(EMNLP2025 Finding, Accept)
Introduction
- 불충분한 안전 정렬 깊이는 초기 응답 토큰의 유해성 억제에만 집중하여 후속 토큰의 유해성을 간과함
이로 인해 prefilling 공격과 같이 초기 응답 토큰을 조작하여 모델의 내부 방어 체계를 우회할 수 있음
- 불안정한 내부 방어 메커니즘으로, 기존 방어 방법들은 반복적인 Jailbreak 공격이나 거부 방향 조작과 같은 공격에 쉽게 뚫림
→ fine-tuning 과정에서 확률적으로 거부 방향을 계층별 및 토큰별로 ablation함으로써 모델이 Jailbreak 상태로부터 거부 메커니즘을 동적으로 적용하도록 유도하는 DeepRefusal 제안
Methonology
각 계층 l∈[L]과 프롬프트 이후 토큰 위치 i∈[I]에 대해 유해한 프롬프트(Dharmful(train))와 무해한 프롬프트(Dbenign(train))의 평균 activation을 계산:
μi(l)=∣Dharmful(train)∣1t∈Dharmful(train)∑hi(l)(t)νi(l)=∣Dbenign(train)∣1t∈Dbenign(train)∑hi(l)(t)
두 평균 벡터의 차이가 후보 거부 방향 ri(l)=μi(l)−νi(l)을 정의
DeepRefusal은 두가지 방식의 확률적 활성화 제거(Probabilistic Activation Ablation, PAA)를 통해 Jailbreak 시나리오를 시뮬레이션
-
레이어별 PAA (Layer-wise PAA): Ql∼Bernoulli(p)로써 각 레이어 l∈[L]에서 확률적으로 거부 방향 r^을 제거할지 여부 개입. 모델의 다양한 깊이에서 내부 안전 메커니즘이 손상된 적대적 조건을 시뮬레이션하여, 모델이 전체 레이어 깊이에 걸쳐 거부 행동을 강화하도록 유도
h′←h−Ql(r^r^⊤h)
-
토큰별 PAA (Token-wise PAA): Ml,t∼Bernoulli(p)로써 레이어 l과 토큰 위치 t에서 확률적으로 개입. 특정 토큰이 조작되거나 억제되는 적대적 조건을 시뮬레이션하여, 다양한 입력에 대해 거부 행동을 강화하도록 유도
ht(l)′=ht(l)−Qml×Mml,tr^r^⊤ht(l)
Attention, Multi-Layer Perceptron (mlp), Residual Stream 모듈에 PAA 적용
DeepRefusal은 (x, y) (무해한 지시와 안전한 응답), (x', y'≤k, y) (prefilling 공격을 시뮬레이션하기 위해 응답의 유해 접두사 k∼Uniform[20,25]를 추가한 유해 프롬프트에 대한 안전한 응답)을 입력 데이터로 하며, 다음 목적 함수를 최소화하도록 fine-tuning됨
θminα×E[−logπθ(y∣x′,y′;{h(l)′;}l=1L)]+(1−α)×E[−logπθ(y∣x;{h(l)′}l=1L)]
Result
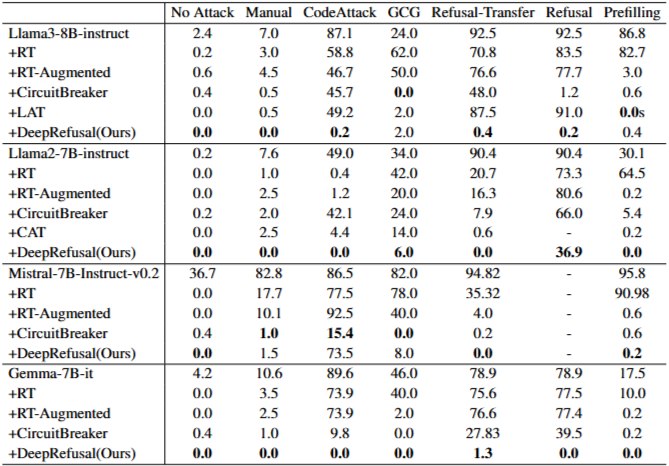 Table 1: Several representative jailbreak methods were selected for evaluating safety alignment. The robustness is measured by ASR(%). Refusal-Transfer represents the refusal direction of the instruction-tuned model. The Refusal-Transfer in Mistral models is obtained after the Refusal Training
Table 1: Several representative jailbreak methods were selected for evaluating safety alignment. The robustness is measured by ASR(%). Refusal-Transfer represents the refusal direction of the instruction-tuned model. The Refusal-Transfer in Mistral models is obtained after the Refusal Training
