(AAAI 2025, Accept)
Introduction
사용자가 업로드한 소량의 악성 데이터만으로도 LLM 모델의 미세 조정을 미묘하게 조작하여 모델의 안전 정렬 상태를 손상시킬 수 있음
→ 미세 조정 전후의 safety-critical 가중치의 유사도 차이를 기반으로 LLM의 안전 정렬을 복원하는 train-free 프레임워크인 Neuron-Level Safety Realignment (NLSR) 제안
Methonology
-
Construction of a Safety Reference Model: Super-aligned 모델 를 생성. 는 초기 미세조정된 모델 처럼 안전성이 약한 LoRA 가중치이며, 은 안전성이 강하게 정렬된 안전성 특화 모델의 LoRA 가중치임
모델 의 LoRA 가중치인 We를 구하는 수식에서 는 $W{strong}$의 유무에 따라 값이 달라짐
이 존재하는 경우 는 이 되며, 존재하지 않는경우 DPO, RLHF 등의 최적화 기법을 바탕으로 preference-alinged된 모델의 LoRA 가중치를 로 함. 이때 의 존재 여부 판단은 그 모델의 안전성 정렬 정도를 바탕으로 주관적으로 판단함. 이 없으면 최소한 preference-alinged된 모델이라도 있어야 됨
만큼 의 가중치는 상쇄되고 의 가중치가 증폭되면서 는 안전성 관련 가중치가 강조되는 행렬을 가짐 -
Recognition of Safety-Critical Neurons: 안전-중요 뉴런을 식별하기 위해 지정된 희소성 비율(sparsity rate) PSR에 따라 LoRA 가중치에 rank reduction을 적용. 원본 출력과 근사 출력 간의 Frobenius norm 차이를 최소화하는 low-rank matrix 를 찾음
즉, 의 특이값 분해(Truncated SVD) 를 통해 안전성 관련 주요 가중치 행렬을 추출하고, 로써 원본 가중치 행렬 를 이 안전성 관련 주요 가중치에 투영함으로써, 를 만족하는 를 구함
이 때,
이 를 바탕으로 전체 뉴런 중 가중치 절대값 의 뉴런을 안전-중요 가중치라고 함 -
Restoration for Safety-Broken Neurons:
-
Probability-based Layer Pruning: indices를 바탕으로 안전-중요 가중치의 위치만 남기고 마스킹하는 를 구함
사용자의 미세조정에 의해 안전성이 훼손된 LoRA 가중치를 라고 하고 일 때, Super-aligned 모델의 LoRA 가중치 및 중 안전-중요 가중치만 남긴 행렬을 각각 와 로 함이 각각의 안전-중요 가중치만 남은 LoRA 가중치 간의 유사도를 비교하여 유사도가 높은 순으로 순위를 매김
순위를 바탕으로 Pruning probability 를 를 구성하고 Probability-based Layer Pruning 를 수행함. 이 때 은 기본 레이어 가지치기 확률, 는 증가 계수, 은 총 레이어 수
-
Neuron-Level Correction: 모든 레이어의 가지치기 상태 가 주어졌을 때, 의 LoRA 가중치는 로 변경됨으로써 훼손된 안전성을 복원함
이 때
-
Result
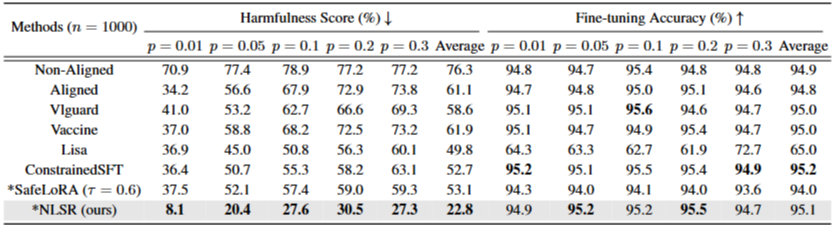 Table 1: Fine-tuning performance on SST2 with Llama3-8B, varying harmful instruction ratios from 0.01 to 0.3. Methods with require no extra training
Table 1: Fine-tuning performance on SST2 with Llama3-8B, varying harmful instruction ratios from 0.01 to 0.3. Methods with require no extra training
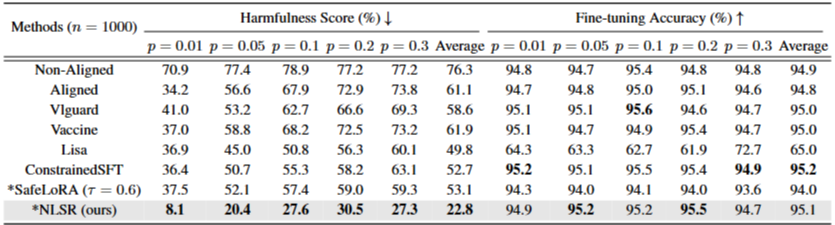 Table 2: Fine-tuning performance under different alignment methods, including SFT, DPO, ORPO, KTO, and SimPO. Methods marked with indicates that no additional training
Table 2: Fine-tuning performance under different alignment methods, including SFT, DPO, ORPO, KTO, and SimPO. Methods marked with indicates that no additional training
