1. Introduction
VL-PTMs는 대규모 이미지-텍스트 말뭉치에서 사전 훈련함으로써 모든 방향에서 얻어진 표현을 학습할 수 있다.
이는 하위 V-L 테스트에서 강력한 성능을 달성하는 데 도움이 된다.
예를 들어
- LXMERT는 이중 스트림 퓨전 인코더를 사용하여 V-L 표현을 학습하며, 사전 훈련을 통해 VAQ, NLVR 작업에서 기존 모델을 크게 앞지르고 있습니다.
- 또한, visual commonsense reasoning 과 image captioning 같은 다양한 V-L작업에서 강력한 결과를 달성한다.
VL-PTMs는 서로 다른 단일 모달 인코더, 정교한 V-L 상호 작용 방식, 다양한 사전 훈련 작업을 활용한다.
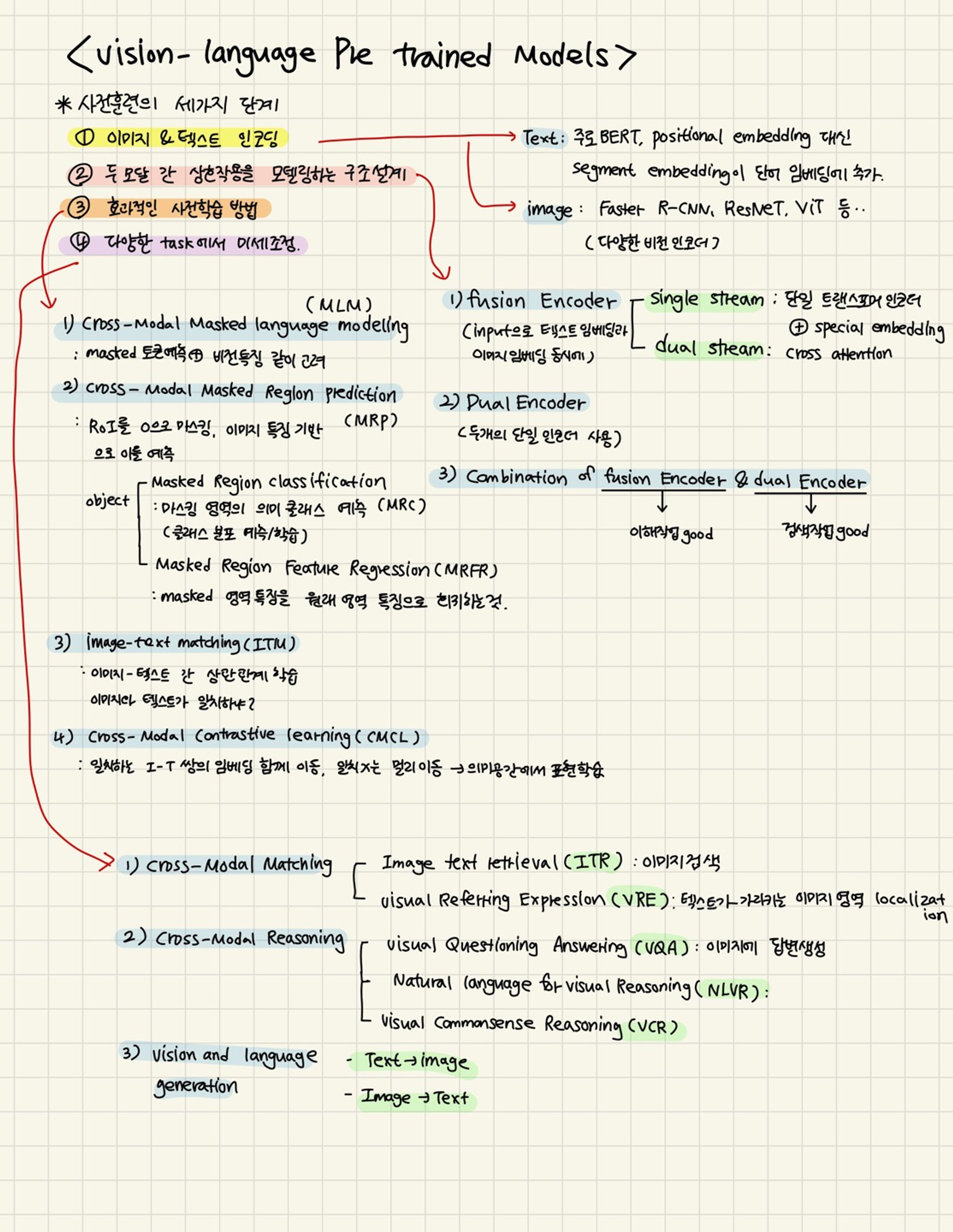
기본적으로 VL-PTM을 사전훈련하는 데에는 세가지 단계가 있다.
1) 이미지와 텍스트를 의미를 보존하며 잠재 표현으로 인코딩하는 것
2) 두 모달 간 상호작용을 모델링하는 효율적인 구조 설계
3) VL-PTM을 훈련시키기 위한 효과적인 사전 훈련 작업을 개발
4) 다양한 V-L 작업에서 미세조정 하기
이 각각의 방법에 대해서 이 논문은 장마다 다룰 예정이다.
너무 복잡해서 조금 정리해봤습니다.
2. Learning Vision-language Representation
위의 1번 과정을 이번 섹션에서 다룬다.
입력 의미를 보존하면서 이미지와 텍스트를 인코딩하는 것은 VL-PTM을 사전 훈련하는데 첫번째 단계이다.
이미지와 텍스트를 인코딩하는 방법은 두 가지 성질이 다르기 때문에 상당히 다른 양상으로 진행된다.
다음에서는 이미지와 텍스트를 단일 모달 임베딩으로 인코딩하는 여러 방법을 소개한다.
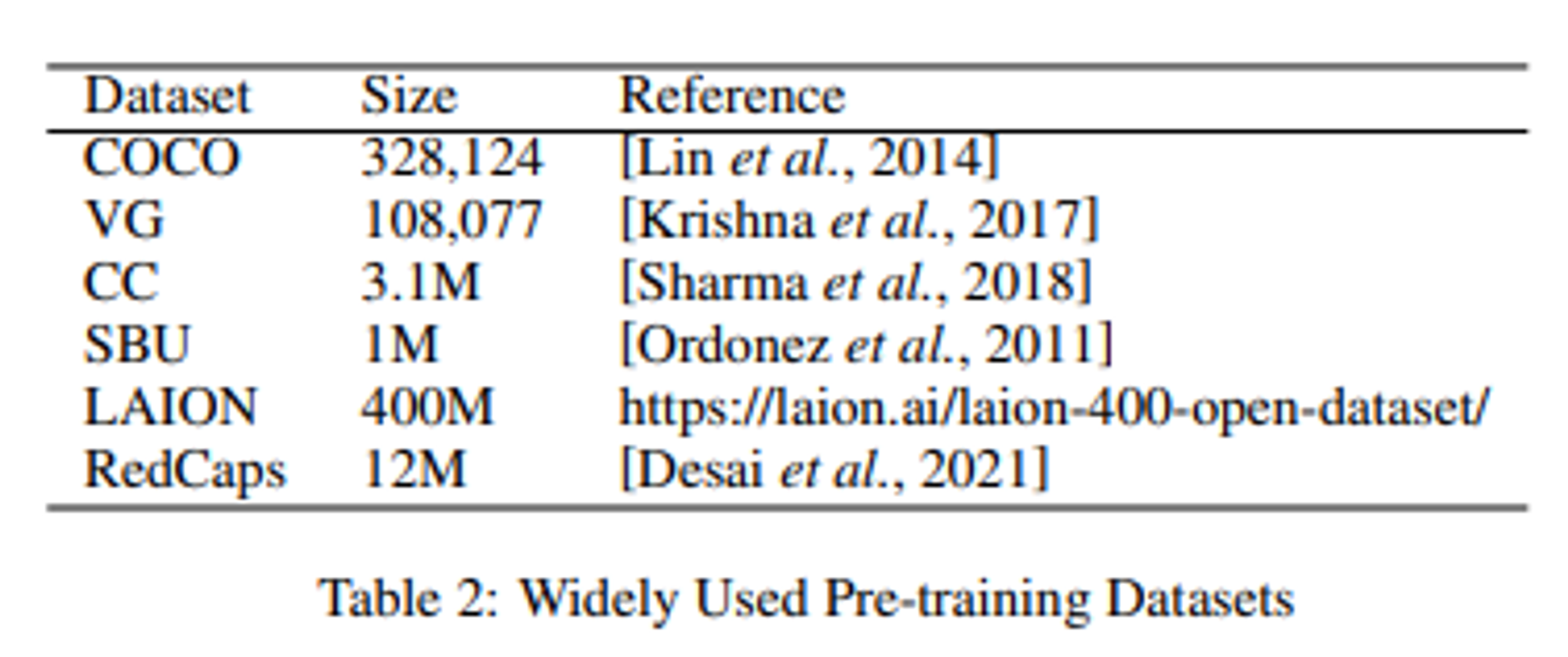
2.1 Pre-training Dataset
사전학습의 초기 단계는 당연히 대규모의 이미지-텍스트 쌍을 구성하는 것이다.
우리는 사전 훈련 데이터셋을
로 형식적으로 정의한다.
여기서 W는 텍스트, V는 이미지를 나타내며 N은 이미지-텍스트 쌍의 수이다.
구체적으로 각 텍스트는 토큰 시퀀스 로 토큰화된다. 각 이미지는 객체 특성(또는 그리드 특성, 패치 특성)의 시퀀스로 변환된다. 이를 으로 나타낸다.
아래는 최근 제안된 사전학습 훈련 데이터셋이다.
2.2 Text Representation
대부분의 기존 VL-PTM연구는 BERT를 따라 원시 텍스트를 전처리한다.
텍스트 시퀀스는 먼저 토큰으로 분할되고 [cls],[sep]토큰과 연결된다. [cls]는 문장 시작 전에,[sep]는 문장이 끝나고 추가되는 토큰이다.
각 토큰 는 단어 임베딩으로 매핑된다. 또한 위치를 나타내는 positional embedding과 달리 모달리티 유형을 나타내는 segment embedding이 단어 임베딩에 추가되어 의 최종 임베딩을 얻는다.
2.3 Image Representation
텍스트에서 단어 간의 관계와는 달리 이미지에서 시각적 개념 간의 관계는 V-L작업에서 중요하지만 포착하기 어렵다.
이미지에 대한 설명을 생성하려면 모델이 이미지 내 다양한 객체 간의 복잡한 관계를 추론해야한다.
따라서 많은 연구는 이러한 관계와 객체의 특성을 모델링하기 위해 다양한 비전 인코더를 상세하게 다룬다.
- ViLBERT 및 LXMERT와 같은 초기 작업은 먼저 Faster R-CNN을 사용하여 이미지에서 일련의 객체 영역을 감지한 다음 이를 Roi 피쳐로 인코딩한다.
- pixel-BERT와 SOHO는 Faster R-CNN대신 ResNet을 선호하여 시각 인더가 이미지를 전체로 볼 수 있도록 하고, 일부 중요한 영역을 무시하는 위험을 피한다.
- Vit 의 성공을 따라가기 위해 트랜스포머를 사용하여 비전 피처를 추출하는 경우도 있다. 이 경우 VL-PTM의 트랜스포머는 이미지 내의 객체 관계를 모델링하는 것이 목표이다. 이미지는 먼저 여러 평탄화된 2D 패치로 분할된다. 그런 다음 이미지 패치릐 임베딩은 시퀀스로 배열되어 원래 이미지를 나타낸다.
- ALBEF 및 SimVLM는 패치를 Vit 인코더에 공금하여 비전 기능을 추출하며, 이는 트랜스포머를 VL-PTM으로 이끄는 선구적인 역할을 한다.
3. Modeling Vision-Language Interaction
이미지와 텍스트를 단일 모달 임베딩으로 인코딩 한 후 다음은 양쪽 모달에서 정보를 통합하기 위한 인코더를 설계하는 것이다.
- 이미지에 대한 질문을 답하려면 모델은 질문과 답변의 양쪽에서 언어 정보를 결합한 다음 짝을 이룬 이미지에서 해당 영역을 찾아 마지막으로 언어 의미를 시각적 단서와 일치시켜야 함
다양한 modality에서 정보를 집계하는 방식에 따라 인코더를
- 퓨전 인코더
- 듀얼 인코더
- 이 두가지를 결합 한 것
으로 분류한다.
3.1 Fusion Encoder
퓨전 인코드는 텍스트 임베딩과 이미지 임베딩을 input으로 받고 V-L모델의 상호작용으로 접근하기 위한 여러가지의 fusion approach를 제공한다.
self-attention이나 cross-attention 이후에 마지막 층의 hidden state이 ㄷ양한 fused representation으로 사용될 것이다.
cross-model interaction을 모델링하기 위한 주 된 두가지 fusion방법은
1) single stream
2) dual stream
이 있다.
3.1.1 single stream architecture
싱글 스트림 아키텍처는 두 모달리티 간의 잠재적인 상관 관계와 정렬이 간단하다고 가정하며, 이는 단일 트랜스포머 인코더에 의해 학습될 수 있다고 가정한다.
따라서 텍스트 임베딩과 이미지 특징이 함께 연결되고 위치 및 모달리티를 나타내는 특별한 임베딩이 추가되어 트랜스포머 기반 인코더로 전달된다.
서로 다른 V-L 작업이 서로 다른 입력 형식을 필요로 할 수 있지만( 이미지 캡션 작업 , VAQ작업에 따라 요구되는 형식이 다른 것처럼) , 싱글 스트림 구조는 transformer attention의 정렬되지 않은 표현 특성으로 인해 이를 통합된 프레임워크에서 처리할 수 있다.
- VisualBERT 및 V-L BERT는 서로 다른 소스에서의 입력 요소를 나타내기 위해 세그먼트 임베딩을 활용한다.
- OSCAR은 이미지에서 감지한 객체 태그를 추가하고 이미지 텍스트 쌍을 h단어,태그, 이미지 i 트리플로 나타내어 퓨전 인코더가 다양한 모달리티를 더 잘 정렬할 수 있도록 지원한다.
싱글 스트링 아키텍처는 두 모달리티에 대해 직접적으로 self-attention을 수행하므로 모달리티 내 상호작용을 무시할 가능성도 있다. 이 이유로 dual stream을 사용해야한다는 주장이 나온다.
3.1.2 Dual-stream Architecture
싱글 스트림 아키텍처와 달리 자체 attention 연산 대신 V-L 상호 작용을 모델링하기 위해 교차 어텐션 메커니즘을 채택한다.
Q는 한 모달리티에서 가져오고, key와 value는 다른 모달리티에서 가져온다.
cross attention layer에는 일반적으로 two undirectional cross-attention sub layers를 포함한다. 한개는 텍스트에서 비전으로, 다른 하나는 비전에서 텍스트이다. 이들은 정보를 교환하고 두 모달리티 간의 의미를 정렬하는 역할을한다.
dual stream 구조는 모달리티 내의 상호작용과 모달리티 간의 상호작용을 분리하면 더 나은 다중 모달 표현을 얻을 수 있다고 가정한다.
- ViL-BERT는 교차 모달 모듈 이후에 모달리티 간 상호작용을 더 자세히 모델링하기 위해 두개의 트랜스포머를 사용한다.
- LXMERT는 추가 트랜스포머를 사용하지 않고 cross attention sub layer이후에 self-attention 서브 레이어를 추가하여 내부 연결을 더 강화한다. 교차 모달 서브 레이어에서 어텐션 모듈의 매개변수는 두 스트림 간에 공유된다. 이 경우, 모델 이미지 및 텍스트 임베딩을 맥락화하기 위한 단일 기능을 학습한다.
- ALBEF는 이미지와 텍스트에 대해 cross attention 이전에 두 개의 별도 트랜스 포머를 사용하여 모달리티 간 상호작용과 모달리티 간 상호작용과 모달리티 내 상호작용을 더 효과적으로 분리한다.
이러한 유형의 구조는 입력을 더 포괄적으로 인코딩하는데 도움이 된다.
하지만 추가적인 기능 인코더는 매개변수를 비효율적으로 만든다.
3.2 Dual Encoder
fusion encoder은 V-L 상호작용을 모델링하기 위해 무거운 트랜스포머 네트워크에 의존한다는 단점이 있다. 또한 image-text검색과 같은 교차 모달 매칭 작업을 수행할 때 퓨전 인코더는 모든 가능한 이미지 텍스트 쌍을 함께 인코딩해야 하므로 상당히 느린 추론 속도를 유발한다.
때문에, dual encoder은 두 모달리티를 별도로 인코딩하기 위해 두 개의 단일 모달 인코더를 활용한다.
그 다음 얕은 attention layer 또는 dot product와 같은 직관적인 방법을 채택하여 이미지 임베딩과 텍스트 임베딩을 동일한 의미 공간으로 투영하여 V-L 유사성 점수를 계산한다.
transformer의 복잡한 cross attention 없다는 장점.
이미지와 텍스트의 특정 벡터는 미리 계산되고 저장될 수 있으며, 이는 fusion encoder 보다 검색 작업에 효과적이다.
- CLIP와 같은 듀얼 인코더 모델은 image-text 검색 작업에 좋은 성능을 보이지만 NLVR같은 어려운 task에는 그다지 좋지 않다. → 두 모달리티 같의 얕은 상호작용 때문이다.
3.3 Combination of fusion Encoder and Dual Encoder
fusion encoder가 V-L의 이해 작업에서 더 좋은 성능을 발휘하는 반면, dual encoder는 검색 작업에서 더 나은 성능을 보이는 것을 보면 두 유형의 아키텍처의 이점을 결합하는 것이 보다 좋은 것이라고 가정 .
- FLAVA는 먼저 듀얼 인코더를 채택하여 단일 모달 표현을 얻는다. 그다음 이는 교차 모달 표현을 얻기 위해 fusion encoder로 보내진다. FLAVA는 단일 모달 표현의 품질을 향상시키기 위해 여러 사전훈련 작업도 소개한다.
- VLMo는 Mixture-of-Modality-Expert(MoME)를 소개하고, 듀얼 인코더와 퓨전 인코더를 단일 프레임 워크를 통합한다.
4. Cross-Modal Pre-training Tasks
입력 이미지와 텍스트가 벡터로 인코디되고 완전히 상호 작용 한 후, 다음 단계는 VL-PTM을 위한 사전 훈련 작업을 설계하는 것이다.
이 사전 훈련 작업은 VL-PTM이 데이터로부터 무엇을 학습할 수 있는지에 큰 영향을 미친다.
일부 사전학습 훈련 방법을 소개한다.
4.1. cross-modal Masked Language modeling(MLM)
cross -modal MLM은 BERT 모델의 MLM과 유사하다.
cross - modal MLM에서 VL-PTM은 가려진 토큰을 예측하는데 있어서 마스크가 된 토큰뿐만 아니라 비전 특징도 같이 고려한다.
이 작업은 비전과 텍스트 간의 관계를 고려하여 모델이 비전과 텍스트를 정렬하는데 도움이 되기 때문에 VL-PTM의 사전 훈련에 매우 효과적인 것으로 입증된다.
공식적으로는 다음과 같이 정의된다.
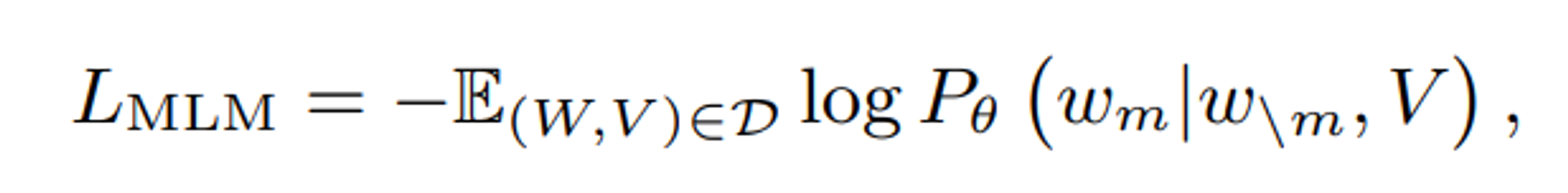
여기서 과 은 각각 가려진 토큰과 가려지지 않은 토큰을 나타내며, 와 는 데이터셋에서 샘플링된 텍스트 와 이미지 를 나타낸다.
cross-modal MLM에는 효과적인 마스킹 전략이 필요하다. 메서드가 너무 간단하면 모델이 주변 토큰을 기반으로 가려진 토큰을 순수하게 예측할 수 있다.
이미지에 너무 의존하는 일부 토큰을 마스킹하면 VL-PTM은 이미지 특징을 고려하여 토큰을 그에 해당하는 이미지 객체와 정렬한다.
- ViLT는 whole word Masking 전략을 사용하며, 모델이 단어 공존성만을 기반으로 토큰을 예측하는 것을 방지한다.
- interBERT는 텍스트의 여러 연속 세그먼트를 마스킹하여 이 사전 훈련 작업을 더 어렵게 만들고 하위 작업에서의 성능을 더 향상시킨다.
4.2 cross-Modal Masked Region prediction(MRP)
cross modal MRP는 cross modal MLM과 유사하게 일부 ROI(features)를 0으로 마스킹하고, 다른 이미지 특징을 기반으로 이를 예측한다.
모델은 다른 가져지지 않은 영역에서의 추론을 통해 객체 간의 관계를 학습하고, 텍스트에서의 추론을 토해 V-L정렬을 학습한다.
학습 목표로는
- Masked Region Classification(MRC)
- Masked Region Feature Regression(MRFR)
이 있다.
4.2.1 Masked Region Classification(MRC)
MRC는 각 마스킹된 영역의 의미 클래스를 예측하는 방식으로, 이 작업은 VL-PTM이 언어 측면에서 이미지의 낮은 수준의 픽셀이 아닌 고수준의 의미를 학습한다는 관찰에 기반한다.
region class를 예측하기 위해 VL-PTM의 마스킹된 지역 의 hidden state인 가 FC layer에 주입되며, softmax함수를 통해서 K개의 클래스의 예측된 분포를 형성한다.
예측된 분포와 감지된 객체 범주 간의 교차 엔트로피(CE) 손실을 최소화하는 것이 최종 목표로 정의될 수 있다.
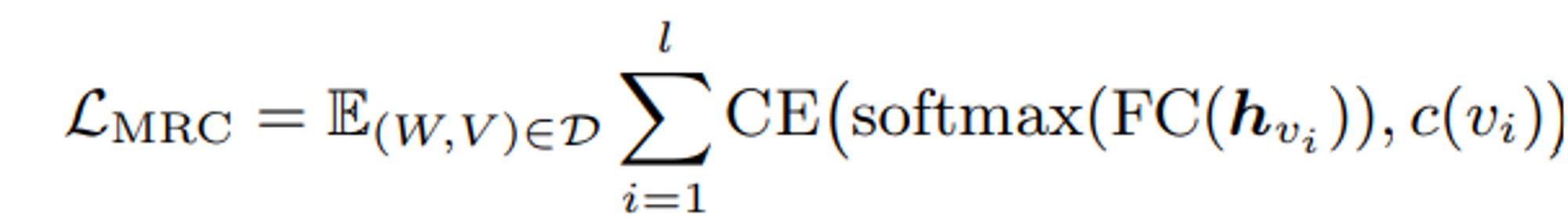
l은 마스킹된 지역의 수, 는 마스킹된 지역의 실제 레이블을 나타낸다. 이는 객체 감지 출력이나, 미리 정의된 시각적 토큰과 같은 것이다.
h_{vi}는 비전과 언어 모달리티 두개에서의 정보를 둘다 포함하고 있기 때문에, 텍스트로부터 visual semantic class를 예측할 수 있도록 한다.
ground truth c(v_i) 에 대한 직관적인 방법은 객체 탐지기에서 검출된 객체 태그(가장 높은 confidence score) 를 실제 레이블로 간주하는 것
- ViLBERT와 UNITER는 detector의 객체 클래스의 분포를 (raw output)을 soft label로 고려. 이 경우에는 objective가 두 분포간의 KL-divergence가 된다.
- SOHO는 먼저 CNN기반 그리드 feature를 시각적 토큰으로 매핑한 다음, 주변 토큰을 기반으로 마스킹된 토큰을 예측한다.
4.2.2 Masked Region Feature Regression(MRFR)
MRFR은 가려진 영역 특징 h{vi}를 해당하는 원래 영역 특징 $\hat{E}{V(vi)}$
으로 회귀하는 것을 학습한다.
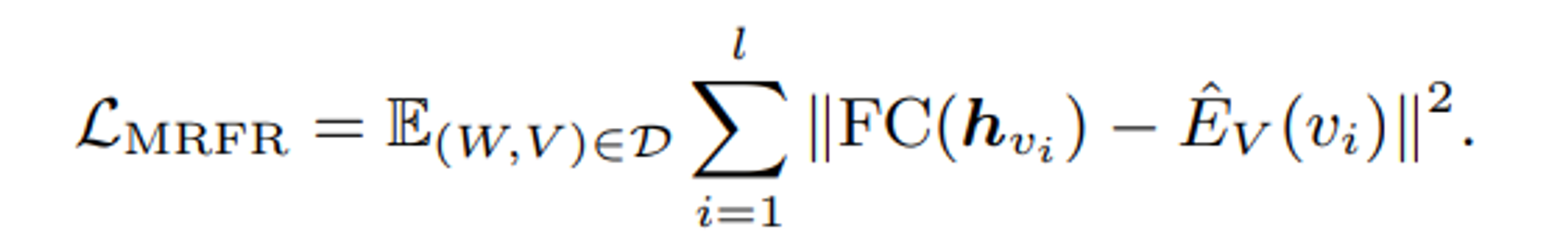
이 공식에서는 영역특징 이 v_i의 언마스크된 이미지를 기반으로 계산되며, 여기서 l은 masked 된 지역의 양을 표현한다.
MRFR은 모델이 의미적인 클래스가 아닌 고차원 벡터를 재구성하도록 요구한다.
Faster R-CNN에 의해 이미지가 영역 특징의 시퀀스로 표현될 때 random masking같은 간단한 마스킹 전략은 만족스러운 성과를 준다.
하지만 random masking은 이미지가 그리드 특징이나 패치 특징으로 변환될 때 효과적이지 않을 수 있다. 모델은 예측된 특징으로 이웃 특징을 직접 복제할 것이기 때문이다.
visual parsing은 이미지를 나타내기 위해 패치 특징을 사용하고 시각적 토큰(영역 특징)이 높은 attention weight을 가질때 유사한 의미를 가진다고 가정한다.
먼저 시각적 토큰을 피벗 토큰으로 무작위로 가리고, 상위 k의 attention weight을 가진 k개의 토큰을 계속 가린다.
SOHO는 vision dictionary를 미리 훈련시키고 동일한 시각적 색인을 공유하는 모든 기능을 가린다. 정보 누출을 가리기 위한 것이다.
4.3 Imag-Text Matching(ITM)
cross-modal MLM 및 MRP는 VL-PTM이 이미지와 텍스트 간의 세밀한 상관관계를 학습하도록 돕고, ITM은 VL-PTM에게 이를 고도로 일치시키는 능력으르 부여한다.
ITM은 NLP의 다음 문장 예측(NSP) 작업과 유사하하며, 모델이 이미지와 텍스트가 일치하는지 여부를 판단하도록 요구한다.
이미지-텍스트 쌍이 주어지면 score function 는 이미지와 텍스트 간의 일치 확률을 측정한다. object function은 다음과 같다.
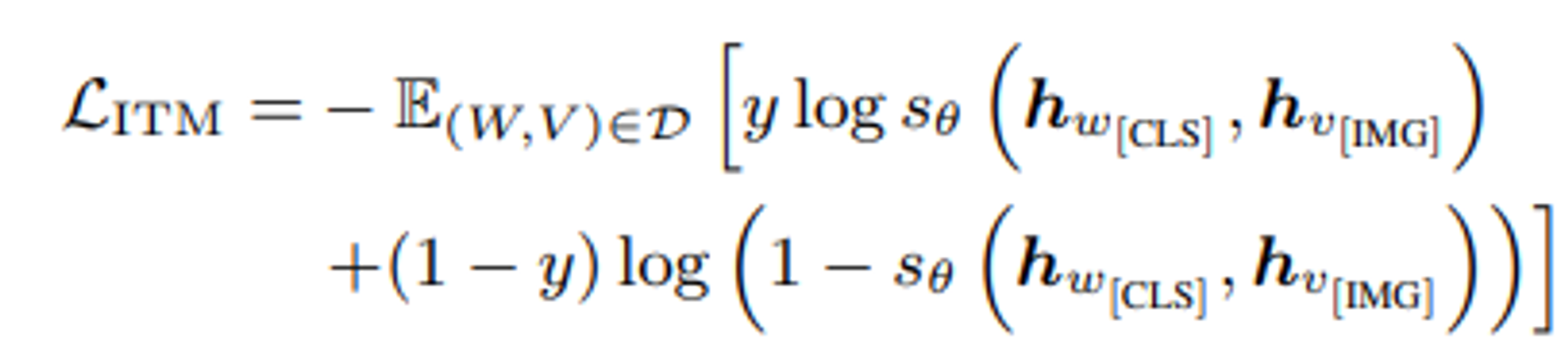
여기서 y는 0,1중에 하나로 W와 V가 일치하는지 여부를 나타내며, 와 은 각각 와 의 표현이다.
이 작업의 핵심은 이미지-텍스트 쌍을 단일 벡터로 어떻게 표현할지이며, 이를 통해 score function 가 확률을 출력할 수 있다.
- UNITER,Unicoder,SOHO는 단어 시퀀스 W와 객체 시퀀스 V를 연결하고 ‘[cls]’토큰의 최종 은닉상태를 fused representation으로 취한다. 이를 FC layer에 주입하여 차원을 축소하여 일치 확률을 예측할 수 있다.
- 반면에 ViLBERT는 [IMG]및 [CLS] 토큰의 표현을 각각 이미지와 텍스트를 나타내는 데 사용하며, fused representation은 이들간의 요소별 곱셈으로 계산된다.
4.4 Cross-Modal Contrastice Learning(CMCL)
CMCL은 일치하는 이미지 - 텍스트 쌍의 임베딩을 함께 이동시키고, 일치하지 않는 것들은 멀리 이동시킴으로써 동일한 의미 공간에서의 범용적인 시각 및 언어 표현을 학습하고자 한다.
이미지에서 텍스트로의 contrastive loss는 다음과 같다.
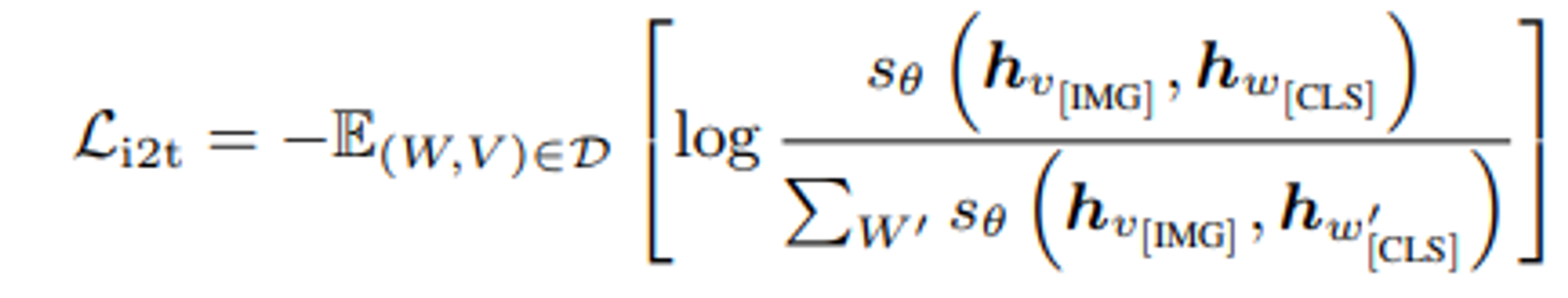
여기서 W^’는 V의 negative samples에 속한다.
는 주어진 이미지-텍스트 쌍이 얼마나 유사한지를 정당화하기 위한 점수 score function이다.
CMCL의 constractive loss는 대칭적이며, 텍스트에서 이미지로의 constractive loss도 유사하게 정의된다.
- CLIP는 대규모 이미지-텍스트 쌍을 활용하여 전이 가능한 시각적 표현을 학습하고, 이미지 분류 작업에 좋은 제로샷 전이를 보여준다.
- ALBEF는 거대한 노이지 이미지-텍스트 쌍에서 대조적 학습을 촉짆기 위해 모멘텀 디스틸레이션을 채택한다.
- WenLan은 MoCo를 사용하고 부정적인 샘플을 저장하는 que를 유지하여 대조적 학습에 효과적임이 입증되었다.
- UNIMO는 대조적 학습 중에 다양한 유니모달 데이터를 통합하여 시각과 언어가 서로 강화되도록 허용한다.
5. Adapting VL-PTMs to Vision-Lan Downstream Tasks
이 섹션에서는 여러 공통 vision-lan 통합 테스크와 VL-PTM이 이에 적응되는 방법을 소개한다.
기본적으로
- cross-modal matching
- cross-modal reasoning
- vision and language generation
으로 분류
5.1 Cross-Modal Matching
cross-Modal Matching은 VL-PTM에게 다른 모달리티 사이의 correspondences(대응?)를 학습하도록 요구한다.
두 가지 일반적으로 사용되는 매칭작업을 소개한다.
5.1.1 image text retrieval(ITR)
ITR(이미지 검색)
주어진 문장과 가장 일치하는 이미지를 검색하고 그 반대로 수행해야한다.
- 초기의 VL-PTM은 fusion encoder 구조를 활용하여 나중에 유사도 점수로 투영되는 융합된 벡터 표현을 얻었다.
- ALBEF나 CLIP와 같은 듀얼 인코더 구조는 이미지와 텍스트의 임베딩을 미리 계산하고 검색 전에 저장할 수 있기 때문에 ITR에 더 효율적이다.
5.1.2 Visual Referring Expression(VRE)
VRE(시각적 지시 표현)
NLP의 지시 표현 작업의 확장이다.
이 작업의 목표는 특정 텍스트 설명에 해당하는 이미지의 영역을 지역화하는 것이다.
대부분의 VL-PTM은 final representation of extracted resion proposals를 입력으로 사용하고 일치 점수를 예측하기 위해 linear projection을 학습하는 방식으로 작동한다.
5.2 Cross-Modal Reasoning
Cross-Modal reasoning은 VL-PTM이 시각적인 정보에 기반하여 언어 추론을 하는 것을 요구한다.
어느 한개의 모달리티라도 무시하면 성능이 안좋아진다.
5.2.1 Visual Question Answering(VQA)
텍스트 베이스의 QA와 다르게 VQA는 이미지에 대한 답변을 요구한다.
대부분 VQA를 분류작업으로 간주하고 모델에게 올바른 답을 선택하도록 요구한다.
- fusion encoder 구조를 사용하는 VL-PTM은 일반적으로 최종 교차 모달 표현(일반적으로 입력 [cls]토큰에 해당) 을 답 레이블 분포로 매핑한다.
- dual encoer을 사용하는 경우, VL-PTM은 상호작용이 너무 얕아 VQA 작업에 별로 효과적이지 않다.
5.2.2 Natural Lanunage for visual Reasoning(NLVR)
NLVR은 이미지 쌍과 텍스트 명제를 입력으로 제공하며 모델에게 명제가 이미지 쌍에 대해 참인지 여부를 결정하도록 요구한다.
따라서 이는 이진분류 작업으로 간주 될 수 있다.
대부분 VL-PTM은 먼저 주어진 두 이미지- 텍스트 쌍을 각각 인코딩하고 그런 다음 두 임베딩의 연결에 대한 분류기를 훈련하여 예측을 수행한다.
5.2.3 Visual Comonsense Reasoning(VCR)
VCR은 다른 종류의 VQA 작업으로 간주된다.
VCR과 VQA의 주된 차이점은 VCR의 질문이 시각적 상식에 더 주의를 기울인다는 것이다.
VQA와 달리 VCR은 두개의 다중 선택 하위 작업으로 분해될 수 있다.
1) 질의응답(Q→A) 및 2) 답변 정당화(Q+A→R)이 이것이다.
대부분의 VL-PTM은 이 두 하위 작업을 해결하기 위해 VQA에서 사용하는 것과 동일한 방법을 활용한다.
1)은 VQA와 절차가 동일하다.
2)의 경우는 질문과 답변의 연결이 새로운 질문으로 처리되고, 이에 대한 근거가 옵션으로 취급된다. 각 가능한 옵션에 대한 점수를 예측하기 위해 선형 레이어가 훈련된다.
5.3 Vision and Language Generation
text-to-image generation과 image-text generation으로 나눌 수 있다.
5.3.1 Text - to -Image Generation
설명적인 텍스트로부터 해당하는 이미지를 생성하는 작업이다.
- X-LXMERT는 먼저 연속적인 시각적 표현을 이산 클러스터 중심으로 변환하고, 그런 다음 모델에게 가려진 영역의 클러스터 ID를 예측하도록 한다.
- DALL-E는 이미지를 토큰화하기 위해 codebook을 훈련시키고, 텍스트에서 이미지 생성 작업을 autoregressive generative task으로 제안한다.
5.3.2 MultiModal Text generation
일반적으로 생성 프로세스에는 디코더가 필요하다.
이미지 캡션 생성은 이미지에서 텍스트로의 전환작업으로, 모델이 이미지에 대한 설명을 생성하도록 요구된다.
XGPT, VL-T5는 먼저 이미지를 인코딩하고, 디코더를 사용하여 autoregressive 하게 캡션을 생성한다.
멀티모달 기계 번역은 이미지를 도입하여 번역 품질을 향상시키기 위한 작업으로, VL-T5는 이미지 캡션 생성과 동일한 전략을 사용하여 이작업에 접근한다.
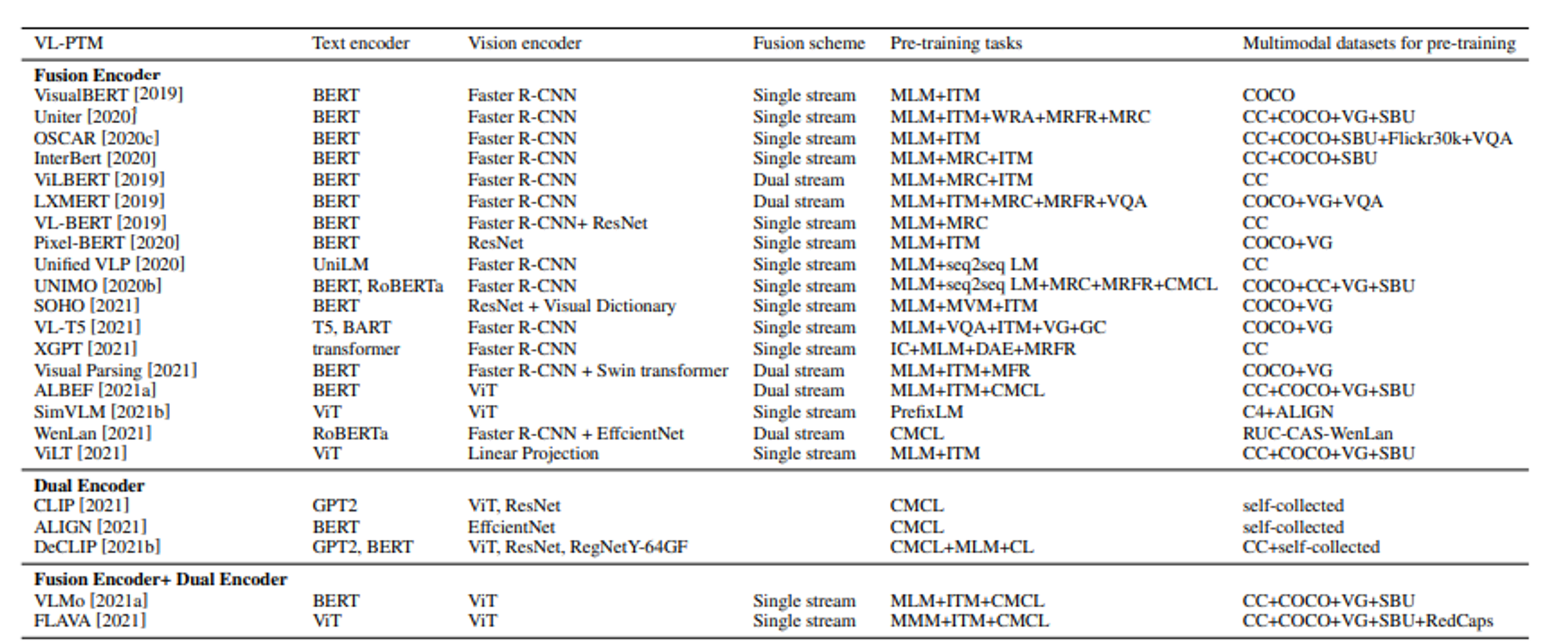
논문에 있던 테이블이다.
요번 심화세션에서는 이 여러 모델 중 OSCAR 에 대한 논문을 리뷰 할 예정이다.
