서 타당한 CoT 레이셔널을 추출하고 정렬 필터(alignment filter)를 통해 고품질 rationale을 선택적으로 증류하는 강력한 knowledege distillation framework을 제안한다.
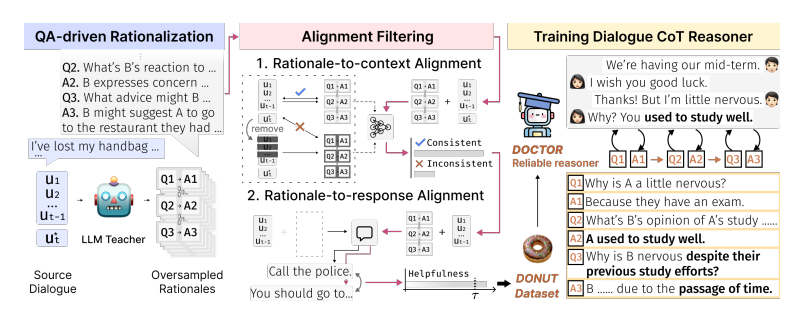
3.1 QA-driven rationalization
우리의 프레임 워크는 LLMs의 rational capacity를 활용하여 기존 대규모 대화 말뭉치를 dialogue oT raionales로 확장하도록 설계되었다.
먼저, LLM에게 현재 대화 컨텍스트 와 ground-truth response 에 대해서 타당한 rationale 를 생성하도록 prompting 한다.
-> 이를 통해 생성된 rationale 로 부터 다음 응답인 가 유도되도록 해야한다.
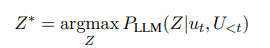

구체적으로, rationale 를 와 같은 k개의 질문-답변 쌍의 시퀀스로 표현한다. 여기서 는 대화 컨텍스트 에서의 암묵적인 정보 a_i에 관한 정보를 요청하는 질문이다. LLM에게 반복적으로 질문과 답변을 생성하도록 지시함으로써 모델에게 관련된 문맥적 단서를 정확하게 파악하고 응답 생성을 지원하는 기저 지식을 추론하도록 한다.
이 논문에서는 로 ATOMIC 을 사용하였다.
또한, 5개의 demonstrations of dialogue CoT를 추가하였다. 이는 각각이 대화 에 대한 인간이 작성한 질문-답변 쌍이다.
3.2 Alignment Filtering
주석이 달린 rationale의 품질을 보장하기 위해 우리는 dialogue context와 ground-truth response의 정렬에 기반하여 rationale을 필터링 하는 2개의 alignment filter을 도입함
- Rationale-to-context alignment
LLMs은 맥락을 고려하지 않고 사실을 날조하는 경향이 있기 때문에, 이는 종종 대화 context와 정렬되지 않은 rationale을 만들어낼 수 있다.
따라서 우리는 critic model을 사용하여 LLMs에서 이러한 일관성 없는 rationale을 최소화한다.
critic model은 대화 맥락에 올바르게 기반을 두지 않고 생성된 counterfactual rationales을 감지하기 위해 사용된다.
우리는 LLM에게 마지막 발화만을 포함하는 counterfactual context 로 부터 counterfactual rationale인 을 생성하도록 한다.
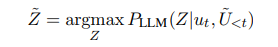
critic model은 주어진 대화 context에서 대화 와 를 구별하는 훈련을 받는다.
우리는 SODA에서 6k개의 대화를 샘플링하고 생성된 rationale 집합에서 일관된 쌍을 구성하여 비판 모델의 쌍의 훈련 인스턴스를 5000개 얻는다.
- Rationale-to-response alignment
rationale과 response이 일치하다고 간주하는 법 -> rationale이 대화모델에서 ground-truth response를 예측하는데 도움이 될때
따라서! 우리는 대화모델가 context 가 주어진 상황에서 ground truth response 를 예측할때, rationale Z에서 도움을 받는지를 결정하기 위해 지표 함수 helpful를 도입한다. 형식적으로 boolean함수인 helpful를 다음과 같이 정의한다.

1[·]은 이진 표시이고, τ는 하이퍼파라미터이다. 직관적으로 분자의 확률값이 클수록 기여의 양이 큼을 나타낸다.
3.3 Training DOCTOR
주석이 달린 대화 말뭉치를 사용하여 DOCTOR(Dialogue chain-of-Thought Reasoner)을 훈련한다. 우리는 모델을 causual language modeling objection으로 훈련하여, 대화 기록 이 주어졌을 때, raionale 를 생성하는 확률을 예측한다.
본질적으로 훈련 목표를 raionale 내의 질문-답변 쌍 시퀀스에 대한 다음 토큰 예측으로 정의된다. 모델은 이전에 생성된 질문-답변쌍을 따라 와 를 순환적으로 예측한다.
모델이 부속 질문을 생성하고, 답하는 것을 학슴함으로써 해당 대화에서 대응하는 상식 지식을 추론하는데 필요한 모든 암무적인 정보를 식별할 수 있다고 가정한다.
4.DONUT
DOCTOR과 함께, 그의 훈련 말뭉치인 DONUT을 제시한다.
DONUT은 dialogue CoT reasoning을 위한 주석이 달린 DialOgue chaiN-of-thoUght 데이터 세트이다. 우리는 주석을 위한 source dialoge를 샘플링하기 위해 DailyDialog, DREAM, MuTual 이라는 3가지 인간 수집 대화 데이터 세트를 선택했다.
확장성을 위해 SODA라는 백만 규모의 소셜 대화 데이터 세트의 대화 중 5%를 포함함.
각 대화의 각 발화에 대해(첫 번째 발화 제외), chatGPT에게 10개의 rationale 후보를 생성하도록 지시함. 3.2에서 소개한 두 정렬 필터를 사용하여 대화 컨텍스트와 일치하지 않거나 다음 응답을 예측하는데 도움이 되지 않는 후보(122,319개)를 걸러냈다.
그 결과로 나온 DONUT 데이터 세트는 10,000개의 대화와 367,000개의 CoT rationale로 구성되어 있다.

