. Introduction
최근 나오는 V+L 모델들은 다층 transformer를 기반으로 한다.
이러한 모델을 사전 훈련하기 위한 기존 방법은 이미지 영역 특징과 텍스트 특징을 간단히 연결하고, self-attention mechanism 을 사용하여 이미지 영역과 텍스트 간의 의미적인 정렬을 무차별적으로 학습한다.
but,
- 이미지 영역과 텍스트 간의 명시적인 정렬 정보 부재로 인해 정렬 모델링은 약한 지도 학습 작업으로 제기됨
- 시각적인 영역은 종종 over-sampling되어, 노이즈가 많고 모호해서 작업이 어렵다.
따라서, 이 논문에서는 이미지에서 감지된 객체 태그를 도입하여 시각과 언어 간의 의미적인 정렬 학습을 용이하게 함으로써 cross modal 표현 학습을 현저이 개선할 수 있음을 보여준다.
훈련 샘플을 1) word sequence 2) a set of object tags 3) set of image region features 로 구성된 트리플로 정의하는 새로운 VLP 방법인 “OSCAR”을 제안한다.

- 650만 쌍으로 구성된 대규모 V+L 데이터셋에서 사전훈련됨
- 7개의 V+L 이해 및 생성 작업에서 fine-tuning됨
anchor point는 alignment modeling(정렬 모델링)에서는 자연어 처리 분야에서 사용된 적이 있지만, VLP에서의 도입은 처음이다.
이미지 영역의 특성 표현을 향상시키기 위해 객체 또는 이미지 태그를 사용하는 이전의 작업들은 이미 존재했지만, image-text 정렬학습이 목적은 아니었음
(대충 우리 연구 분야 처음이다)
*alignment modeling : 두 가지 다른 데이터 관계를 모데링하는 과정 (언어-언어, 이미지-텍스트, 음성-텍스트 등)
2. Background
(자세한 background는 앞의 노션 확인. 이 백그라운드는 논문 피셜)
- 데이터 셋
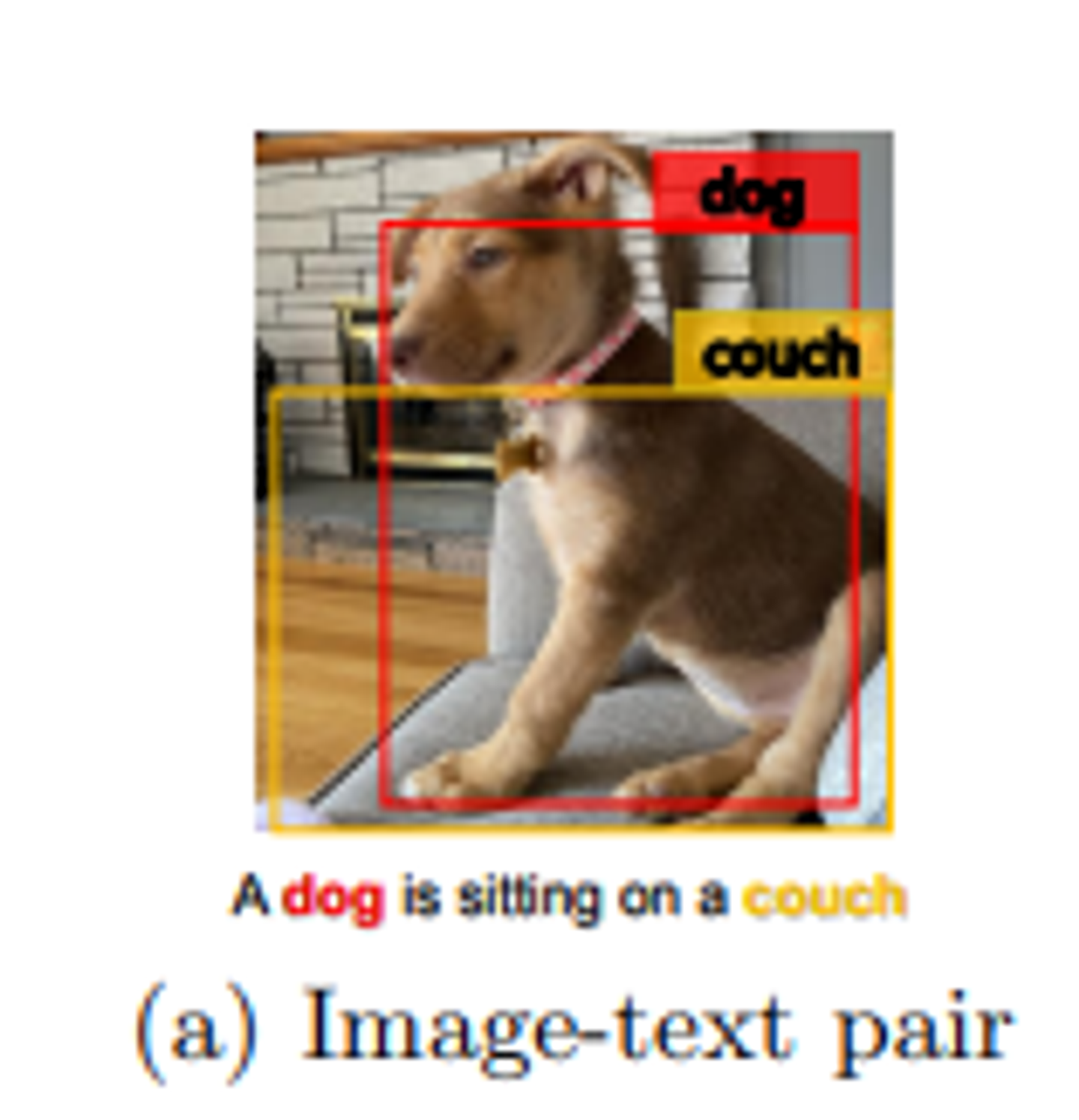
V+L 작업에 대한 훈련데이터는 위의 그림과 같이 이미지-텍스트 쌍으로 이루어져 있다.
크기가 N인 데이터셋은 로 표시되며, 여기에서 I가 이미지, W는 텍스트 시퀀스를 나타낸다.
사전훈련의 목표는 self-supervised 방식으로 이미지-텍스트 쌍의 cross modal 표현을 학습하는 것이며, 이는 fine-tuning을 통해서 다양한 작업을 수행할 수 있다.
- (기본적인) 훈련
VLP(Vision-Language Pretraining)은 일반적으로 각 modality의 단일 임베딩을 기반으로 cross contextualized representation을 학습하기 위해 Multi-layer self-attention transformer을 사용한다.
따라서 VLP의 성공은 기본적으로 input인 단일 임베딩의 품질에 의존한다.
기존의 VLP 방법은 이미지의 시각적인 영역 특징 과 해당 텍스트의 단어 임베딩w = {w1, · · · , wT}을 입력으로 취하고, self-attention mechanism에 의존하여 image-text alignment 를 학습하고 cross -modal contextual representation을 생성한다.
- 기존 훈련 방법의 문제점
(1) 모호성
시각적인 영역 특징은 보통 Faster R-CNN 객체 탐지기를 통해 over-sampled regions에서 추출되는데, 이는 불가피하게 서로 다른 위치의 이미지 영역 간에 중첩이 발생한다. 이로 인해 추출된 시각적 임베딩에 모호성이 발생한다.
예를 들어 위의 그림에서 개와 소파의 영역 특징은 겹쳐 있어서 구별하기 어렵다.
(2) Grounding부족
VLP는 본질적으로 이미지의 영역이나 객체와 텍스트의 단어나 구문간에 명시적으로 레이블이 지정되지 않는다. (weakly-supervised learning problem)
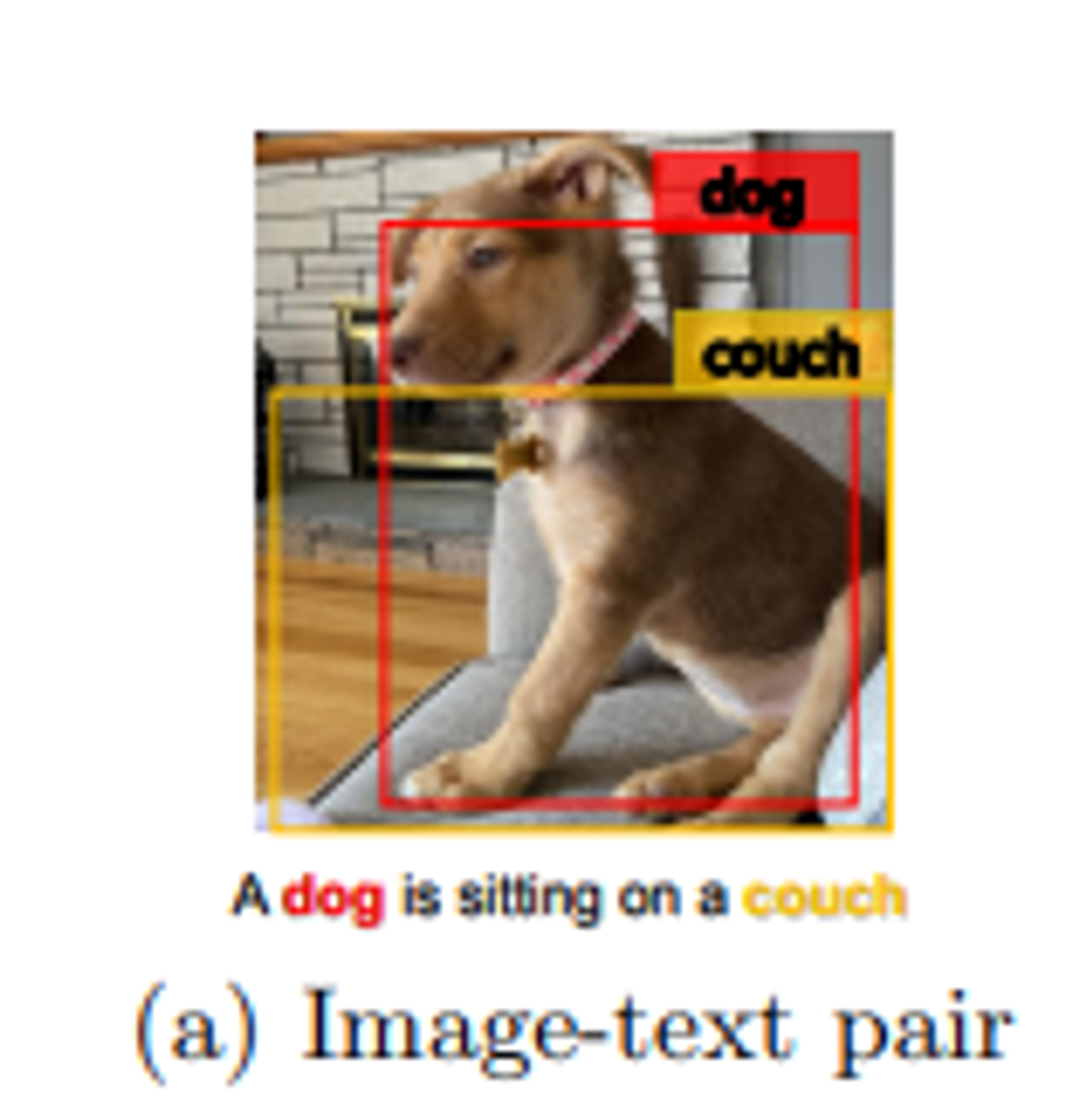
하지만 이 그림에서처럼 개와 소파 같은 뚜렷한 객체는 이미지와 그에 대응하는 텍스트에 모두 나타나며, 이미지 영역과 텍스트 단위 간의 의미적(semantic) 정렬을 학습하기 위한 anchor point로 활용될 수 있다. (그림 b)
→ 가 논문에서 이용하여 문제를 해결하는 방법임.
3. Oscar Pre-training
(아이디어) 인간은 여러 채널을 통해 세상을 인지한다. 개별 채널이 불완전하거나 노이지하더라도 여러 채널 간에 공유가 이뤄지기 때문에 중요한 요소는 여전히 인지가능 하다.
Oscar: learn representation that capture channel-invariant(or modality-invariant) factors at the semantic level.
Oscar은 의미적인 수준에서 채널의 독립적인 요소를 포착하는 표현을 학습하기 위한 것이다.
개요 그림은 다음과 같다.
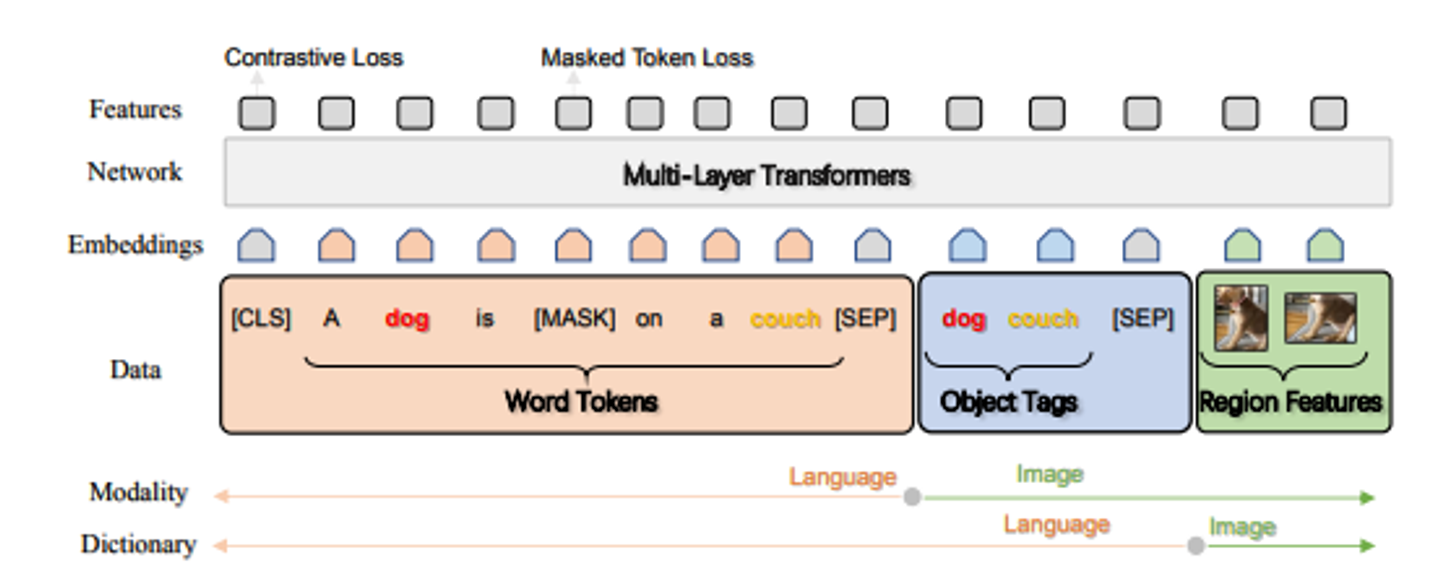
3.1 Input
Oscar은 각 입력 이미지-텍스트 쌍을 Word-Tag-Image 트리플(w,q,v)로 표현한다.
w : 텍스트의 단어 임베딩 시퀀스
q : 이미지에서 감지된 객체 태그( 텍스트 형식) 의 단어 임베딩 시퀀스
v : 이미지의 영역 벡터 집합
기존의 VLP은 입력쌍을 (w,v) 로 표현하지만, OSCAR에서는 q를 도입한다. ‘이는 훈련 데이터에서 중요한 객체들이 이미지와 연관된 텍스트에서 동일한 단어 또는 비슷한 단어로 표현되는 경향이 있기 때문이다. q와 w 사이의 alignment은 BERT를 사용하여 비교적 쉽게 식별된다.
이미지 영역에서 객체 태그가 감지된 지점은 텍스트의 의미적으로 관련된 단어에 의해 조회될 때 다른 영역보다 높은 attention weight를 가질 가능성이 있다.
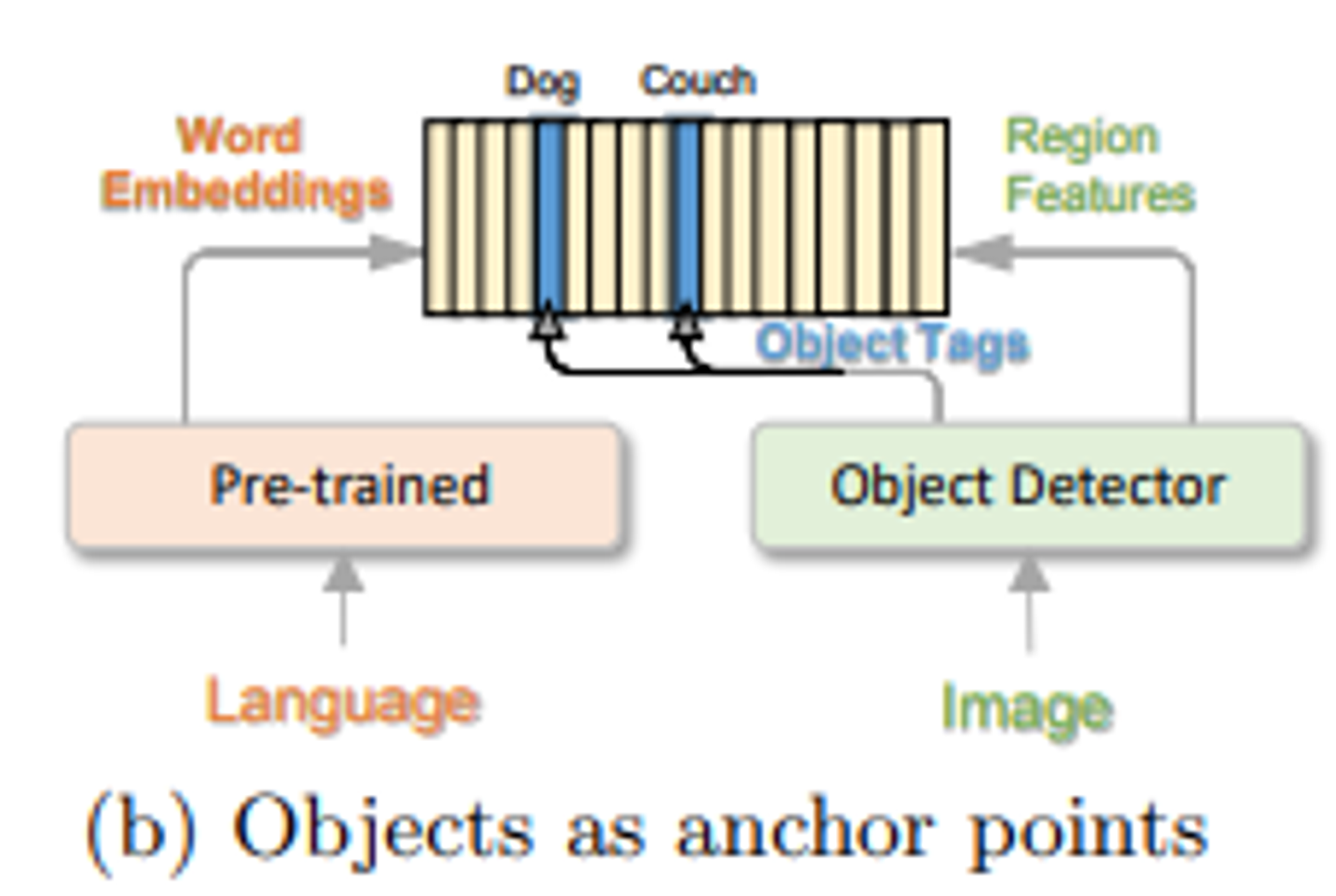
이 과정은 또한 이미지 객체를 언어 공간에서 독특한 entity로 표현되는 것으로 해석될 수 있다. 위의 그림 (C)에서 나타낸 것처럼 독특한 entity로 언어 공간에 묘사하는 것이다.
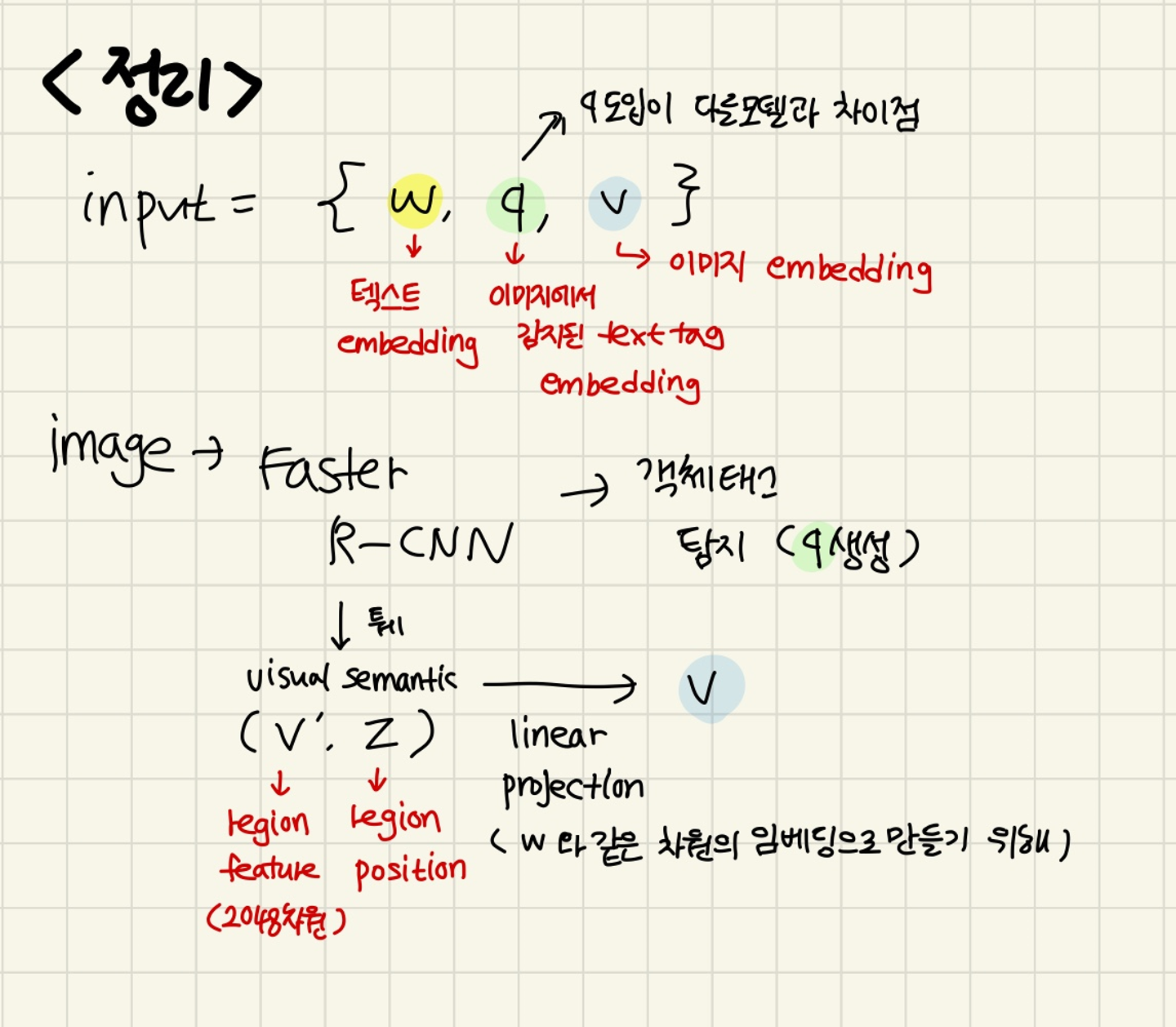
구체적으로 v와 q는 다음과 같이 생성된다.
객체의 k개 영역이 있는 이미지가 주어지면(normally over-sampled and noisy) , Faster R-CNN을 사용하여 각 영역의 시각적 의미를 로 추출한다.
여기서 는 p차원 벡터이다.(p=2048).
영역위치 z는 R-차원 벡터이다. (R=4 또는 6)
position-sensitive region feature vector을 만들기 위해서 와 를 concat한다. 그리고 이는 linear projection 을 통해서 로 변환된다.
이는 word embedding과 같은 차원으로 만들기 위한 작업이다.
동시에 Faster R-CNN을 사용하여 객체 태그의 집합을 감지한다. q는 객체 태그의 단어 임베딩 시퀀스이다.
3.2 Pre-training Objective
OSCAR의 인풋은 두 가지의 관점으로 볼 수 있다.
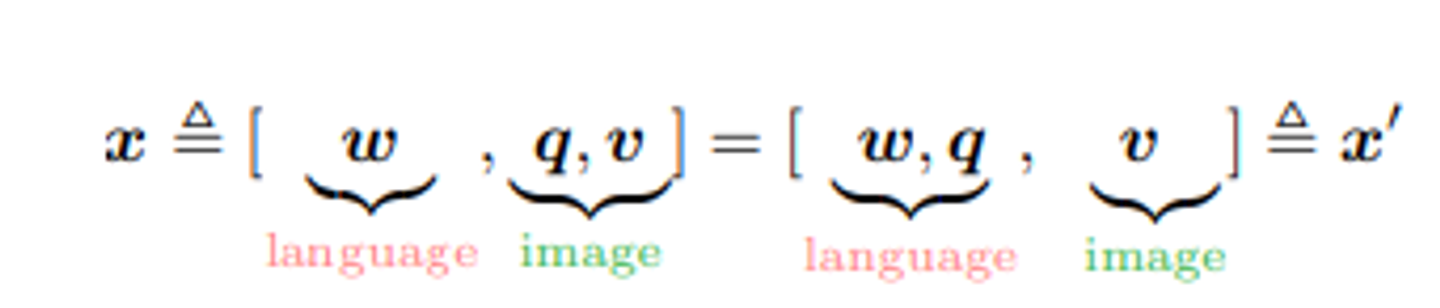
- modality view(x): text와 image 사이의 representation을 구분함
- dictionary view(x’) : 두 개의 다른 semantic space를 구분하는 것
이 두가지 관점은 새로운 pre-training objective을 디자인한다.
- A Dictionary View : Masked Token Loss
다른 사전의 사용은 서로 다른 하위 시퀀스를 표현하는데 사용되는 의미 공간을 결정한다. 구체적으로 객체 태그 및 단어 토큰은 동일한 언어 의미 공간을 공유하며, 이미지 영역 특징은 시각적 의미 공간에 속한다.
이산 토큰 시퀀스를 아래와 같이 정의하고, 사전 훈련을 위해 Masked Token Loss(MTL)을 적용한다.
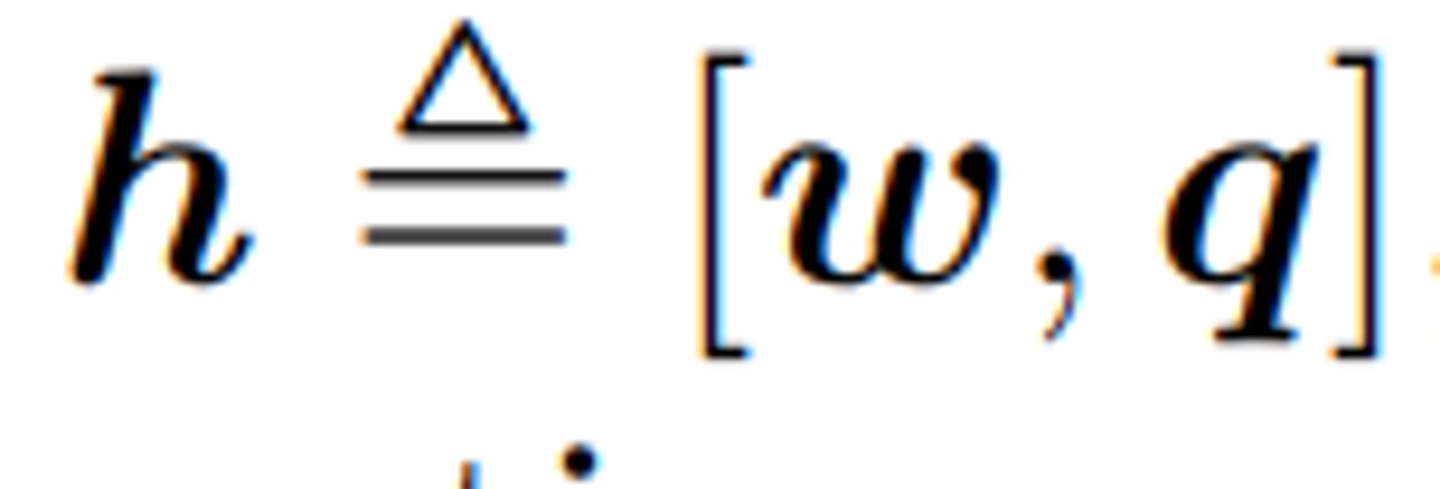
각 반복에서 h의 각 입력 토큰을 15%의 확률로 무작위로 가리고, 가려진 토큰 를 [MASK]토큰으로 대체한다.
훈련의 목표는 주변 토큰 와 모든 이미지 특징 를 기반으로 이런 가려진 토큰을 예측하여 negative log-likelihood를 최소화하는 것이다.
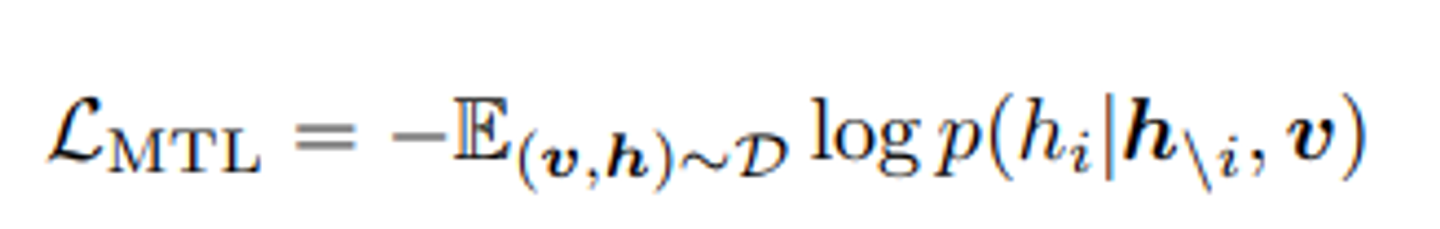
이는 BERT에서 사용되는 masked language model과 유사하다.
가려진 단어 또는 태그는 주변에서 복원되어야 하며, 학습된 단어 임베딩을 vision context에서 지원하기 위해 추가 이미지 정보가 참고되어야 한다. (그 다음 함수)
- A Modality View : Contrastive Loss
각 3개의 입력에 대해서 우리는 다음과 같이 이미지를 표현하는데 사용하고, 를 언어 모달리티로 간주한다.
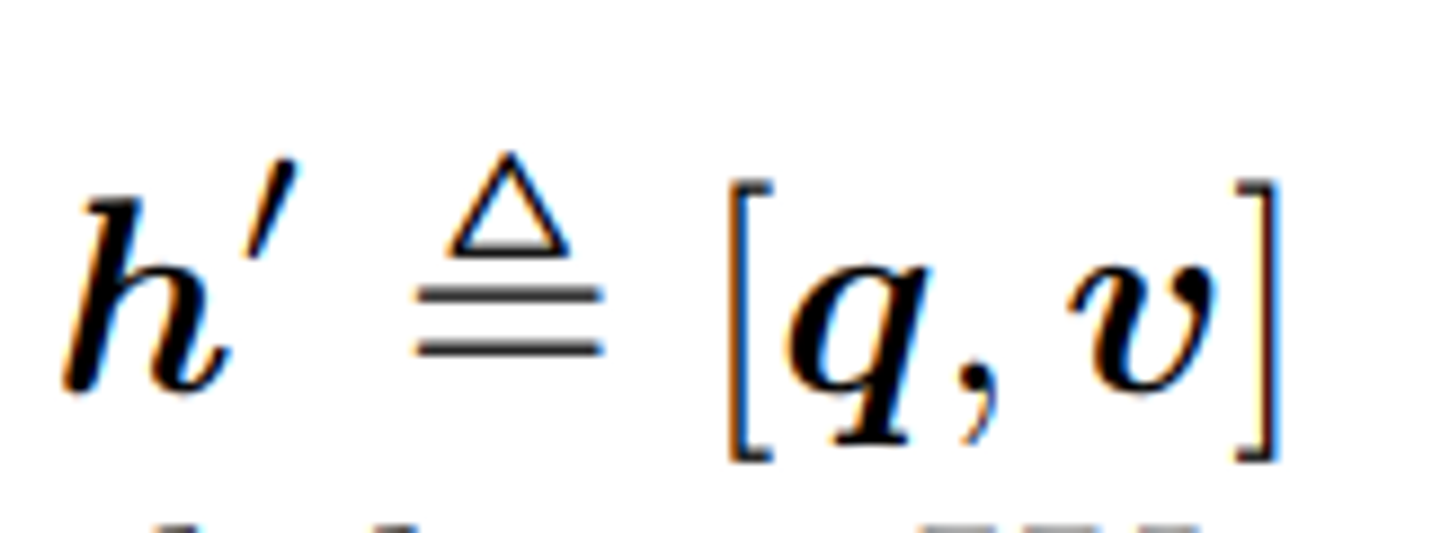
그런 다음, q를 데이터 세트 D에서 무작위로 샘플링한 다른 태그 시퀀스로 50%의 확률로 교체하여 “polluted” 이미지를 표현한다.
특별한 토큰 [CLS]의 인코더 출력은 fused vision-language 의 표현으로 이기 때문에 우리는 맨 마지막에 FC layer에 넣어 쌍이 원래 이미지 표현(y=1)을 포함하는지 또는 오염된 이미지 표현(y=0)을 포함하는지를 예측한다.
contrastive loss는 다음과 같이 표현된다.
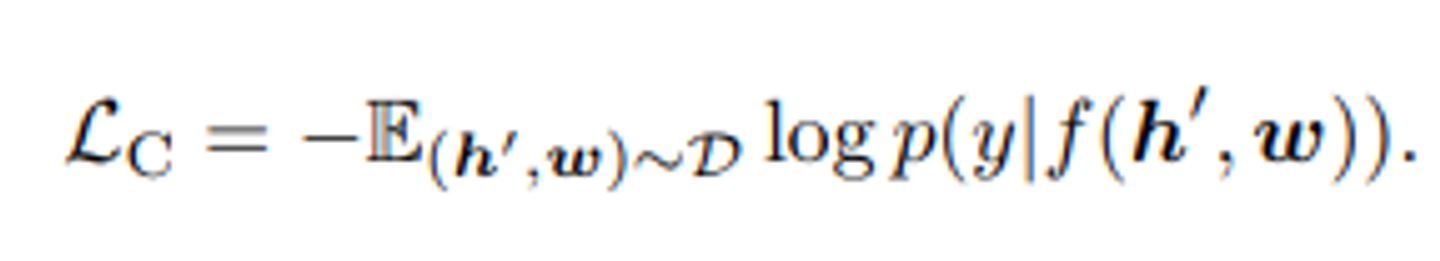
pre-trained중에는 이미지의 프록시로서 객체 태그를 사용하여 BERT의 단어 임베딩 공간을 조정한다.
최종적인 OSCAR의 손실함수는 다음과 같이 정의된다.


3.3 Pre-training Corpus
기존의 V+L 데이터셋을 기반으로 사전 훈련 말뭉치를 구축했다.
COCO, Conceptual Captions, SBU captions, filcker, QA 등이 있다.
총 410만개의 고유 이미지, 말뭉치는 650만개의 텍스트-태크-이미지 트리플로 이루어져 있다.
3.4 Implementation Details
Oscar B와 OscarL이라는 두 가지 모델 변형을 사전훈련하였다.
이들은 각각 BERT base(H=768)와 large(H=1024)의 파라미터로 초기화되었다. 여기서 H는 hidden size이다.
image region feature가 BERT와 같은 임베딩 크기를 가지도록 하기 위해 행렬 W를 통한 linear projection을 통해 position-sensitive region feature을 변형한다.
따라서 파라미터는 아래와 같다.

옵티마이저는 Adamw.
OscarB는 최소 100만단계까지 학습, lr=5e-5, batch_size=768
OscarL은 최소 90만 단계까지 학습, lr=1e-5, batch_size=512
4. Adapting to V+L Tasks
(이쪽은 background 랑 내용이 비슷합니다)
4.1 Image-Text Retrieval
imgage-text retrieval은 join representation에 크게 의존한다.
훈련은 binary classfication 문제로 본다.
정렬된 이미지-텍스트 쌍이 주어지면, 다른 이미지 또는 다른 캡션을 무작휘로 선택하여 정렬되지 않은 쌍을 형성한다.
[CLS]의 최종 표현은 주어진 쌍이 정렬되었는지 여부를 예측하기 위해 분류기에 입력으로 사용된다.
binary classification loss가 더 성능이 좋았기 때문에 ranking loss는 사용하지 않음.
공식은 image BERT와 동일하다고 작성됨
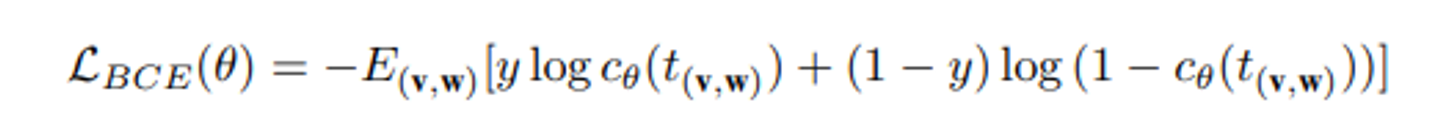
image BERT 논문 왈 :
y가 예측하는 레이블(0,1).
이미지 텍스트 쌍(v,w)에 대해 출력된 첫번째 토큰 의 임베딩을 로 취한 다음, 이진 분류 손실을 최적화한다.
4.2 Image Captioning
image captioning은 모델이 이미지 내용에 대한 텍스트 설명을 생성하는 것을 필요로 한다.
문장 생성을 가능하게 하기 위해 seq2seq objective을 사용하여 Oscar을 fine-tuning하였다.
입력 샘플은 이미지 영역 특성, 캡션 및 객체 태그로 이루어진 트리플( 사전훈련과 동일한 방식)
캡션 토큰의 15%을 무작위 마스크 처리, 해당 출력 표현을 사용하여 토큰 id를 예측하는 분류작업을 수행
self-attention mask는 캡션 토큰이 단방향 생성 프로세스를 모방하도록 제어된다.
이미지 영역, 객체 태그, 특별한 토큰 [cls]을 입력으로 인코딩함.
다음, 모델은 [MASK]토큰을 먹여 어휘에서 확률 출력을 기반으로 토큰을 샘플링하여 생성을 시작한다.
다음으로 이전 입력 시퀀스의 [MASK] 토큰은 샘플링된 토큰으로 대체되고 새로운 [MASK]가 다음 단어 예측을 위해 추가된다.
생성 프로세스는 모델이 [STOP]토큰을 출력할 때 종료한다.
실험에서, BEAM SIZE 5로 하는 빔서치를 사용하고 COCO 데이터셋을 이용한다.
4.3 Novel Object Captioning(NocCaps)
NoCaps는 훈련되지 않은 새로운 객체 이미지에 대해서도 묘사할 수 있는 것을 말한다.
Nocaps 논문에 따라, Visual Genome 및 Open Images 레이블을 사용하여 태그 시퀀스를 형성하고, Oscar을 사전 훈련 초기화 없이 CoCO에서 훈련시킨다.
4.4 VQA
VQA는 모델이 이미지를 기반으로 자연어 질문에 대답하는 것을 요구한다.
여러 개의 객관식에서 정답을 선택해야한다. (올바른 이미지에 대한 설명)
MSCOCO 이미지 말뭉치를 기반으로 만들어진 VQA V2.0 데이터셋에서 실험을 진행한다.
- 인풋은 위에서 말한 트리플
- Oscar에서 나온 [cls] 출력이 FC layer에 입력되고 되어 예측 점수 생성
- 이를 다중 레이블 문제로 취급하여, 각 답변에 대한 인간 답변 응답과의 관련성을 기반으로 소프트 타겟 점수를 할당한다.
- 예측된 점수와 소프르 타겟 점수를 사용하여 교차 엔트로피 손실을 최소화하는 방식으로 finetuned
4.5 GQA
Genome Question Answering
질문에 답하는 모델의 추론 능력을 테스트하기 위한 데이터셋.
이미지와 관련된 다양한 질문에 대한 정답을 포함하고 있으며, 모델이 질문의 의미를 이해하고 효과적으로 추론하여 정확한 답변을 제공할 수 있는지를 평가
→ 즉, 이미지에 대한 다양한 유형의 질문으로 구성됨
4.6 Natural Language Visual Reasoning for Real(NLVR2)
이미지 쌍과 자연어를 취하여, 자연어 진술이 이미지 쌍에 대해 참인지 여부를 결정하는 것.
주어진 문장(텍스트 설명) 과 하나의 이미지를 연결한 것을 입력으로 넣고, Oscar에 나온 두개의 [CLS] 출력을 이진 분류기에 공동 입력으로 사용하기 위해 연결한다.
