Introduction
논문 제목이 faster로 시작한다. 더 빠른, 즉 성능을 향상시켰다는 말이다. 그렇다면 그 이전의 덜 빠른 모델, 그리고 빠르지도 않은 원형 모델이 존재할 것이다. R-CNN과 fast R-CNN에 대해 정리한 뒤, 이를 보완한 faster R-CNN에 대해서 알아보자.
Background
one stage vs two stage
image classfication 방법에는 두가지가 있다. one stage와 two stage이다.
one stage의 경우는 input image를 그대로 convolution network에 넣어준다.
two stage는 아래 그림처럼 original image에서 Region proposal 과정을 거쳐 ROI(Region of interest)를 찾고, 이에 대해 convolution network input이 이루어지는 것이다.
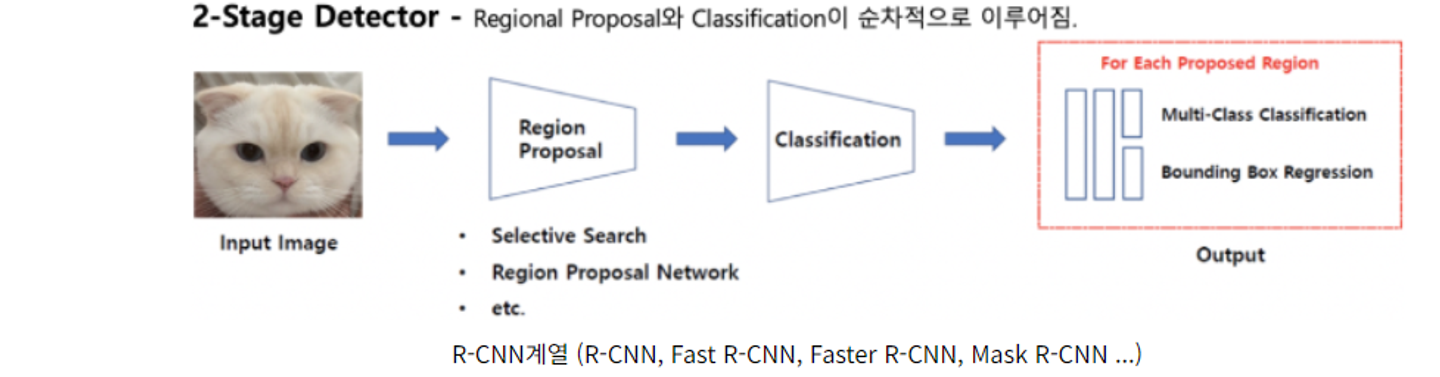
R-CNN이 two-stage의 대표적인 모델이다.
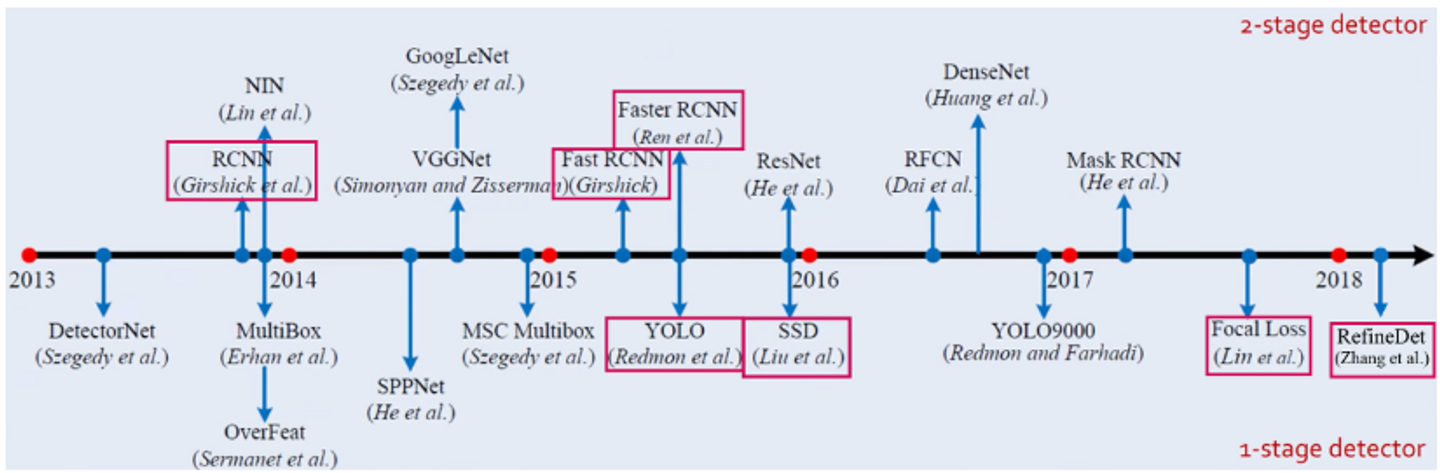
가로 선을 기준으로 위의 모델들이 two-stage모델이고, 아래가 one-stage모델이다.
R-CNN
R-CNN은 위에서 언급한 바와 같이 image classification(detection)을 수행하는 CNN과 localization을 위한 Regional proposal 알고리즘을 연결한 모델이다.
간단하게 R-CNN의 프로세스를 알아보자.
- R-CNN프로세스
-
image를 input받는다.
-
selective 알고리즘에 의해 ROI output 약 2000개를 추출
-
추출한 ROI를 모두 동일 input size로 만들기 위해 wrap과정을 거침. (찌부? 시키는 거랑 같다고 생각)
→ why ? convolution layer의 input size는 고정이지 않지만, 마지막 FC layer에서의 input size는 고정이기 때문에 conv layer에 대한 outputsize도 동일해야한다.
-
2000개의 warped ROI image를 각각 CNN모델에 넣는다.
-
각 convolution 결과에 대해 classification을 진행하여 결과를 얻는다.
-
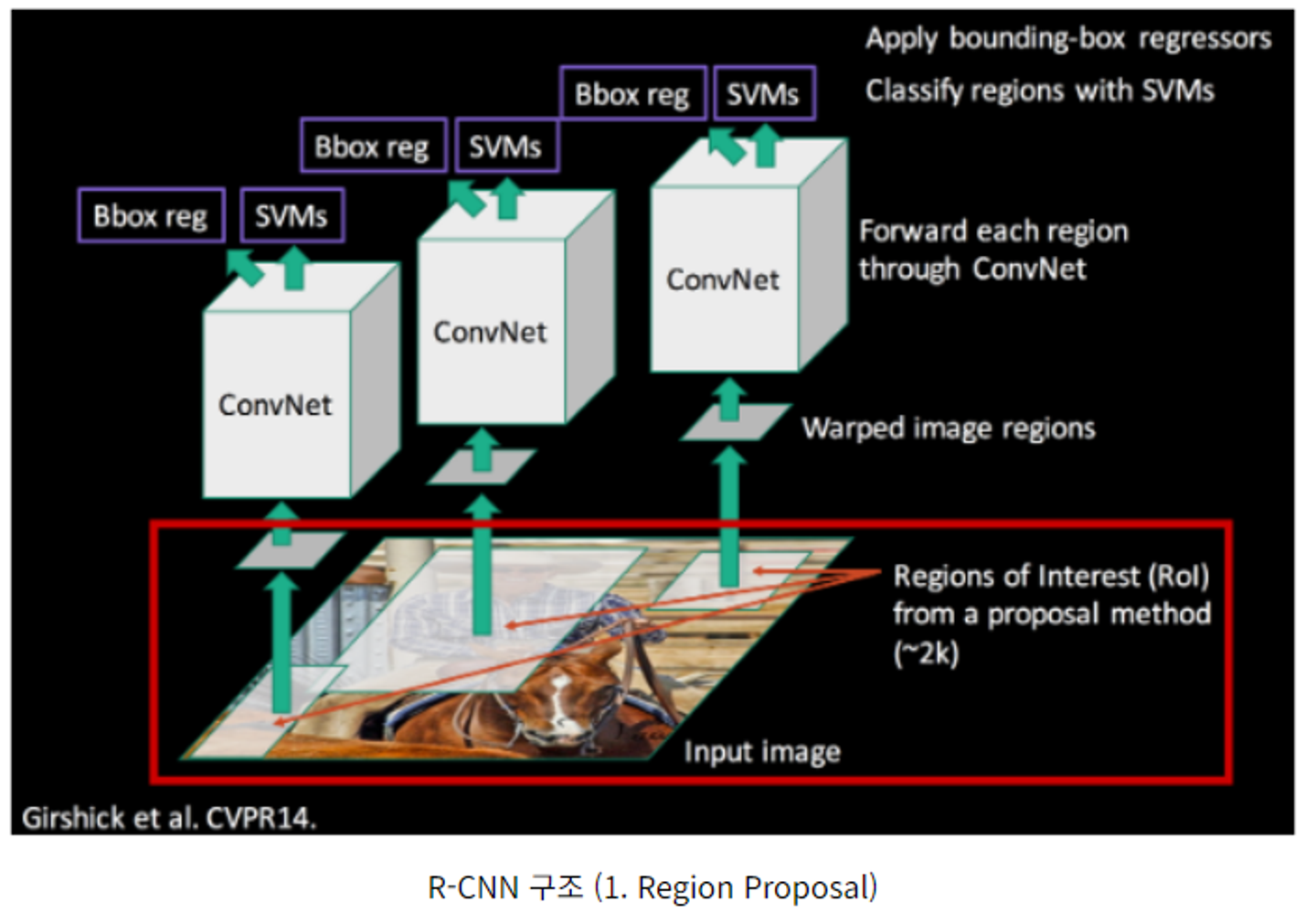
이제 필요한 모듈의 측면에서 설명해보자.
1. Region proposal
ROI를 찾는 방법이다. 원래 사용하던 방식은 sliding window방식이다.
말그래도 window를 슬라이드 하면서 크기와 비율을 임의로 마구 바꾸면서 모든 영역을 탐색하는 것이다. 당연히 이는 비효율적이다.
그래서 여기서 사용한 방식은 selective search이다.
색감, 질감, 영역 크기등을 이용해 non-object-based segmentation을 수행하여 수많은 area를 만들고, 이를 bottom up방식으로 small segmented areas들을 합쳐서 더 큰 segmented area들을 만든다.
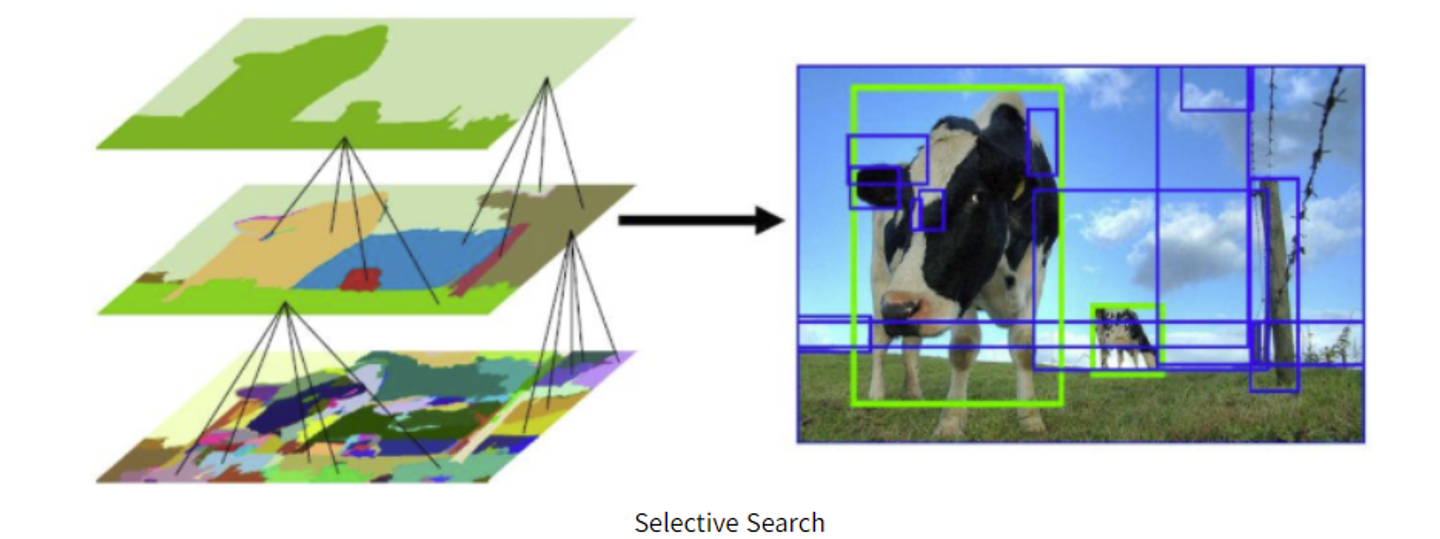
이렇게 하여 총 2000개의 ROI를 만든다.
2. CNN
위에서 만든 ROI를 wrap작업을 통해 모두 224*224크기로 넣어 CNN에 넣는다. 여기서 CNN은 AlexNet 구조이다(거의 비슷).
최종적으로 4096 - dimentional feature vector을 뽑아내고, 이를 통해 고정길이 Feature Vector을 만들어낸다.
3. SVM
cnn을 통해 feature가 추출되면, Linear SVM을 통해 classification을 진행한다.
SVM은 cnn으로부터 추출된 각각의 feature vector들의 점수를 class별로 매기고, 객체인지 아닌지, 객체라면 어떤 객체인지등을 판별하는 역할을 한다.
3-1. Bounding Box Regression
selective search로 만든 bounding box는 정확하지 않으므로 물체를 정확히 감싸도록 조정해주는 bounding regression이 존재.
하나의 박스를 다음과 같이 표기
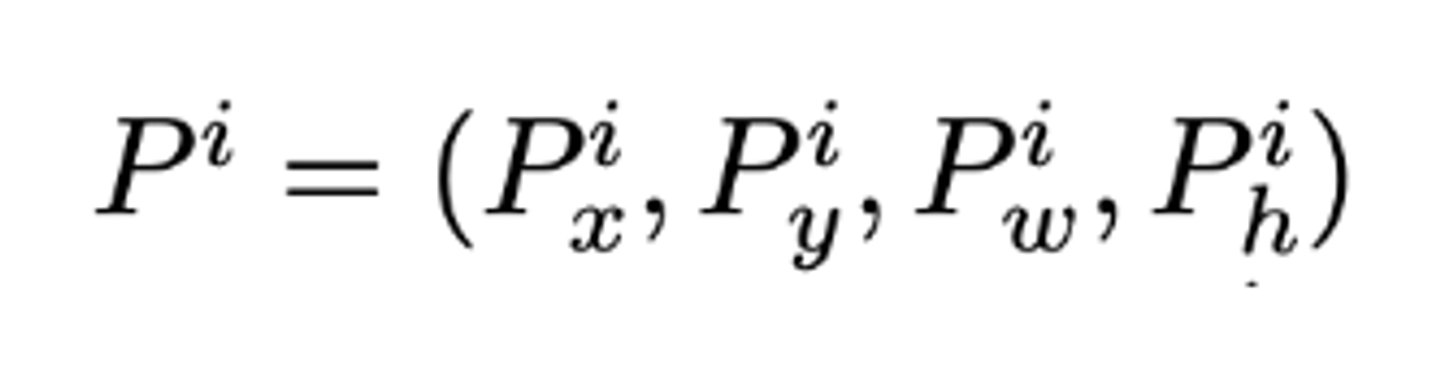
ground truth 에 해당하는 박스도 다음과 같이 표기
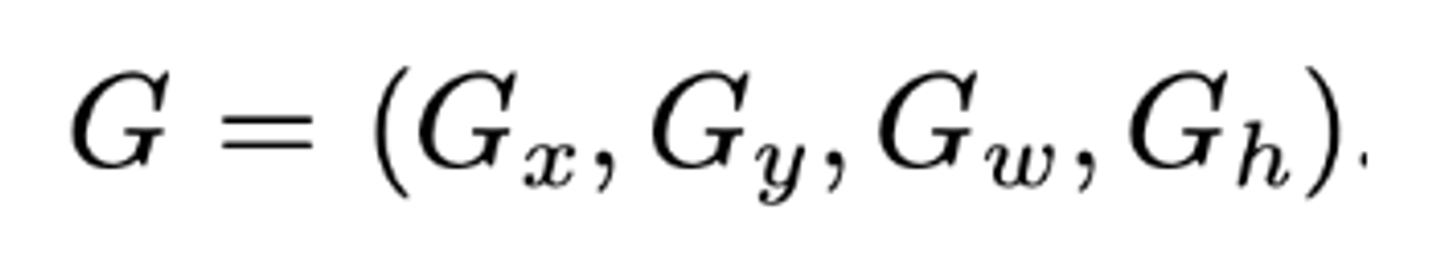
즉 우리는 현재 P상태의 박스를 G에 최대한 가깝도록 이동시키는 함수를 구하고 학습시켜야한다!
박스의 위치가 인풋으로 들어왔을때, 가로, 세로, 너비, 높이(x,y,w,h)를 각각 이동시켜주는 함수는 다음과 같이 표기한다.
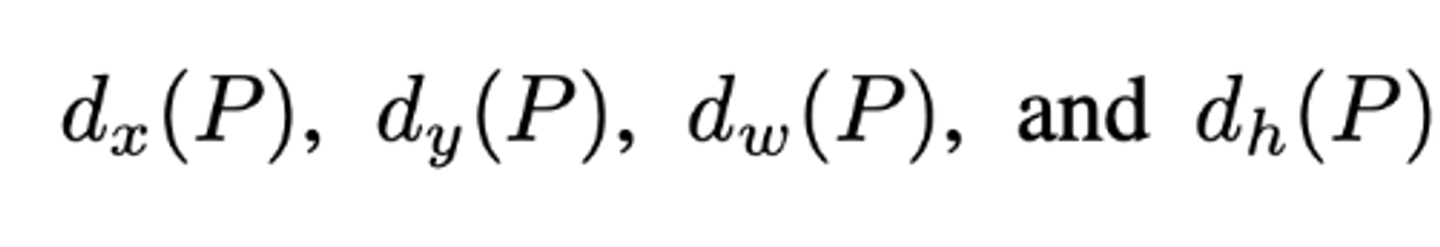
즉 함수 d뭐시기를 알아야 함.
이 이동값에 따라 변경되는 값은 다음과 같은 식을 통해 이루어진다.
x,y는 점이기 때문에 이미지 크기에 상관없이 위치만 이동시키면 되지만, 너비와 높이는 이미지의 크기에 비례하여 조정해야한다.
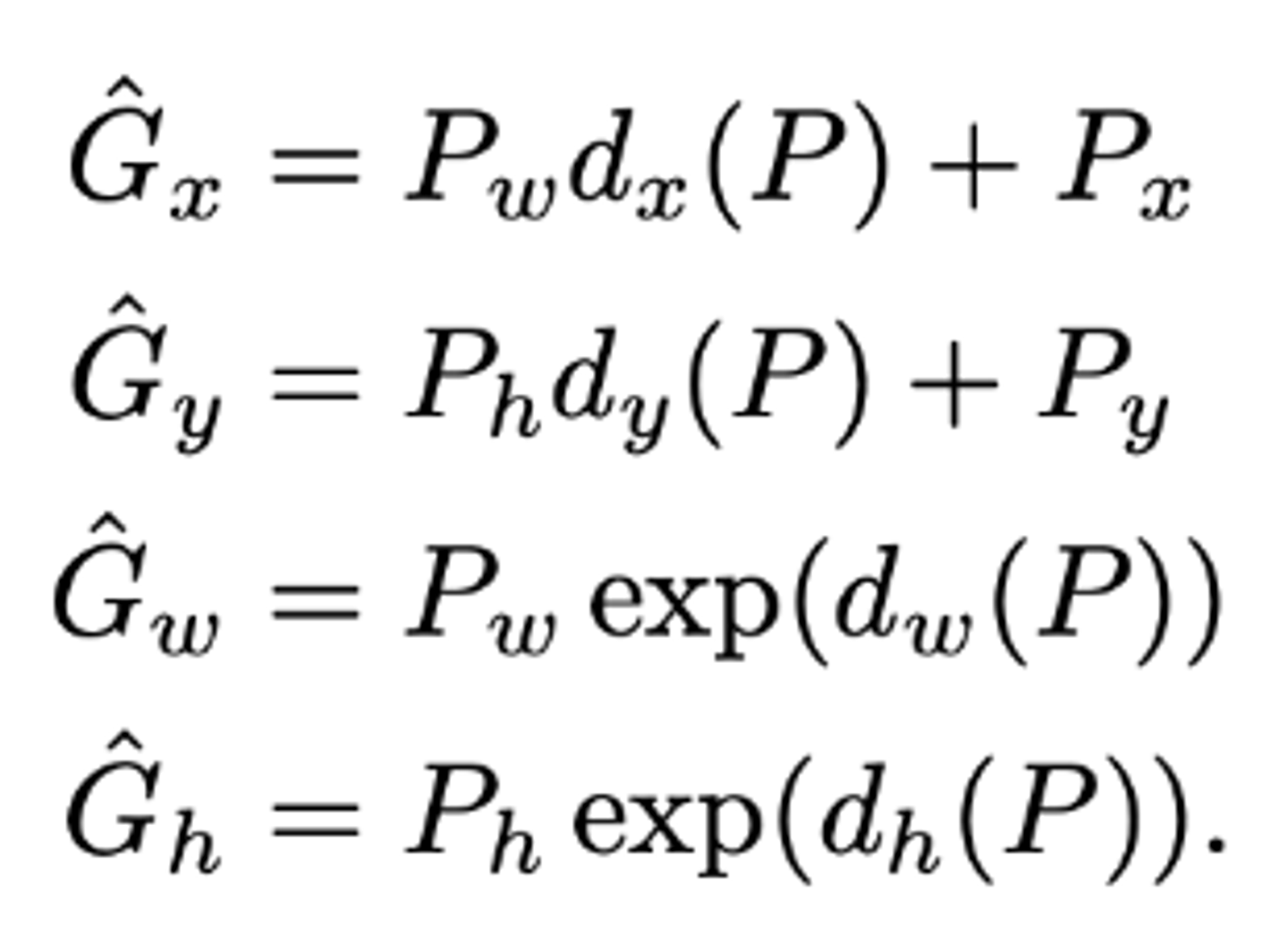
논문에서는 이 d함수를 구하기 위해 앞서 CNN을 통과할때 다섯번째 pooling 레이어에서 얻어낸 특징 벡터를 사용한다.
그리소 함수에 학습 가능한 웨이트벡터(w)를 주어 계산한다.
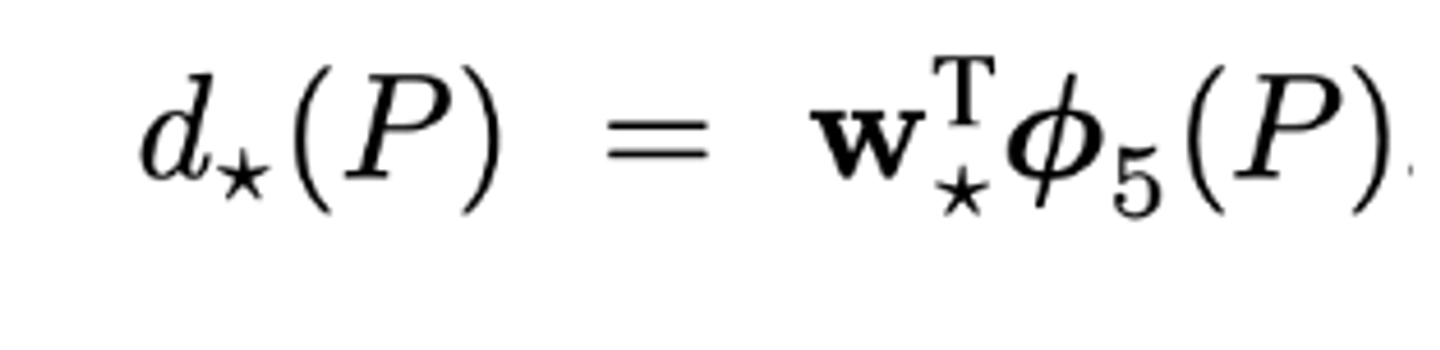
웨이트를 학습시킬 loss function은 다음과 같다.
일반적인 MSE함수에 L2규제를 추가한 형태이다. 논문에서는 람다를 1000으로 설정한다.
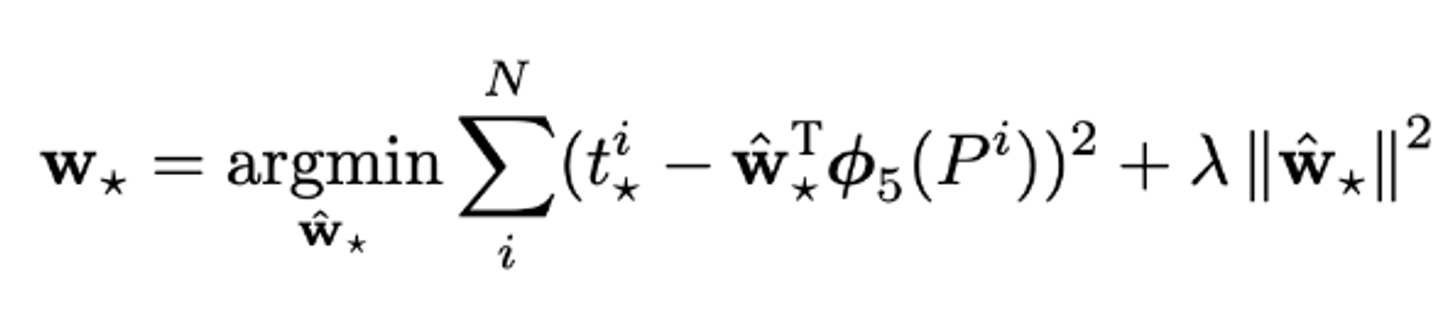
여기서 t는 P를 G로 이동시키기 위해서 필요한 이동량을 의미하며, 이를 식으로 나타내면 아래와 같다.
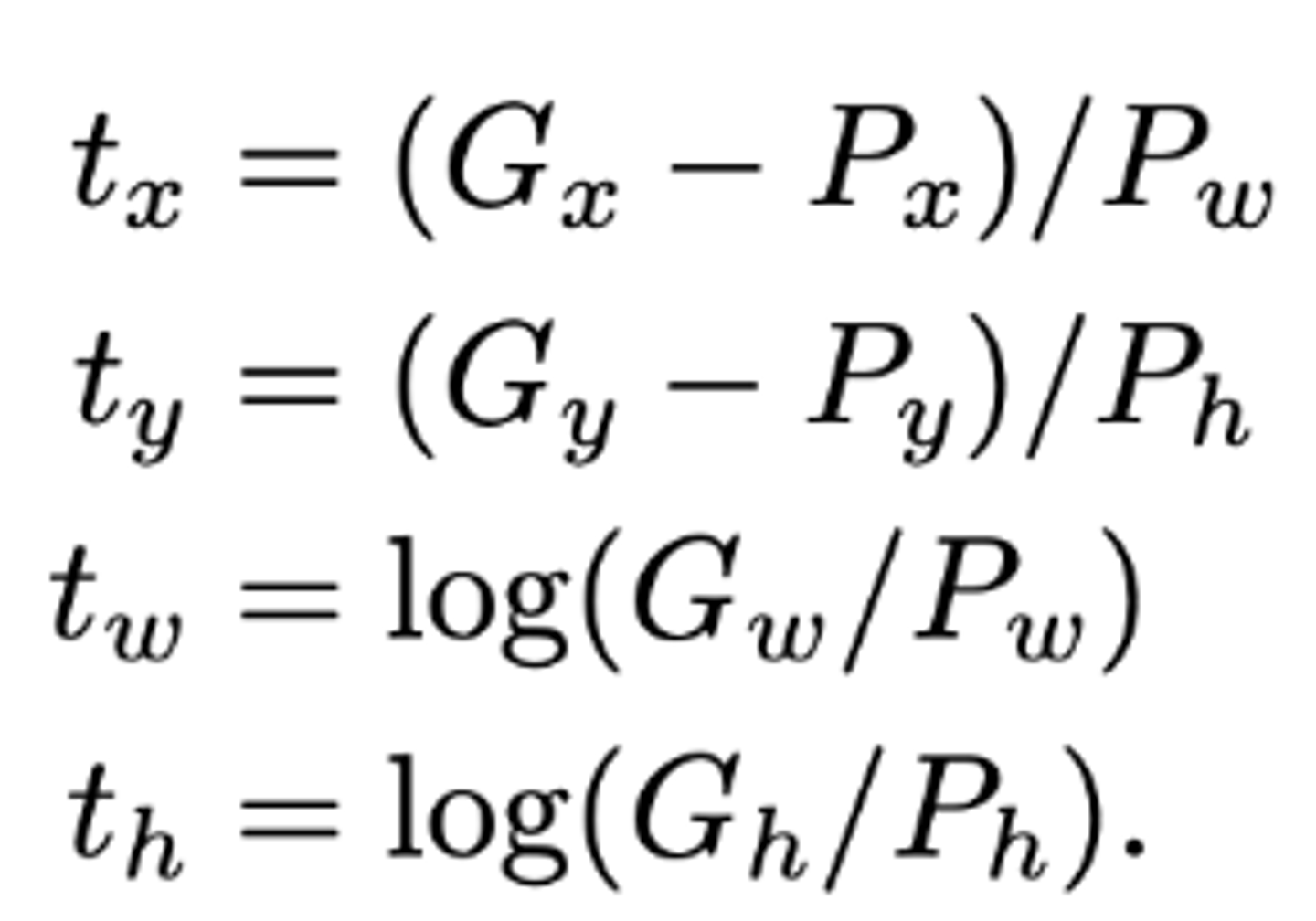
R-CNN의 단점
R-CNN의 단점은 분명하다.
- 2000개의 ROI에 대해서 위에서 언급한 일련의 과정을 각각 모두 거쳐야 한다. 즉, conv 연산을 2000번 거쳐야한다. 수행시간이 매우 느리다.
- End-to- End학습이 진행되지 않는다. 위에서 말한 세 가지 모델이 multi-stage pipelines으로 한번에 학습되지 않는다. 연산이 공유되지 않기 때문에 svm, bounding box regression에서 학습한 결과가 cnn을 업데이트 시키지 못한다. > loss function없음 충격 !
Fast R-CNN
이를 해결하기 위해 등장한 것이 “빠른” R-CNN이다.
fast R-CNN의 가장 큰 특징은 두 가지이다.
- ROI pooling : R-CNN에서 input rol의 크기를 모두 맞춘 행동을 없애고 등장한 것이다.
- End-to- End 학습이 가능하도록 구성
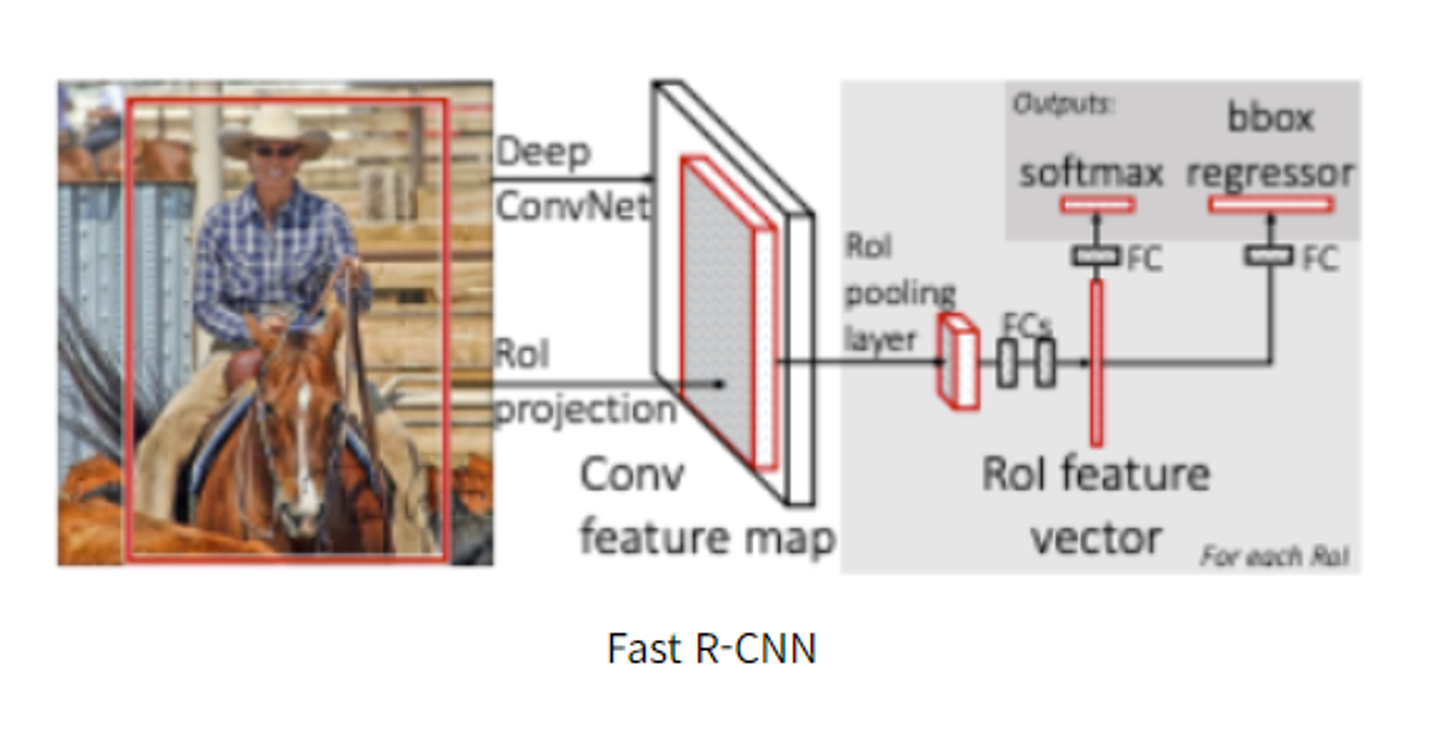
- <Fast R-CNN의 수행과정> 1-1. R-CNN과 같이 selective search를 통해 ROI를 찾는다. 1-2. 전체 이미지를 CNN에 통과시켜 feature map을 추출한다.
-
selective search로 찾았었던 ROI를 feature map크기에 맞춰서 projection시킴.
-
projection시킨 ROI에 대해 ROI pooling을 진행시켜 고정된 크기의 feature vector을 얻는다.
-
feature vector는 FC layrer을 통과한 뒤, 두 브랜치로 나뉨
4-1. 하나는 softmax를 통과하여 ROI에 대해 object classification을 진행
4-2. bounding box regression을 통해 selective search로 찾은 box의 위치를 조정한다.
-
여기서 사용된 중요 아이디어는
FC layer input만이 고정이기 떄문에 이때만 사이즈를 맞추면 된다는 것이다.
(R-cnn에서는 conv들어가기 전부터 사이즈 다 고정시킴)
이를 위해 spatial pyramid pooling(spp)가 제안되었다.
Spatial Pyramid pooling
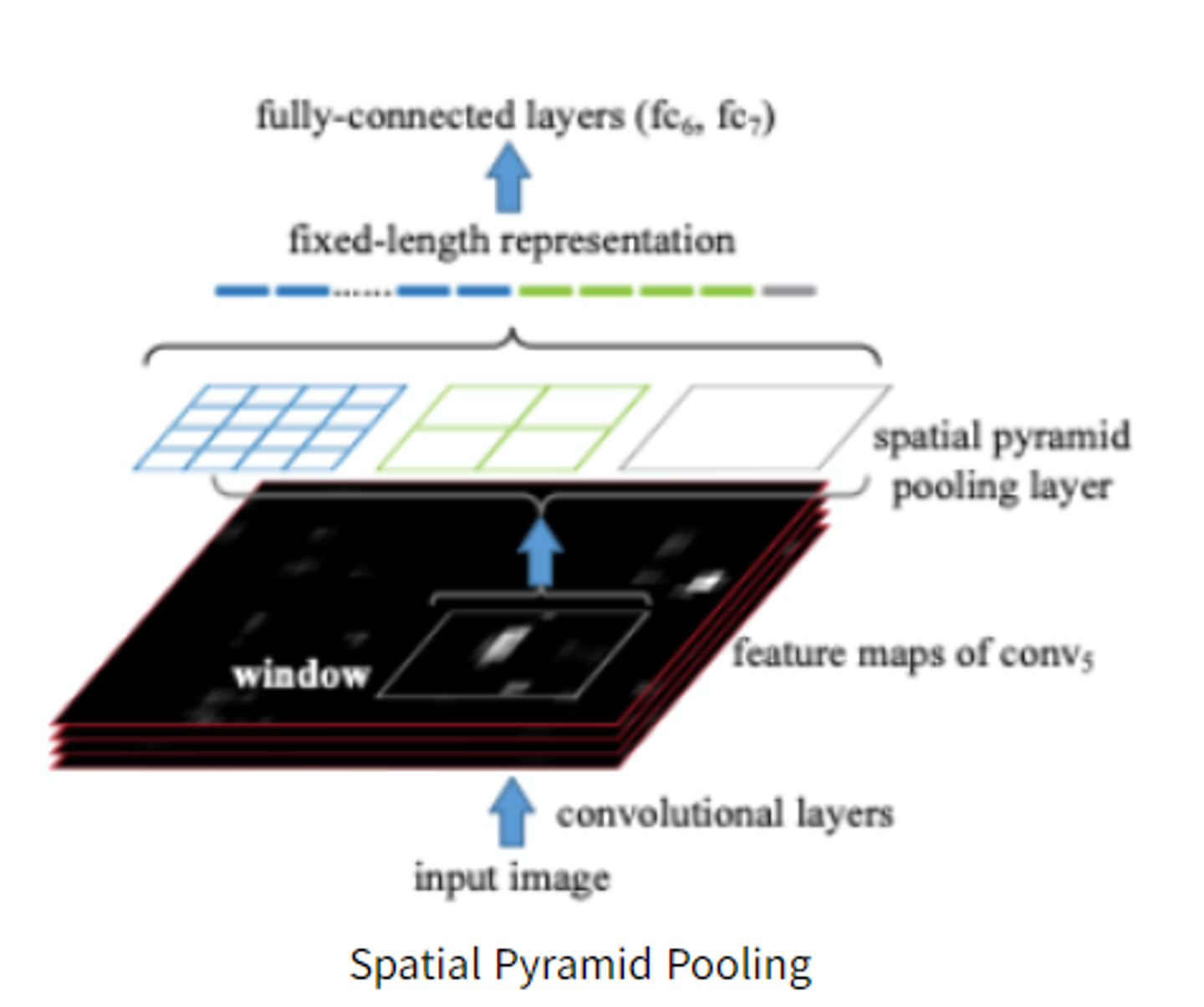
1b74-4755-bcd8-f58f9cb1aff5/6b5f3710-0961-4a14-8e6d-b0969d339a17/Untitled.png)
먼저, 이미지를 cnn에 통과시켜 feature map을 추출한다.
미리 정해진 44, 22, 1*1 영역의 피라미드로 feature map을 나눠준다. (피라미드 사이즈 만큼 max pooling)
각 피라미드 별로 뽑아낸 max 값들을 쭉 이어붙어 고정된 1차원의 벡터를 만들고, 이 것이 FC layer의 input으로 들어간다.
즉, cnn을 통과한 feature map에서 2천개의 ROI를 만들고, ROI마다 sppnet에 집어넣어 고정된 크기의 feature vector를 얻어낸다.
즉, 2천번의 cnn연산이 1번으로 줄어든 것이다. (처음에 feature map 얻을 때 한번)
fast R-CNN에서의 spp 적용 ( ROI Pooling)
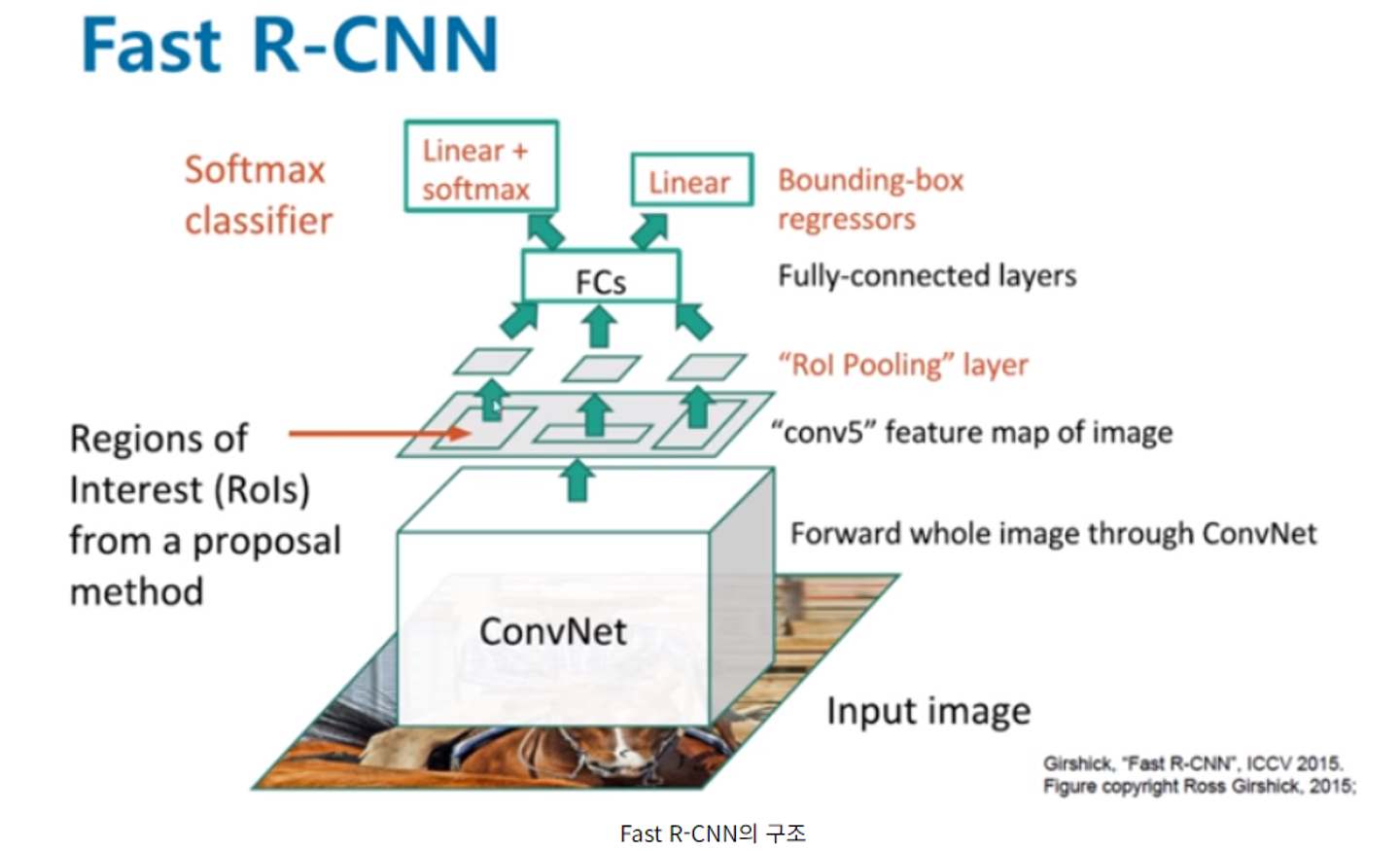
1개의 피라미드를 적용시킨 spp로 구성된다.
피라미드 사이즈는 7*7이다.
ROI의 크기와 상관없이 pooling하는 window와 stride의 크기를 조정하면 같은 크기의 feature map을 얻을 수 있다.
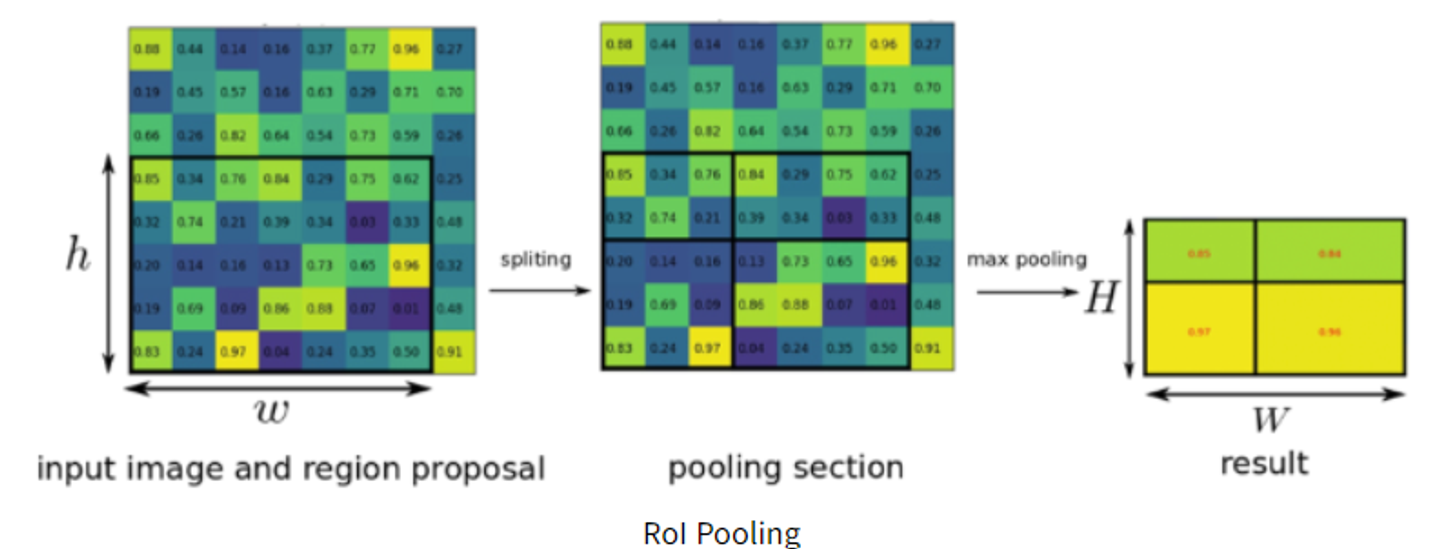
feature map에 투영했던 hw 크기의 ROI는 HW크기의 고정된 feature vector로 변환된다.
이렇게 ROI Pooling을 이용함으로써
“원래 이미지를 CNN에 통과시킨 후 나온 feature map에 이전에 생성한 ROI를 projection시키고, 이 ROI를 FC layer input에 맞게 고정된 크기로 변형할 수 있다. “
End - to - end : Trainable
동일 데이터가 각각 softmax(svm), bbox regression(localization)으로 들어가기에 연산을 공유함
loss function은 다음과 같다.
p : predicted class score
u : True class score
: True box coordinate
v : predicted box coordinate
class 분류 loss 는 cross entropy를 사용.
u가 1이상일때만 regression loss사용. 즉, background class로 분류되었으면, regression loss를 사용하지 않겠다.
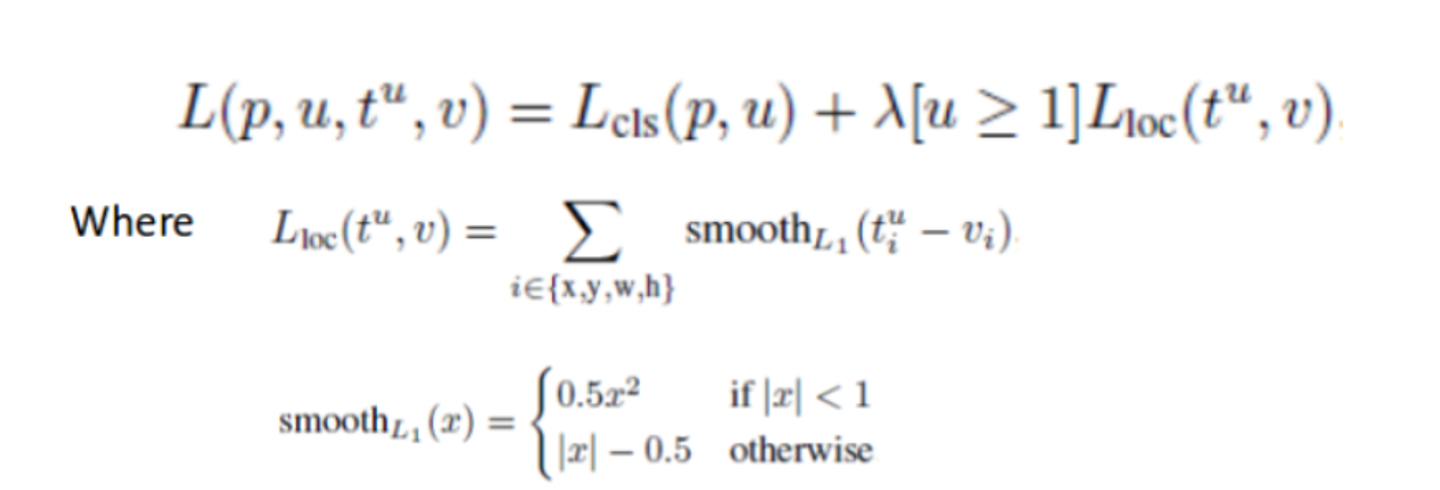
But 문제점 존재.
ROI를 생성하는 selective 알고리즘은 cnn외부에서 진행하기 때문에 이 부분이 bottleneck이다.
그래서 Region proposal도 cnn 네트워크 안에서 같이 진행하자는 것이 faster R-CNN의 아이디어이다.
Faster R-CNN
overview
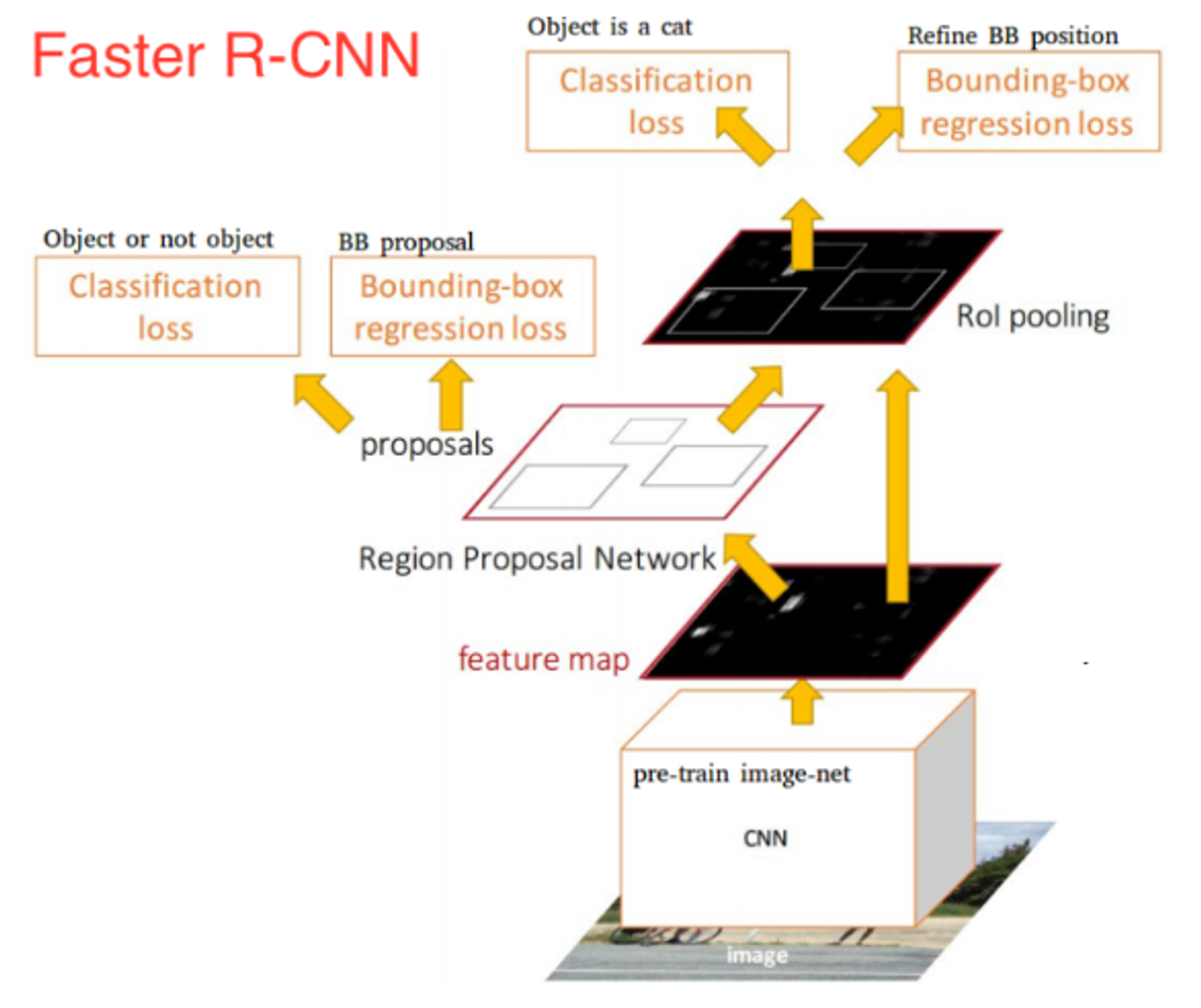
다음 사진과 같이 original image를 cnn에 넣어 생성된 feature map을 바탕으로하여 Region Proposal Network(RPN)를 만든다.
하지만 여기서 주의해야할 것은 생성된 ROI는 feature map에서의 RoI가 아닌 original image에서의 RoI이다.
따라서, original image 위에서 생성된 ROI는 conv feature map의 크기에 맞게 rescaling된다.
RPN
RPN은 원본 이미지에서 region proposals를 추출하는 네트워크입니다. 원본 이미지에서 anchor box를 생성하면 수많은 region proposals가 만들어집니다. RPN은 region proposals에 대하여 class score를 매기고, bounding box coefficient를 출력하는 기능을 합니다.
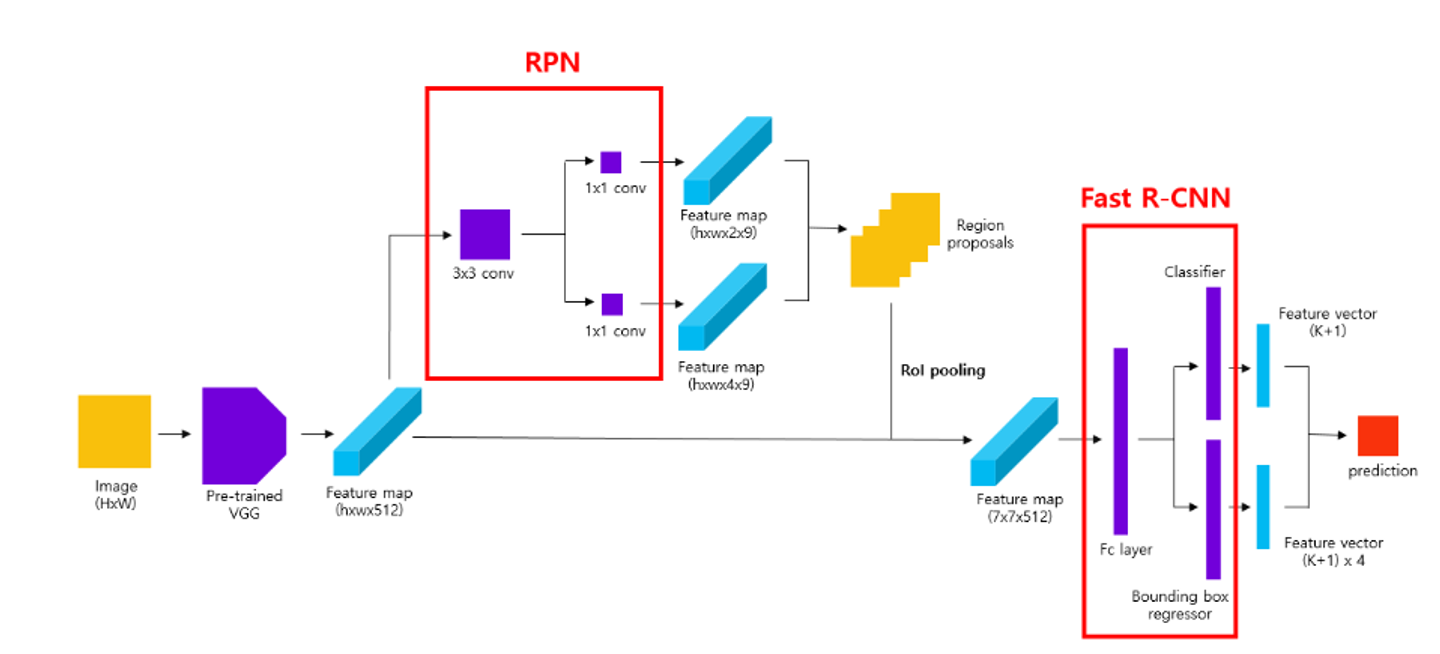
- 원본 이미지를 사전학습된 VGG의 input으로 넣어 feature map을 얻는다.
→ 원본 이미지의 크기가 800800 이며, sub-sampling ratio가 1/100이라고 했을때 88 크기의 feature map이 생성된다. (채널의 수는 512개)
- anchor box 설명 faster R-CNN에서는 selective search를 사용하지 않고, 원본 이미지를 일정 간격의 grid로 나누어 각 grid cell를 bounding box로 간주하여 feature map에 인코딩하는 Dense Sampling 방식을 사용한다. grid는 sub-sampling ratio를 기준으로 grid 한다. 💡 예를 들어 원본 이미지가 800*800이고, sub-sampling ratio가 1/100이면, 얻게 되는 최종 feature map의 크기는 8*8이 된다. 즉, 원본 이미지에 대핸 8*8개 만큼의 bounding box가 생성되고, 이 bounding box는 원본이미지의 100*100만큼의 영역에 대한 정보를 함축한다. 하지만 이렇게 bounding box의 크기를 고정할 경우, 다양한 객체를 포착하지 못할 수 있기 때문에 본 논문에서는 사전에 지정한 서로 다른 크기와 비율의 anchor box( bounding box)를 생성한다. 총 비율 3가지와 3가지 크기로 9가지의 box를 사용한다.
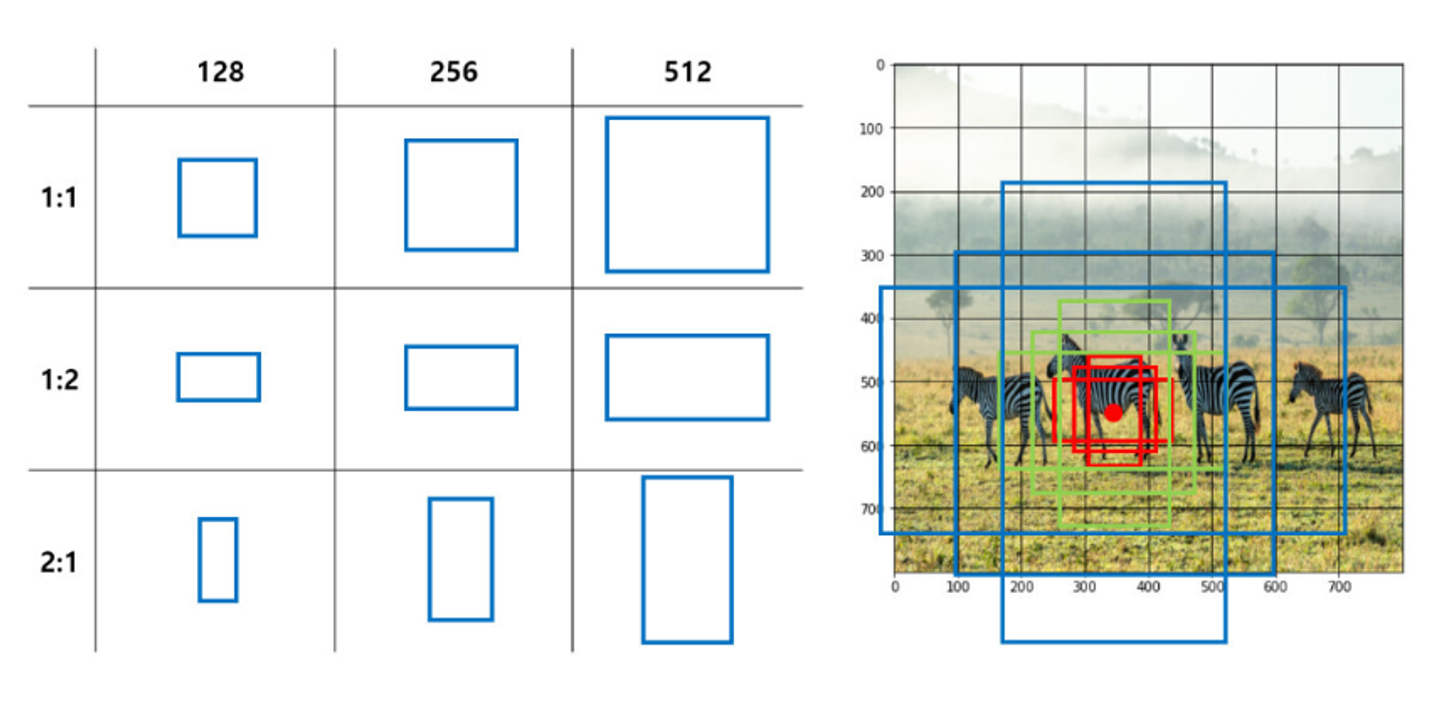
anchor box는 원본 이미지의 각 grid cell을 중심을 기준으로 생성한다. 원본이미지에서 sub - sampling raio를 기준으로 anchor box를 생성하는 기준점인 anchor를 고정한다. 그리고 이 anchor를 기준으로 사전에 정의한 anchor box 9 개를 생성한다.
<aside>
💡 예로, 원본 이미지 크기 600*800, sub- sampling rate=1/16. anchor가 생성되는 수는 600/16 * 800/16=1900이고, anchor box는 총 1900* 9 = 17100개가 생성된다.
</aside>- 위에서 얻은 feature map에 대해 3*3 conv 연산을 적용한다. 이때 feature map의 크기가 유지되도록 padding 추가
→ 88512 feature map에 33연산을 적용해서 88*512개 feature map출력
3-1. class score를 매기기 위해서 feature map에 대해 11 conv연산을 적용함. 이때 출력하는 feature map의 채널 수가 29가 되도록 설정한다. 2(object여부, 이진분류) * 9 (anchor box 9개) 이기 때문이다.
- 1*1 conv 연산 여기서 1*1 conv 는 FC layer와 동일한 역할을 한다.
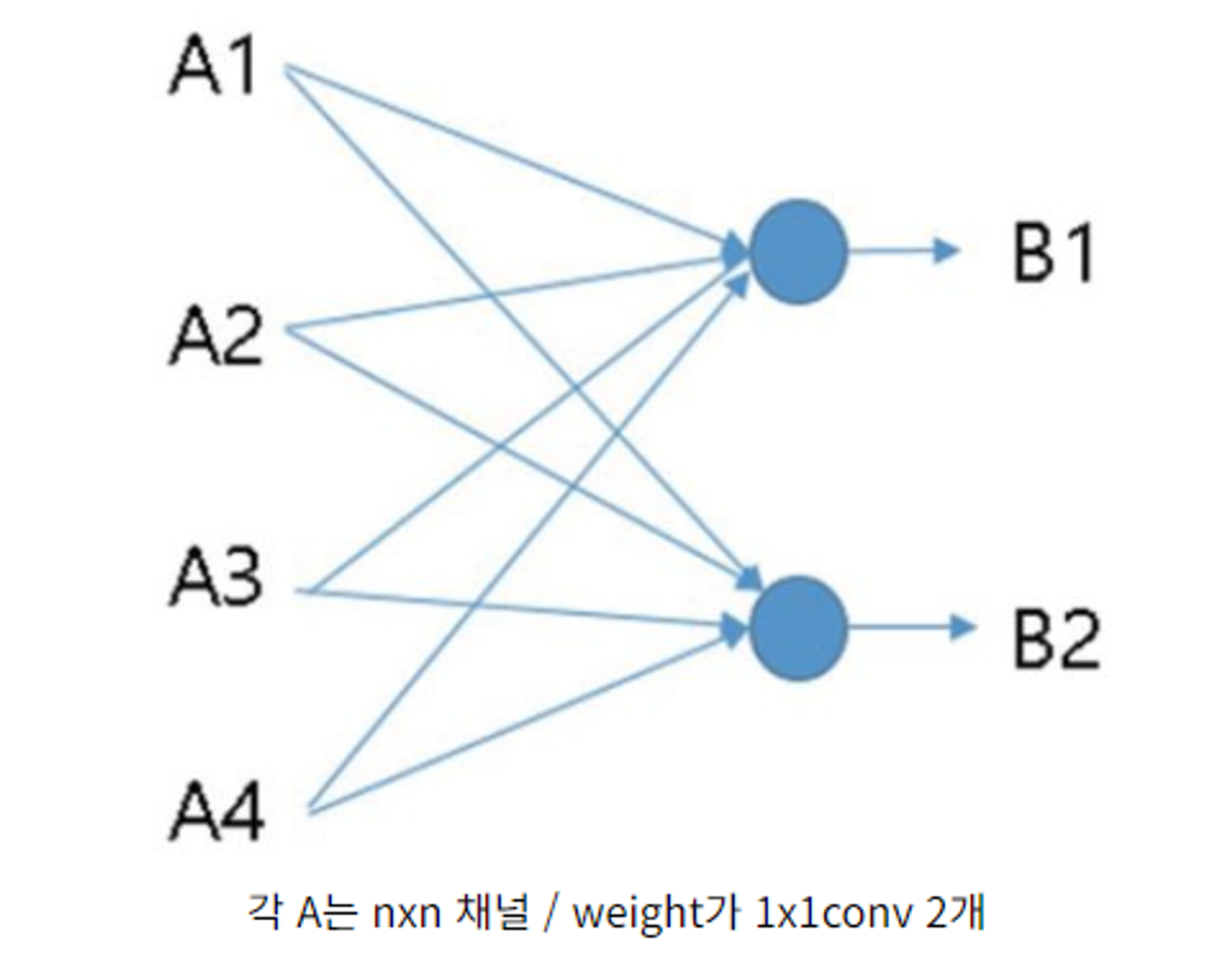
input 차원이 n*n*4라고 할때, 1*1 conv 2개를 이용하면 아래 그림처럼 n*n짜리 4개에 대해서 아래와 같은 연산을 하는 것이다. 3-2. bounding box regression을 얻기 위해 또한 11 conv 연산을 적용한다. 이때 출력하는 feature map의 channel 개수가 4( x,y,w,h) 9( anchor box 개수) 가 되도록 설정한다.
💡 8*8*512크기의 feauture map을 입력받아 8*8*4*9크기의 feature map을 출력한다.
총 88 grid cell마다 9개의 anchor box가 생성되어 총 576(88*9)개의 region proposals가 추출된다.
이후, class score에 따라 상위 N개의 region proposals만을 추출하고, Non maximum supprestion을 적용하여 최적의 region proposals을 Fast R-CNN에 전달한다.
- NMP 한 input image에 여러 객체가 있을 것이고, 그 한 객체당 여러개의 bounding box proposal 값이 나올 것이다. 여기서 한개의 box만을 선정하기 위해서 NMS알고리즘을 사용한다.
- box들의 score을 높은 순서대로 정렬한다 .
- score가 가장 높은 box부터 시작해서 다른 모든 box와 일대일로 다 IoU를 계산해서 0.7이상이면 같은 객체를 탐지한 box로 판단되므로 삭제(score가 더 낮은 것을)
- 이런식으로 하면 각 object별로 가장 높은 box하나 씩만 남게 된다.


Training Faster R-CNN
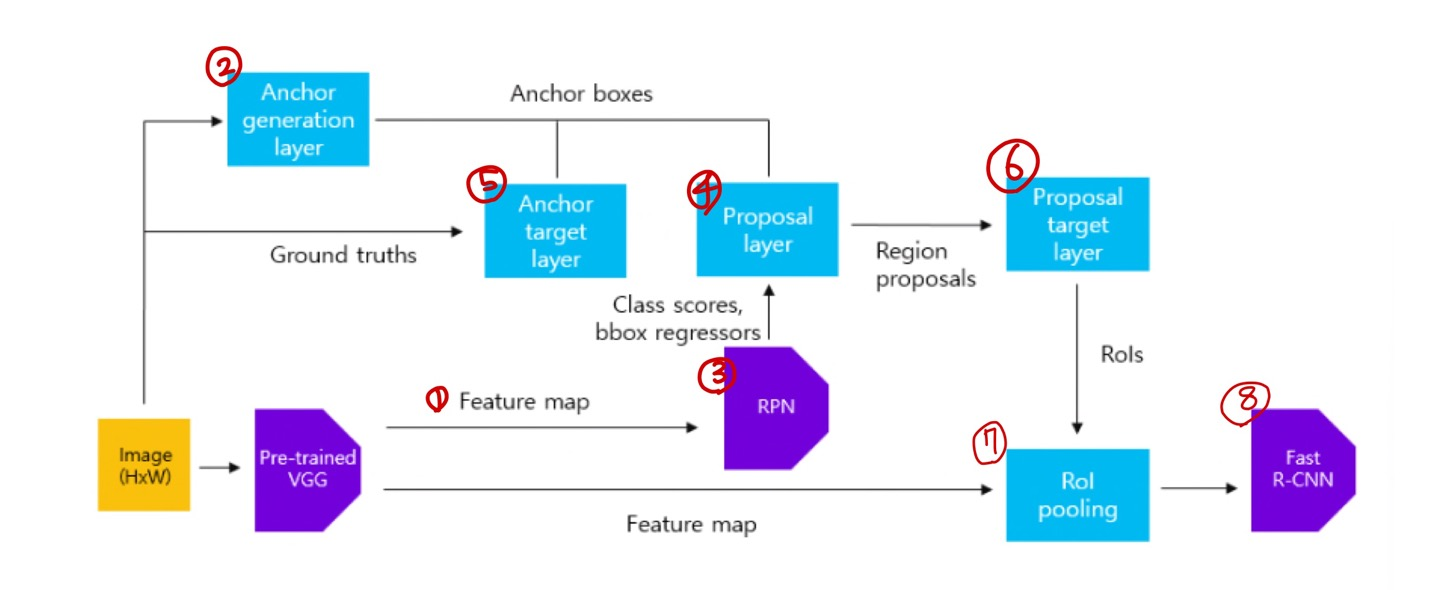
Fast R-CNN 모델의 학습 과정을 살펴보자.
각 그림의 번호와 아래 텍스트의 번호가 일치합니다.
(1,2 번 순서대로…라고 보기에는 조금 애매)
-
feature extraction
사전학습된 VGG 16모델에 8008003 크기의 원본 이미지를 입력하여 5050512 크기의 feature map을 얻는다. sub sampling ratio는 1/16이다.
-
-
generate anchor box( Anchor generation layer)
region proposals를 추출하기에 앞서, 원본 이미지에 대한 anchor box를 생성하는 과정이 필요하다. 원본 이미지 크기에 sub - sampling ratio(1/16)을 곱한 만큼의 grid cell이 생성되며, 이를 기준으로 각 grid cell 마다 9개의 anchor box를 생성한다. 즉, 50509=22500개의 anchor box가 생성된다.
-
- 3.RPN(class score, bbox regressor) RPN은 VGG 16으로 부터 feature map을 입력받아 anchor에 대한 class score, bounding box regressor을 반환한다.
- 4.Region proposal (Proposal layer) 2번에서 생성된 anchor box와 RPN에서 반환된 class socre과 bounding box regressor을 사용하여 region proposal을 추출하는 작업을 수행한다. 여기서 NMP(Non maximum suppression)을 적용한다. 이를 통해 상위 n개의 region proposal이 뽑히게 된다.
- select anchor for training RPN(Anchor target layer)
anchor target layer의 목표는 RPN이 학습하는데 사용할 수 있는 anchor를 선택하는 것이다. 먼저, 2번에서 생성한 anchor box중 원본 이미지의 경계를 벗어나지 않는 anchor box를 선택한다. 그 다음 positive/negative 데이터를 sampling해준다. (positive은 객체가 존재, negative은 객체가 존재하지 않음) 전체 anchor box중에서 1) ground truth box와 가장 큰 IOU값을 가지는 경우 2) ground truth box와의 IOU값이 0.7이상인 경우, 둘중에 하나에 해당하는 box를 positive sample로 선정한다. 반대로 IOU값이 0.3 이하인 경우에는 negative sample로 선정한다. 0.3~0.7 사이의 anchor box는 애매하므로 무시한다. 이러한 과정을 통해 RPN을 학습시키는데 사용할 데이터셋을 구성한다.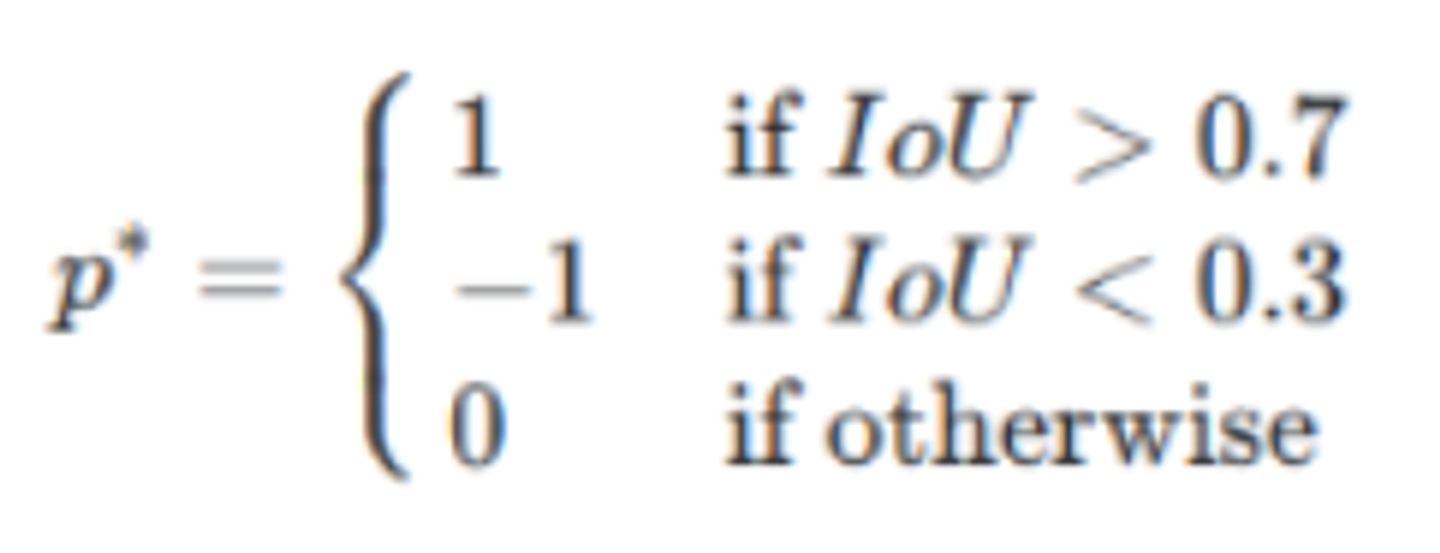
- select anchor for training RPN(Anchor target layer)
-
select anchors for training Fast R-CNN(Proposal Target layer)
proposal target layer의 목표는 proposal layer에서 나온 region proposals 중에서 Fast R-CNN 모델을 학습시키기 위한 유용한 sample을 선택하는 것이다. 여기서 선택된 region proposal는 1번에서 출력된 feature map에 ROI pooling을 수행하게 된다. (ROI pooling의 과정은 Fast R-CNN과 같다) 먼저, region proposals와 ground truth box와의 IOU를 계산하여 0.5이상일 경우 positive, 0.1~0.5 사이일 경우 negative sample로 label된다.
-
-
Max pooling(ROI pooling)
원본이미지에서 얻은 feateure map과 6번의 과정을 통해 얻은 sample을 사용하여 ROI pooling을 수행한다. 이를 통해 고정된 크기의 feature map이 출력된다.
-
- 8.Train Fast R-CNN by Multi-task loss 나머지 과정은 Fast R-CNN모델의 동작 순서와 동일하다. feature map을 fc layer에 입력하여 4096 크기의 특징 벡터를 얻는다. 이후, 특징 벡터를 classifier 와 bounding box regressor에 입력하여 각각 K+1, (K+1)*4 (class의 수가 k) 크기의 특징 벡터를 출력한다.
Alternating Training
논문의 저자는 Faster R-CNN 모델을 학습시키기 위해 RPN과 Fast R-CNN을 번갈아가며 학습시키는 Alternation Training방법을 사용한다.
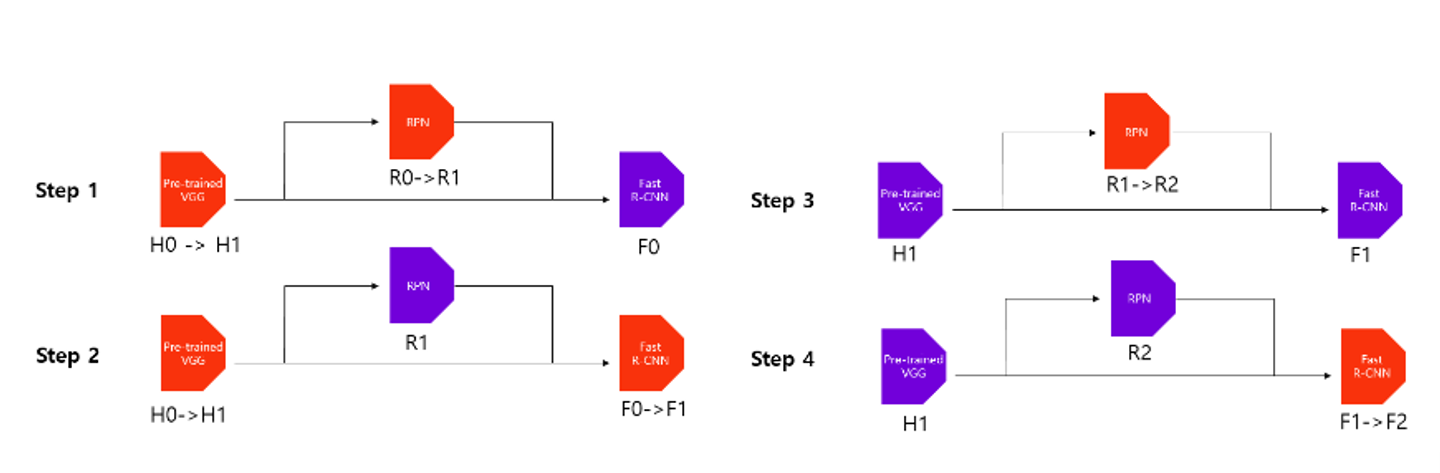
- 먼저, anchor generation layer에서 생성된( 위의 학습과정에서 2번과정) anchor box와 원본 이미지의 ground truth box를 사용하여 anchor target layer에서 RPN을 학습시킬 positive/negative 데이터셋을 구성한다. (5번 과정) 이를 활용하여 RPN을 학습시킨다. 이때, 사전학습된 VGG16또한 학습된다.
- anchor generation layer에서 생성한 anchor box와 학습된 RPN에 원본 이미지를 입력하여 proposals layer에서 region proposal를 추출한다.( 4번과정) 이를 proposal target layer(6번과정)에 전달하여 Fast R-CNN 모델에 학습시킬 positive/negative 데이터셋을 구성한다. 이를 활용하여 Fast R-CNN을 학습시킨다. 사전학습된 VGG16도 학습된다.
- 앞서 학습된 RPN과 Fast R-CNN에서 RPN에 해당하는 부분만 학습(fine-tuning)시킨다. 세부적인 학습과정은 1번과 같다. 이때, 사전학습된 VGG16은 고정(freeze)한다.
- 학습시킨 RPN(3번)을 활용하여 추출한 region proposal를 활용하여 Fast R-CNN을 학습(fine-tuning)시킨다. 이때, RPN과 VGG16은 고정이다.
Detection
실제 detection시에는(class분류)에서는 anchor target layer와 proposal target layer는 사용하지 않는다. 이 두 층은 학습시키기 위한 데이터셋을 구성하는데 사용되기 때문이다.
Fast R-CNN은 proposal layer에서 추출한 region proposal를 활용하여 detection을 수행한다. 이에 NMP을 적용하여 최적의 bounding box만을 결과로 출력한다.
