1. Introduction
최근 작업인 Mamba는 SSM에 시간 변동 매개변수를 통합하고 매우 효율적인 훈련 및 추로늘 가능하게 하는 하드웨어에 대한 인식 알고리즘을 제안한다. 이는 Transformers의 유망한 대안이다. 하지만 시각데이터를 처리하기 위한 일반적인 순수 SSM 기반 backbone 네트워크는 탐구되지 않았다.
비전 트랜스포머(Vit)는 conv network와 비교했을 때, 각 이미지 패치에 데이터/패치에 따라 전역 컨텍스트를 제공할 수 있다는 장점이 있다.(conv은 모든 위치에 대해 동일한 매개변수를 사용함) 하지만 transformers의 self-attention은 장거리 시각적 종속성(long-range visual dependencies) 을 처리할 때 속도와 메모리 사용량 측면에서 도전을 제기한다.
-> Mamba의 언어 모델링에서의 성공을 고려하면, 이 성공을 언어에서 시각으로도 전이할 수 있다고 생각. 즉, 고급 SSM 방법론을 활용하여 일반적이고 효율적인 시각적 백본을 설계 가능
하지만 두가지 도전 과제가 있음.
1. 단방향 모델링(unidi-rectional modeling)
2. 위치 인식의 부족 (lack of positional awareness)
-> 이를 해결하기 위해 Vision Mamba(Vim)모델을 제안.
이 모델은 데이터 종속적 전역 시각적 컨텍스트 모델링(data-dependent global visual context modeling)을 위해 양방향 SSM(bidirectional SSMs)과 위치 임베딩(positional embeddings)을 결합한다.
먼저, 입력 이미지를 패치로 분할하고 이를 Vim으로 벡터로 선형적으로 투영한다.
이미지 패티는 Vim 블록에서 시퀀스 데이터로 처리되며, 제안된 양방향 선택적 상태 공간을 사용하여 시각적 표현을 효율적으로 압축한다.
또한 Vim 블록의 위치 임베딩은 공간 정보에 대한 인식을 제공하여 Vim이 밀집 예측 작업에서 더 견고하게 될 수 있도록 한다.
현재단계에서는 ImageNet 데이터셋을 사용하여 지도 이미지 분류 작업에서 Vim 모델을 훈련한 다음 사전 훈련된 Vim을 백본으로 사용하여 하위 작업인 의미 분할, 객체 탐지 및 인스턴스 분할과 같은 순차적 시각적 표현 학습을 수행한다.
Transformers와 마찬가지로 Vim은 대규모 비지도 시각 데이터로 사전 훈련될 수 있어 더 나은 시각적 표현을 얻을 수 있다.
가장 타당한 transformer 기반 모델인 DeiT와 비교할 때, Vim은 ImageNet 분류에서 우수한 성능을 달성한다. 또한, 고해상도 이미지에 대한 GPU 메모리 및 추론 시간 면에서 Vim은 더 효율적이다.
<주요 기여>
1. data-dependent global visual context modeling을 위해 양방향 SSM과 위치 임베딩을 통합하는 Vision Mamba(Vim)을 제안함
2. attention이 필요하지 않은 Vim은 ViT와 동일한 모델링 능력을 가지며, 제곱 시간 계산 및 선형 메모리 복잡도만 가진다. DeiT보다 2.8배 빠르며, 1248*1248 해상도의 이미지에서 특성을 추출하기 위해 배치 추론을 수행할 때 GPU 메모리를 86.8% 절약한다.
3. Method
3-1. Preliminaries

3-2. Vision Mamba

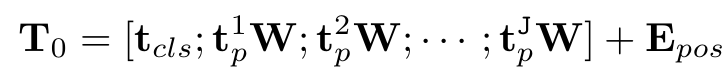
여기서 는 j번째 패치이고, W(,D)는 학습 가능한 투영 행렬이다.
ViT와 BERT에서 영감을 받아, 전체 패치 시퀀스를 나타내는 클래스 토큰을 사용한다. 이를 로 표시한다.
그런다음 토큰 시퀀스 를 Vim 인코더의 l번째 레이어로 보내고, 출력 을 얻는다.
마지막으로, 출력 클래스 토큰 T^L_0을 정규화하고 다층 퍼셉트론(MLP) 헤드에 공급하여 최종 예측 를 얻는다.

vim이 제안되는 vision mamba block이고, L은 레이어 개수이다.
Norm은 normalization layer.
3-3. Vim Block
이 섹션에서는 비전 작업을 위해 양방향 시퀀스 모델링을 통합한 Vim 블록을 소개한다.
입력 토큰 시퀀스 은 먼저 정규화 레이어에 의해 정규화된다.
다음으로, 정규화된 시퀀스를 차원 크기가 E인 x와 z로 선형적으로 투영한다.
그런 다음 x를 전방 및 후방 방향에서 처리한다.
각 방향마다, 먼저 x에 1차원 컨볼류션을 적용하여 x'을 얻는다.
그런다음, x'를 Bo,Co,
3-4. Architecture Details
하이퍼파라미터는 다음과 같다.
L : 블록의 개수
D : hidden state의 차원
E : 확장 차원
N : SSM 차원
ViT와 DeiT를 따라, 우리는 처음에 16*16 커널 사이즈의 projection layer을 통해 겹치지 않는 1차원의 패치 임베딩을 얻는다.
연속적으로, 우리는 L개의 Vim block을 쌓는다.
L은 24, N은 16.
D는 192, E는 384 ( D 384,E 768)
