1. 앙상블
: 여러 개의 모델을 결합해 단일 모델보다 더 안정적이고 성능 좋은 예측을 만드는 방법
- 기존 단일 모델들의 문제점
- Bias가 큼 (너무 단순 -> 못 맞춤)
- Variance가 큼 (너무 복잡 -> 과적합)
- 앙상블의 핵심 목적
- 여러 모델의 약점을 평균/보완해서 일반화 성능 높이기
앙상블
├─ Bagging → 분산 감소
├─ Boosting → 편향 감소
└─ Stacking/Blending → 모델 조합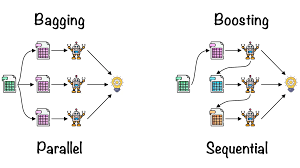
2. Bagging(Bootstrap Aggregating)
: 같은 종류의 모델을 서로 다른 데이터 샘플로 여러 개 학습시키고, 그 예측을 평균/다수결로 결합하는 방식
부트스트랩(Bootstrap)?
지금 가진 표본 데이터만 가지고, 그 안에서 복원추출을 반복해서 '가짜 모집단'을 흉내 내는 방식
- 단계
- 원본 데이터에서 복원 추출로 여러 데이터셋 생성 -> 데이터 다양성 확보
- 각 데이터셋으로 같은 모델을 학습
- 결과를 평균/다수결로 결합 <- 분류: 다수결, 회귀: 평균
-> 한 모델의 실수를 다른 모델이 상쇄
1) BaggingClassifier/Regressor
: 특정 모델을 base estimator로 지정해 그대로 Bagging을 적용하는 일반적인 방식
- 구조
- base model: 아무거나 가능
(Decision Tree, KNN, Logistic Regression 등)
BaggingClassifier( base_estimator = DecisionTree, n_estimators = 100 ) - base model: 아무거나 가능
- 장점
- 단일 모델 대비 안정적
- 병렬 학습 가능
- 구현 단순
- 단점
- Bias 개선 거의 없음
- 모델 수 증가 -> 해석 어려움
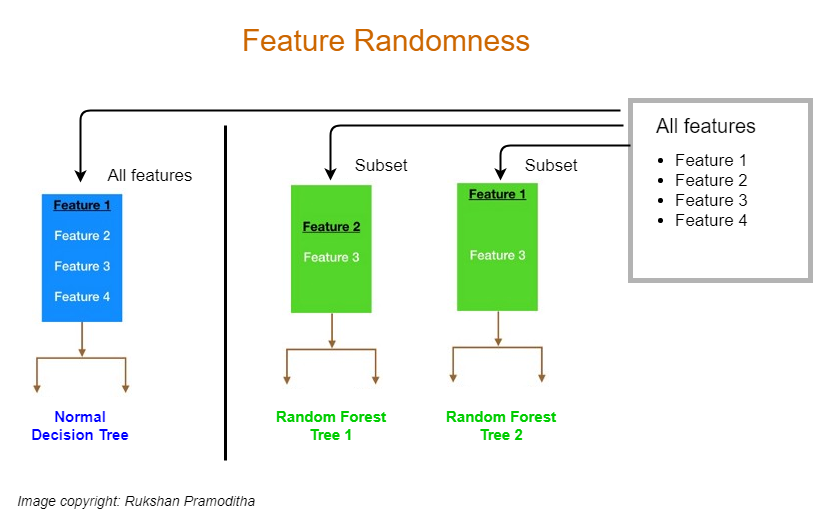
2) Random Forest(Bagging + feature radomness)
: Bagging에 "피처 랜덤성"을 추가한 트리 앙상블
- 기존의 문제: 부트스트랩만으로는 다양성 부족
- Bagging만 쓰면 모든 피처가 항상 중요한 피처를 먼저 씀으로써 트리들이 서로 비슷해짐(<- 복원 추출을 해도 강력 피처는 항상 비슷함)
- Decision Tree 10개를 배깅한다고 할 때, 10개의 Decision Tree는 각각 서로 다른 데이터 샘플로 학습되고, 각 트리는 노드마다 랜덤으로 선택된 일부 피처 중에서 최적의 분기를 반복하며 만들어짐.
3) Extra Trees
- Random Forest는 분기 기준은 최적값 찾았지만 Extra Trees는 분기 기준값도 랜덤으로 설정
- 데이터가 많고 노이즈가 많을 때 사용하기 좋음.
- RF보다 빠름.
# Random Forest
나이 기준값 후보 전부 계산
→ 29.5, 31.0, 36.7, 42.1
→ 지니 제일 좋은 31.0 선택
# Extra Trees
나이 최소=23, 최대=45
→ 그 사이에서 랜덤으로 38.4 뽑음
→ 그냥 나이 < 38.4로 분기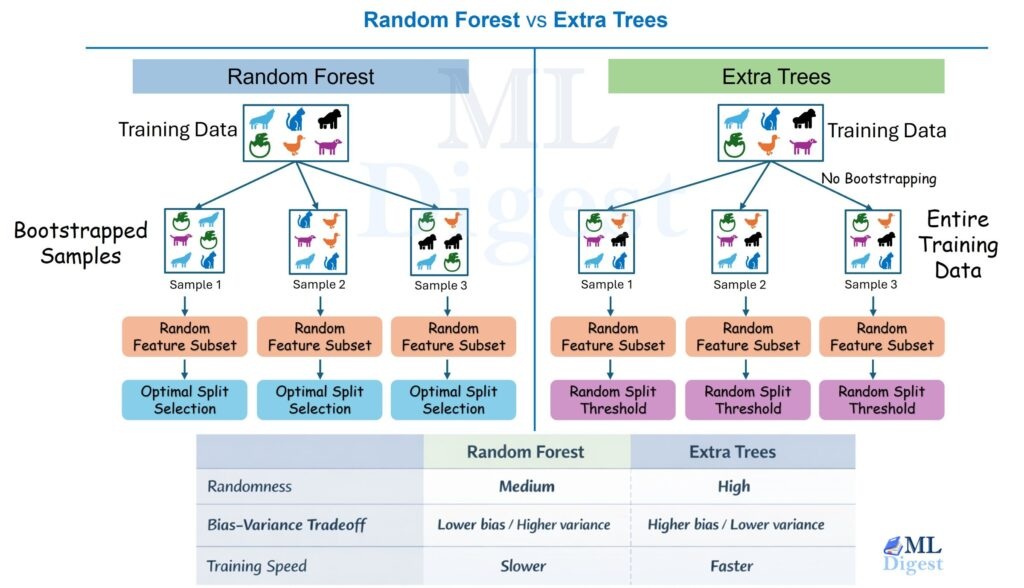
정리
| 구분 | Decision Tree | Bagging | Random Forest | Extra Trees |
|---|---|---|---|---|
| 나무 개수 | 1 | 여러 개 | 여러 개 | 여러 개 |
| 데이터 샘플링 | ❌ | O | O | O |
| 피처 랜덤 | ❌ | ❌ | O | O |
| 분기값 랜덤 | ❌ | ❌ | ❌ | O |
| 오버피팅 | 매우 높음 | 감소 | 더 감소 | 가장 안정 |
| 실무 사용 | 거의 안 씀 | 가끔 | 매우 많음 | 상황 따라 |
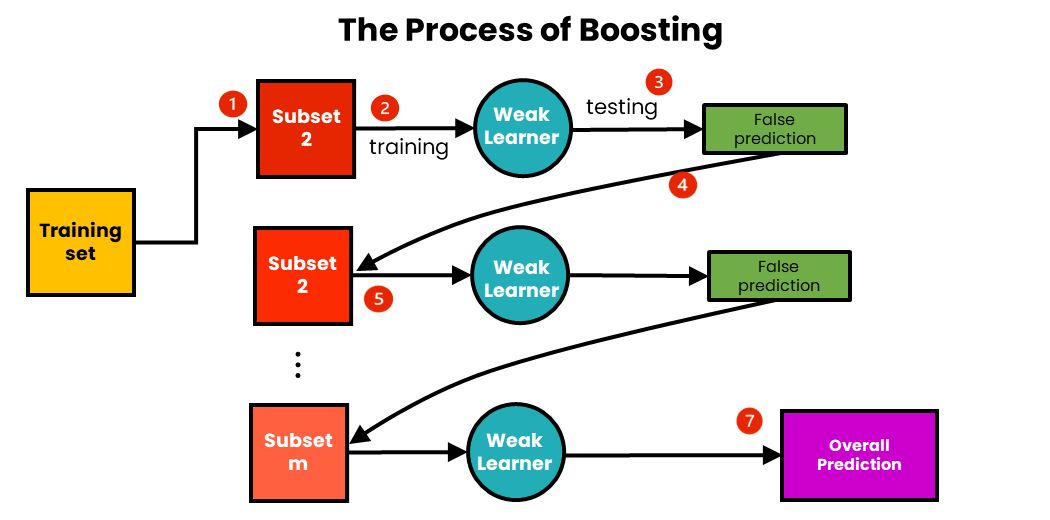
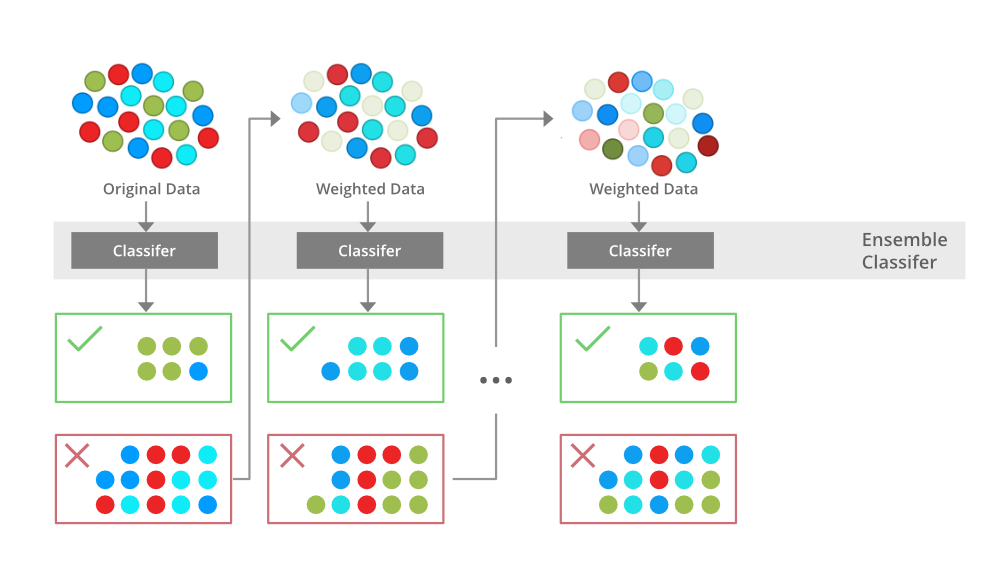
3. Boosting
: 이전 모델이 틀린 데이터를 다음 모델이 더 집중해서 학습하도록 모델을 순차적으로 쌓는 방법
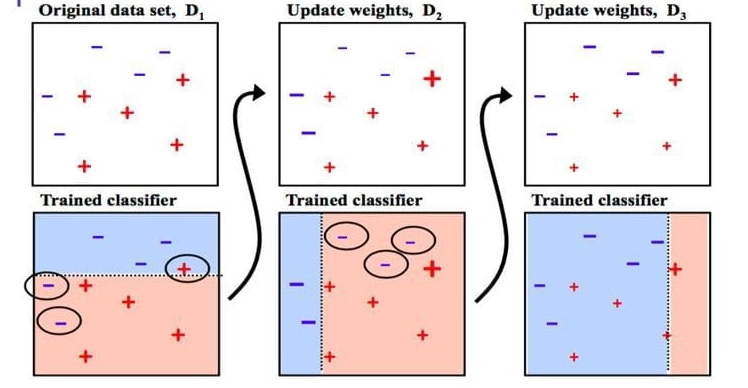
1) AdaBoost(Adaptive Boosting)
: 이전 모델이 오분류한 샘플의 가중치를 증가시켜 다음 모델이 그 샘플들에게 더 큰 비중을 두고 학습하도록 유도하는 부스팅 알고리즘
- 핵심 아이디어: 샘플 가중치 업데이트로 "어려운 샘플"에 집중
- 결합 방식: 학습기별 성능에 비례한 가중 투표/가중 합
- 특징: 데이터 노이즈(라벨 오류)에 민감할 수 있음
약한 학습기 (Weak Learner)
단독으로는 높은 성능을 내지 못하지만 무작위 추정보다 약간 더 나은 성능을 보이는 모델을 의미함.
부스팅에서는 이러한 약한 학습기를 순차적으로 결합하여 강한 학습기(strong learner)를 구성함.
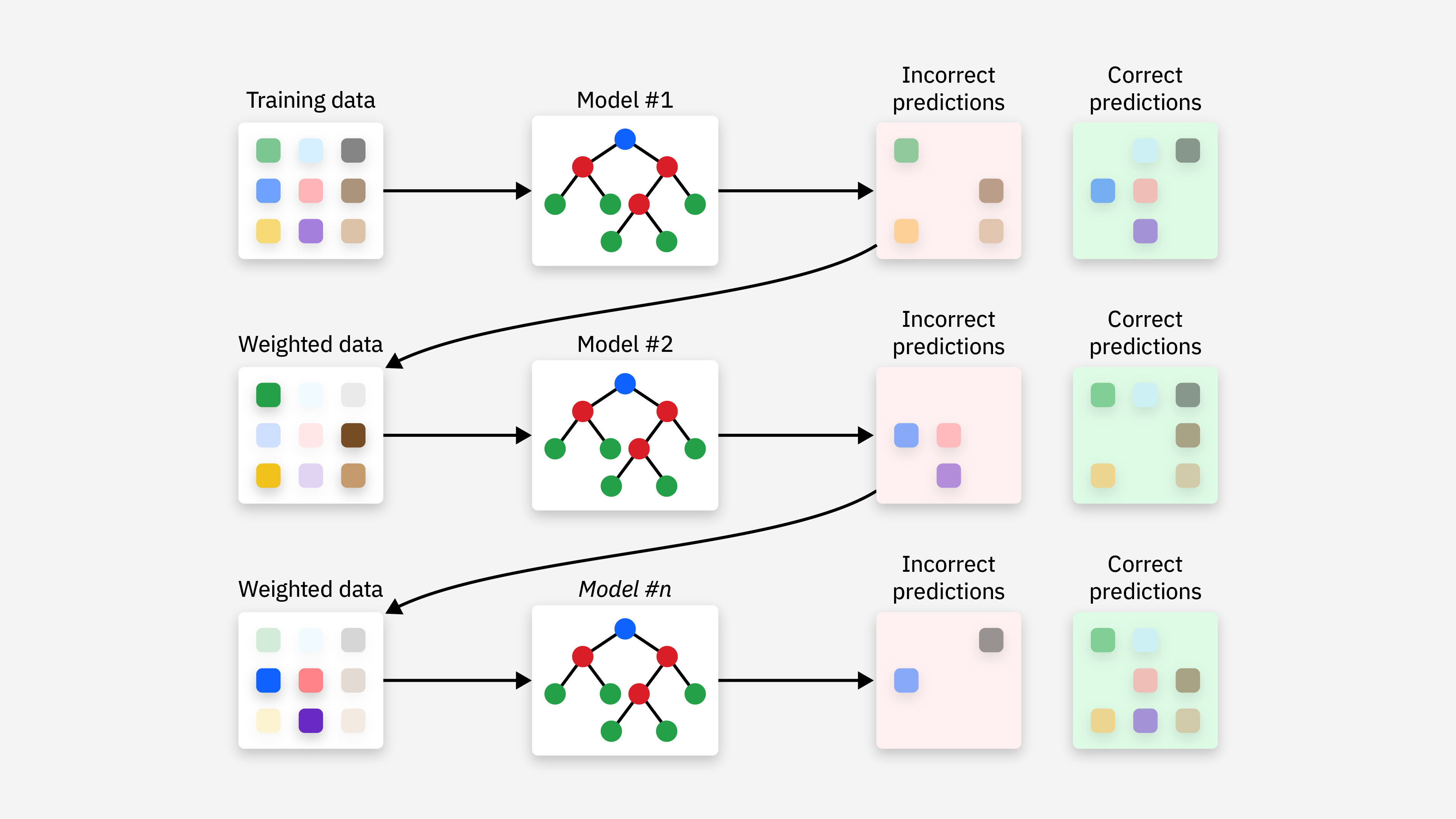
2) Gradient Boosting(GBDT)
: 이전 모델의 오차를 다음 모델이 예측하도록 순차적으로 학습시키는 방법
-> 이전 단계 모델의 예측이 정답에 못 미친 만큼(손실을 줄이는 방향)을 다음 트리가 보정하면서 전체 모델을 점진적으로 개선
- 핵심 아이디어: 잔차/손실 감소 방향을 다음 모델이 학습
- 손실함수 기반: 다양한 손실함수(회귀/분류 등)에 적용 가능
- 장단점
- 장점: 표현력 강함, tabular 데이터에서 강력한 베이스라인
- 단점: 모델이 순차적으로 쌓이므로 학습이 느릴 수 있고, 파라미터 설정에 따라 과적합 위험 존재
AdaBoost가 "가중치로 샘플 중요도를 조절"한다면, GBDT는 "오차를 함수적으로 보정"함.
3) XGBoost(Extreme Gradient Boosting)
: GBDT를 실무/대규모 환경에서 더 안정적이고 강력하게 쓰기위해 다양한 개선을 넣은 대표적인 구현체
- 기존 GBDT의 문제
- 트리 만들 때 계산이 많아 느리고
- 트리가 깊어지면 과적합하기 쉽고
- 큰 데이터에서 효율/안정성이 아쉬움.
- 정규화로 트리 복잡도 문제 해결
- 리프 개수 벌점
- 리프 하나 추가할 때마다 비용 추가
- 어떤 분기를 만들었을 때 손실 감소량이 γ(비용)보다 적으면 분기 안 함 -> 의미 없는 미세 분기 자동 차단(pruning) (<- 만들고 나서 손해면 잘라내는 방식!)
- 리프 값 크기 벌점
- 잔차가 큰 샘플 몇 개가 리프 예측값을 과하기 키우는 방식을 해결
- 리프 예측값 자체에 L2/L1 정규화를 걸음.
- 리프 값이 커질수록 손실 함수에서 벌점 증가
- 리프 예측값이 자연스럽게 완만
XGBoost는 트리의 복잡도를 제어하기 위해 목적 함수에 정규화 항을 추가함. 리프 노드의 개수에 대한 벌점을 통해 불필요한 분기를 억제하고, 리프 예측값의 크기에 대한 정규화를 통해 특정 샘플에 과도하게 맞춰지는 현상을 방지. 이를 통해 손실 감소와 모델 단순성 사이의 균형을 유지하며 과적합을 완화.
- 리프 개수 벌점
4) LightGBM
: 대용량 데이터에서의 학습 속도/메모리 효율을 극대화한 GBDT 계열 모델
-
기존 모델의 문제
- split 후보 탐색 비용이 큼
- 메모리 사용량 증가
- 학습 시간이 길어져 실험 반복 어려움
-
해결방안
- Histogram 기반 split
- 연속형 값을 몇 개 구간(bin)으로 압축
- Leaf-wise 트리 성장
- 트리를 깊이 기준으로 균형 있게 키우는 level-wise가 아닌 현재 존재하는 leaf 중에서 "손실을 가장 많이 줄일 수 있는 leaf 하나"를 골라 그 leaf만 확장
XGBoost: level-wise (균형) LightGBM: leaf-wise (가장 손해 큰 곳부터)
- Histogram 기반 split
-
장점: 빠른 학습, 메모리 효율, 대규모 데이터에 강함
-
주의점: 작은 데이터나 노이즈가 많을 때는 leaf-wise 특성상 과적합이 더 쉽게 발생할 수 있어 depth/leaf 관련 파라미터 관리가 중요
파라미터 역할 커지면 줄이면 num_leaves 최대 리프 수 표현력↑, 과적합↑ 단순화, 성능↓ max_depth 트리 최대 깊이 복잡도↑ 과적합↓ min_data_in_leaf 리프 최소 샘플 수 안정성↑ 세밀한 패턴↑ learning_rate 한 트리의 보정 크기 수렴 빠름, 불안정 안정적, 트리 더 필요 n_estimators 트리 개수 과적합 위험 과소적합 feature_fraction 트리당 사용 피처 비율 다양성↓ 일반화↑ bagging_fraction 트리당 사용 샘플 비율 안정성↓ 분산↓ bagging_freq bagging 적용 주기 랜덤성↑ 결정적
5) CatBoost
: 범주형(categorical) 피처가 많은 데이터에서 강한 GBDT 계열 모델
- 부스팅 모델에서 범주형 처리는 원-핫 인코딩/타깃 인코딩 등 전처리 선택이 성능과 누수(leakage)에 큰 영향을 주는데, catBoost는 이 문제를 모델 내부 설계로 완화
- 강점: 범주형 피처를 비교적 자연스럽게 다룰 수 있도록 설계
- 특징: 타깃 누수(target leakage)를 줄이기 위한 인코딩/학습 전략을 포함
- 실무 포인트
- 범주형 피처가 많고 전처리를 최소화하고 싶을 때 유리
- 기본 세팅만으로도 강한 성능이 나오는 경우가 많음.
정리
| 모델 | 핵심 아이디어 | 강점 | 주의점 |
|---|---|---|---|
| AdaBoost | 오분류 샘플 가중치 ↑, 다음 학습기 집중 | 직관적 부스팅, 단순 구조 | 노이즈/라벨 오류에 민감 |
| GBDT | residual/gradient를 다음 모델이 학습 | 손실함수 기반 범용성 | 순차 학습으로 느릴 수 있음 |
| XGBoost | GBDT + 정규화/최적화/실무 기능 | 성능·안정성·기능 밸런스 | 파라미터 많음 |
| LightGBM | leaf-wise + 히스토그램 기반 | 속도·대규모 데이터 강점 | 작은 데이터 과적합 주의 |
| CatBoost | 범주형 처리 내장 + 누수 완화 | 범주형 많은 데이터에 강함 | 데이터/설정에 따라 속도 차이 |
4. Stacking/Blending
: 서로 다른 모델들의 예측값을 다시 입력으로 사용해 최종 모델을 학습하는 앙상블 방식
1) Stacking
: 교차 검증(Cross Validation)을 이용해 각 베이스 모델의 out-of-fold 예측값을 생성하고, 이를 입력으로 메타 모델을 학습하는 방식
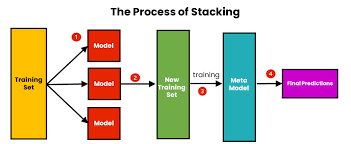
- 동작 흐름
- 데이터를 K-fold로 분할
- 각 fold에서:
- 일부 데이터를 학습용으로 사용
- 나머지 fold에 대해 예측 생성
- 모든 샘플에 대해 학습에 사용되지 않은 예측값(OoF) 확보
- OoF 예측값들을 새로운 피처로 사용해 메타 모델 학습
- 핵심 특징
- 메타 모델은 훈련 데이터에 대해 본 적 없는 예측값으로 학습됨.
- 데이터 누수(data leakage)를 구조적으로 방지
- 데이터 활용 효율이 높음
=> 안전하지만 구현이 복잡한 앙상블
# Bagging
최종 = (RF + XGB + NN) / 3
-> 새 모델을 동등하게 취급
# Stacking
“이 상황에서는 RF를 더 믿자”
“이 구간에서는 XGB가 잘 맞는다”
“이 영역은 NN이 강하다”
-> 최종 = 0.6*RF + 0.3*XGB + 0.1*NN
=> Bagging은 모델 하나의 불안정성을 여러 개 평균내어 안정화시키고, Stacking은 모델마다 잘하는 영역이 다르니까 그 관계를 학습하는 원리2) Blending
: 데이터를 학습용(train)과 검증용(hold-out)으로 분리한 뒤, 학습용 데이터로 베이스 모델을 학습하고, 검증용 데이터에 대한 예측값을 입력으로 메타 모델을 학습하는 방식
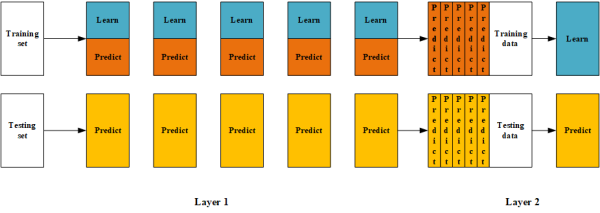
- 데이터를 train / hold-out으로 한 번 분리
- train 데이터로 베이스 모델 학습
- hold-out 데이터에 대한 예측값 생성
- 해당 예측값을 입력으로 메타 모델 학습
- 구현이 단순하지만 hold-out 데이터만 메타 학습에 사용됨
- 데이터 활용 효율이 상대적으로 낮음
정리
| 구분 | Stacking | Blending |
|---|---|---|
| 예측 생성 | K-Fold 기반 OoF | Hold-out 기반 |
| 메타 학습 데이터 | 전체 데이터 (OoF) | Hold-out 일부 |
| 데이터 누수 위험 | 낮음 | 상대적으로 높음 |
| 구현 난이도 | 높음 | 쉬움 |
| 데이터 효율 | 높음 | 일부 데이터 낭비 |
총정리
| 방법 | 줄이는 것 | 핵심 아이디어 |
|---|---|---|
| Bagging | Variance | 평균으로 안정화 |
| Boosting | Bias | 오답 보완 |
| Stacking | 둘 다 | 모델 조합 |
