1. Introduction
ReAct [30], SayCan [1], Toolformer [22], HuggingGPT [23], generative agents [19], 그리고 WebGPT [17]와 같은 최근 연구들은 대규모 언어 모델(LLM) 코어 위에 구축된 자율 의사 결정 에이전트(feasibility of autonomous decision-making
agents)의 실현 가능성을 입증했다. 하지만 이런 접근 방식은 엄청난 파라미터 수를 가진 대규모 모델에 의존하기 떄문에, 이 에이전트를 가르치는 한가지 방법으로써 in-contexts 예제를 사용했다. 강화학습과 경사하강법 같은 전통적인 최적화 방법은 상당한 계산량과 시간을 필요로 하기 때문이다.
따라서 이 논문에서는 대안적 접근방식으로 Reflexion을 제안한다. weight 업데이트하는 대신 언어적 피드백으로 language agent 를 강화하는 것이다.
Reflexion은 환경으로부터 이진 또는 스칼라 피드백을 언어적 피드백으로 변환하여 텍스트 요약 형태로 제공하고, 이를 LLM 에이전트에 추가 컨텍스트로 추가한다.
이러한 self-reflective feedback 은 개선할 구체적인 방향을 제공하여, 더 작업을 수행할 수 있게 한다. (인간이 실수하고 고치는 것처럼)
하지만, 유용한 reflective한 피드백을 생성하는 것은 어려운 일이다. 왜냐하면, 모델이 실수한 위치를 잘 이해해야하고, 개선을 위한 실행 가능한 통찰을 포함하는 요약을 생성할 수 있어야 하기 때문이다. 이를 수행하는 3가지 방법을 탐구한다.
1. simple binary environment feedback
2. pre-defined heuristics for common failure cases
3. self-evaluation such as binary classification using LLMs (decision-making) or self-written unit tests (programming)
Reflextion은 전통적인 강화 학습 접근 방식과 비교하여 여러 장점을 가진다.
1) LLM의 finetuning을 필요로 하지 않아 가볍다
2) 스칼라 또는 벡터 보상과 비교하여 보다 세분화된 형태의 피드백(ex: 동작에 대한 특정 변경)을 가능하게 하고, 이러한 보상은 정확한 credit assignmnet을 수행하게 한다.
3) 컴파일러 및 인터프리터와 같은 외부 도구를 효과적으로 사용하는 방법을 가르치기 위한 프로그래밍 작업에서 실험을 수행한다.
2. Related work
2.1 Reasoning and decision-making
Self-Refine은 자기평가를 통해 세대를 향상시키는 반복적인 프레임워크를 사용한다. 이러한 자가평가 단계는 " 이 생성을 어떻게 더 긍정적으로 작성할 수 있을까"와 같은 주어진 작업 제약 조건에 의존한다. 이는 효과적이지만, 단일 세대 추론 작업에 한정되어 있다.
- [Automatic prompt optimization with" gradient descent" and beam search]는 비슷한 의미론적 프롬프트 작성 최적화를 수행하지만 single-generation task에 한정되어 있다.
- [ Refiner: Reasoning feedback on intermediate representations.]은 추론 응답을 개선하기 위해 중간 피드백을 제공하기 위해 평가 모델을 finetuned한다.
- [ Decomposi
tion enhances reasoning via self-evaluation guided decoding.]스토개스틱 빔 탐색을 사용하여 보다 효율적인 의사 결정 검색 전략을 수행한다.
이 논문에서는 이러한 개념들 중 일부가 자가반영을 통해 강화될 수 있음을 보여준다.
이는 자가반영적 경험의 지속적인 기억을 구축하여 에이전트가 자신의 오류를 식별하고 시간이 지남에 따라 그 오류에서 배울 수 있는 교훈을 자가 제안할 수 있도록 한다.
2.2 Programming
3. Reflexion : reinforcement via verbal reflection
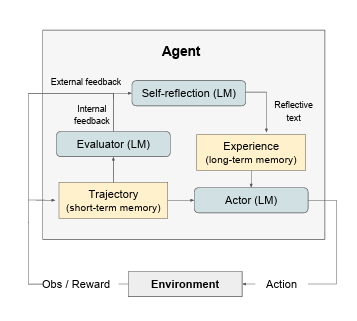
Reflexion을 위한 모듈식 정형화를 개발하였다. 이를 위해 3가지 모델을 사용한다.
1. 텍스트와 액션을 생성하는 Actor 모델을 Ma로 표시
2. 출력을 점수화하는 Evaluate모델을 Me로 표현
3. 자가 개선을 위해 Actor에게 도움이 되는 언어적 보강을 생성하는 Self-Reflection 모델을 Msr로 표시.
이 각 모델들이 Reflexion 프레임워크 내에서 협력적으로 작동하여 오류 식별과 구현 개선 사이의 간극을 메우는 방법을 설명한다.
3.1 Actor
Actor은 특정하게 프롬프트된 LLM을 기반으로 구축된다.
이 LLM은 상태 관측값에 따른 필요한 텍스트와 행동을 생성하도록 특정하게 프롬프트 되어있다.
전통적인 정책 기반 강화학습 설정과 유사하게, 시간 t의 현재 policy 로부터 액션 또는 생성 를 샘플링하고, 환경으로부터 관측값 를 받는다.
Chain of Thought 및 ReAcT를 포함하여 다양한 Actor 모델을 탐색한다.
이러한 다양한 생성 모델은 Reflexion 프레임워크 내에서 텍스트 및 액션 생성의 다른 측면을 탐색하여 성능과 효과에 대한 유용한 통찰력을 제공한다.
또한, 이 에이전트에 추가적인 문맥을 제공하는 메모리 구성 요소 mem을 추가한다.
3.2 Evaluator
Evaluator은 Actor가 생성한 출력의 품질을 평가하는 역할을 한다.
이는 생성된 경로(trajectory)를 입력으로 받고, 주어진 작업 문맥 내에서의 성능을 반영하는 보상 점수를 계산한다.
semantic place에서 적용되는 효과적인 가치 및 보상 함수를 정의하는 것은 어렵기 때문에, 여러 가지 변형의 Evaluator모델을 조사한다.
- 추론 작업 : 예상 솔루션과 근접하게 생성된 출력을 보장하는 정확도 일치(exact match, EM)평가에 기반한 보상함수를 탐구
- 의사결정 작업 : 특정 평가 기준에 맞춘 사전 정의된 휴리스틱 함수를 사용한다.
- 의사결정 및 프로그래밍 작업에 대한 보상: LLM 자체의 다른 인스턴스화를 Evaluator로 사용하는 실험 진행
3.3 Self-reflection
LLM으로 인스턴스화된 Self-reflection 모델은 미래 시행을 위한 유용한 피드백을 제공하기 위해 중요한 역항르 한다. 이 모델은 이진 성공상태(성공/실패)와 같은 희박한 보상 신호, 현재 경로 및 영구적인 메모리 mem 을 고려하여 세밀하고 구체적인 피드백을 생성한다.
스칼라 보상보다 더 정보를 많이 제공하는 이 피드백은 에이전트의 memory에 저장된다.
예를 들어, 다단계 의사 결정 작업에서 에이전트가 실패 신호를 받을 때,
특정작업 가 이후에 잘못된 작업 와 로 이어졌다는 것을 추론할 수 있다.
그렇다면, 에이전트는 다른 작업 를 취해야 했고, 그러면 와 로 이어졌을 것이라고 추론할 수 있고, 이 경험을 메모리에 저장한다.
이후 시행에서는 에이전트가 과거의 경험을 활용하여 t시점에서의 의사 결정 방식을 조정할 수 있다. 이러한 반복저인 과정은 시행, 오류, 자가 반성 및 지속적인 기억을 통해 에이전트가 정보를 제공하는 피드백 신호를 활용하여 다양한 환경에서 빠르게 의사 결정 능력을 향상시킬 수 있도록 한다.
3.4 Memory
Reflexion 프로세스의 핵심 구성요소는 단기 및 장기 기억의 개념이다.
추론 시에 Actor는 단기 및 장기 기억에 의존하여 결정을 내린다.
이는 인간이 최근의 세부적인 내용을 기억하면서도 장기 기억에서 정제된 중요한 경험을 떠올리는 방식과 유사하다.
RL setup에서는 경로 history가 단기 기억으로, Self-Reflection의 출력이 장기기억을 저장된다. 이 두가지 기억 구성 요소는 특정한 문맥을 제공하는데 함께 작용하며 동시에 여러 번의 시행에서 얻은 교훈에 영향을 받는다.
이는 Reflexion이 다른 LLM 행동 선택 작업보다 우위에 있는 중요한 장점이다.
3.5 The Reflexion process
Reflexion은 반복적인 최적화 과정으로 정형화된다.
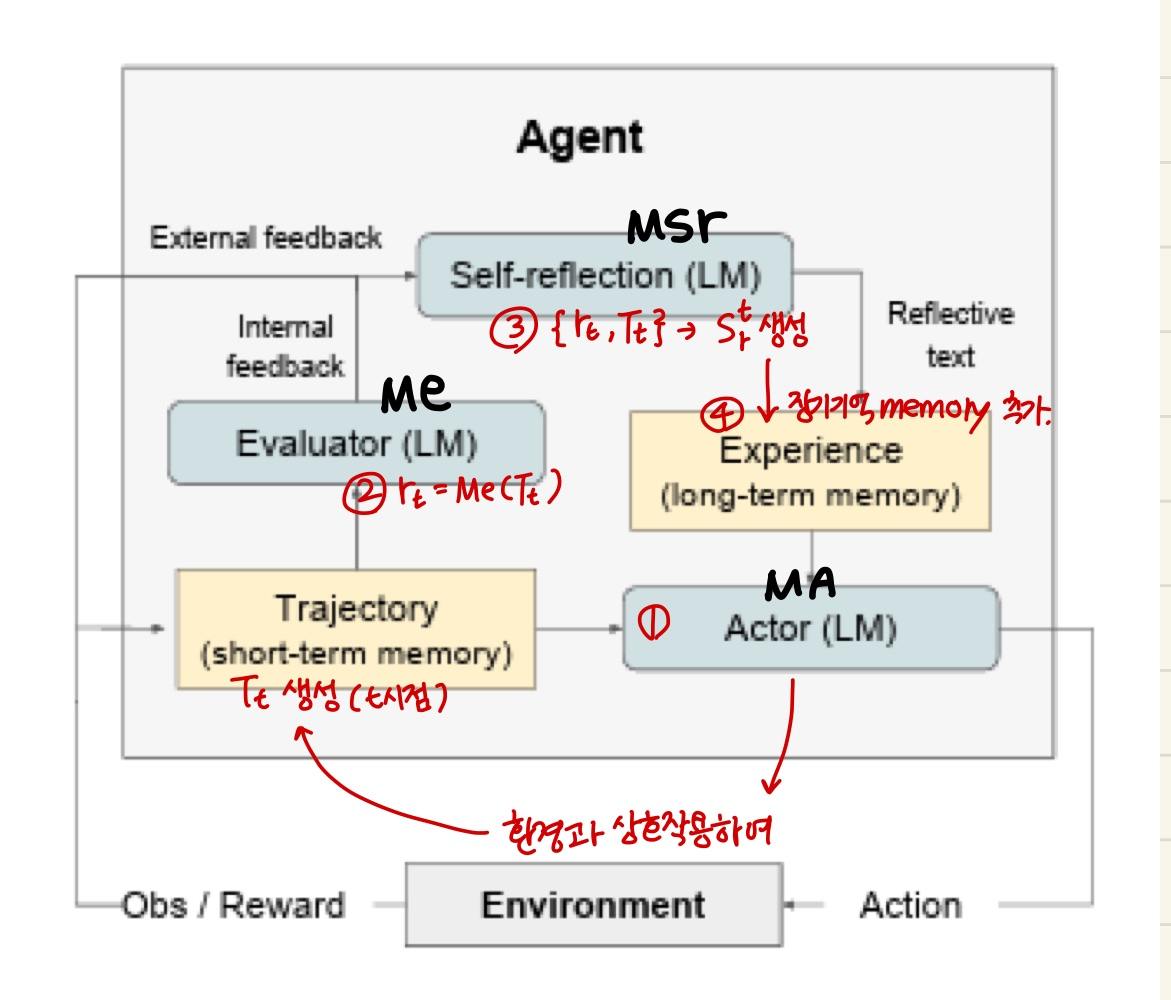
- Actor은 환경과 상호작용하여 경로 을 생성한다.
- Evaluator는 계산된 점수 을 생성한다.
는 시행 t의 스칼라 보상으로, 과제별 성능이 향상됨에 따라 향상된다. - 첫번째 시행이후, LLM이 개선에 사용할 수 있는 피드백 형태로 을 강화하기 위해, Self-Reflection 모델은 {,}의 집합을 분석하여 요약 을 생성한다.
은 시행 t에 대한 언어적 경험 피드백이다. - Actor, Evaluator 및 Self-Reflecion 모델은 루프내에서 시행을 통해 함께 작동하여 Evaluator 가 를 올바르다고 판단할때까지 계속된다.
- 각 시행 t이후, 이 메모리에 추가됨
- 실제로 우리는 mem을 최대 저장 경험의 수, Ω로 제한합니다(보통 1-3으로 설정) max context LLM 제한을 준수합니다.
