접근방식과 훈련 방식부분만 정리해보겠다.
간단하게 replug모델은 retrieval을 강황한 언어 모델 패러다임으로 , 언어 모델을 블랙 박스로 취급하고 검색 구성 요소를 조정 가능한 모듈로 추가하는 방식이다.
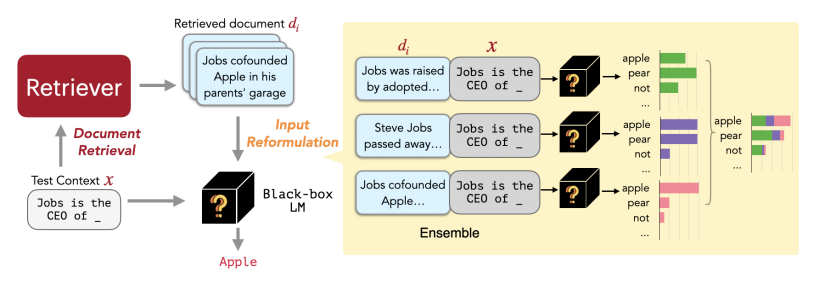
위 사진이 이 논문 모델 구조의 전체적인 패러다임이다.
Replug
1. document retrieval
먼저 문서 검색 파트이다.
입력 문맥 X가 주어지면 기존의 retrieval모델과 동일하게 외부 말뭉치에서 관련 있는 문서의 집합을 검색하여 반환하여 준다. dual encoder 아키텍처를 기반으로 하여 입력 문맥 x와 외부 문서 d를 인코딩한다.
1. 각 문서 를 토큰의 마지막 hidden state의 mean pooling을 통해 임베딩 E(d)로 매핑
2. 동일한 인코더가 입력 문맥 x에 적용되어 임베딩 E(X) 를 얻음
3. E(d)와 E(x)의 코사인 유사도에 따라 쿼리와 가장 유사한 상위 k개의 문서가 검색
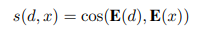
이 논문에서는 입력x와 검색된 문서를 연결하여 얻은 결과를 언어 모델(LM)을 병렬로 통과시킨 후에 예측된 확률을 앙상블하는 형식으로 사용된다. (2번에서 자세히 설명)
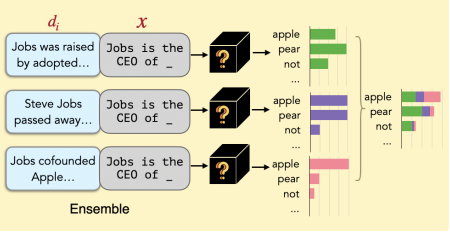
(이것 처럼. 위의 그림 확대)
2. Input Reformulation
상위 k개의 검색된 원래의 입력 문맥 x에 대한 풍부한 정보를 제공하고, 이 정보는 언어 모델이 더 나은 예측을 수행하는데 도움이 된다.
검색된 문서를 LM의 입력의 일부로 통합하는 간단한 방법은 x앞에 모든 k개의 문서를 추가하는 것이다. 그니까 같은 x에 후보 k개 다 각각 concat.
하지만 이 방법은 사용하고자 하는 언어 모델의 수용에 따라 제한을 받는다.
따라서 이를 해결하기 위해 앙상블 전략을 채택한다.
x에 대한 k개의 관련성이 높은 문서의 집합을 라고 가정.
각각 문서 $ d\in D'$을 x에 앞에서 부터 추가한 다음, 이 결합을 LM에 전달하고 모든 k 번 째의 통과의 출력확률을 앙상블한다.
입력 문맥 x와 해당 상위 k개의 관련 문서 D'에 대해 다음 토큰 y의 출력확률은 가중 평균 앙상블로 계산이 된다.
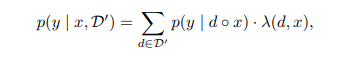
- 여기거 가중치 는 문서 d와 입력 문맥 x간의 유사도 점수에 기반함*
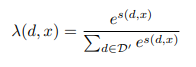
앙상블 방법은 k번 수행해야한다는 번거로움이 있지만, 각 검색된 문서와 입력 문맥간의 cross attention을 수행하기 때문에 추가 계산 비용부담이 발생하지 않는다.
Replug LSR : Training the Dense Retriever
사실 젤 중요한 부분이 훈련 부분이기 한데 이 논문에 깃헙이 제공되지 않아 이 쪽 부분까지 구현 할 수 있을지는 의문입니다. 따흐흑
Replug LSR이란 LM-supervised Retrieval을 사용한 REPLUG의 약자라고 하네용
나이브하게 정리하면, 훈련의 접근 방식은 검색된 문서의 확률을 조정하여 언어 모델의 출력 순열 복잡성의 확률과 일치시키는 것으로 볼 수 있다. 즉 ! 검색된 문서가 낮은 perplexity 점수를 초래하는 문서를 찾기를 원한다.
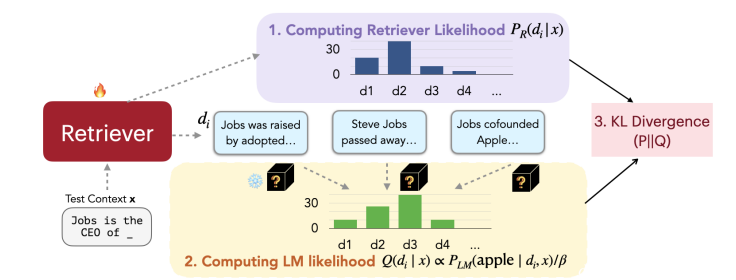
위의 그림이 훈련 과정의 네 단계 알고리즘이다.
1. 문서를 검색하여 Retrieval Likelihood를 계산한다. (-1)
2. 검색된 문서를 언어 모델에 의해 점수를 매긴다. (-2)
3. retrieval likelihood와 LM의 점수 분포간의 KL divergence를 최소화하는 방향으로 검색 모델 매개변수를 업데이트한다.
4. asynchronous update of the datastore index ( 그니까 원래 retrieval모델 사용할때 시간 단축을 위해 후보 문서를 미리 다 임베딩 해놓아서 인덱싱을 미리 해놓은 것을 업데이트 시킨다)
4.1 Computing Retrieval Likelihood
우리는 입력 문맥 x가 주어졌을 때 말뭉치 D에서 가장 높은 유사도 점수를 가진 k개의 문서
$D' \in D $ 를 검색한다.
그리고 각 검색된 문서 d에 대한 retreival likelihood를 다음과 같이 계산한다.
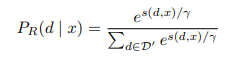
여기서 y는 소프트맥스의 정도를 조절하기 위한 하이퍼파라미터이다.
이상적으론 retreival likelihood 는 말뭉치 D의 모든 문서에 대한 주변화로 계산된다. 그러나 실제로는 이것은 실용적으로 계산하기 어려운 작업니다.
따라서 우리는 검색된 문서 D'에 대해서만 주변화하여 retreival likelihood를 근사화한다.
4.2 Computing LM likelihood
