(CoRR 2025, Submit)
Introduction
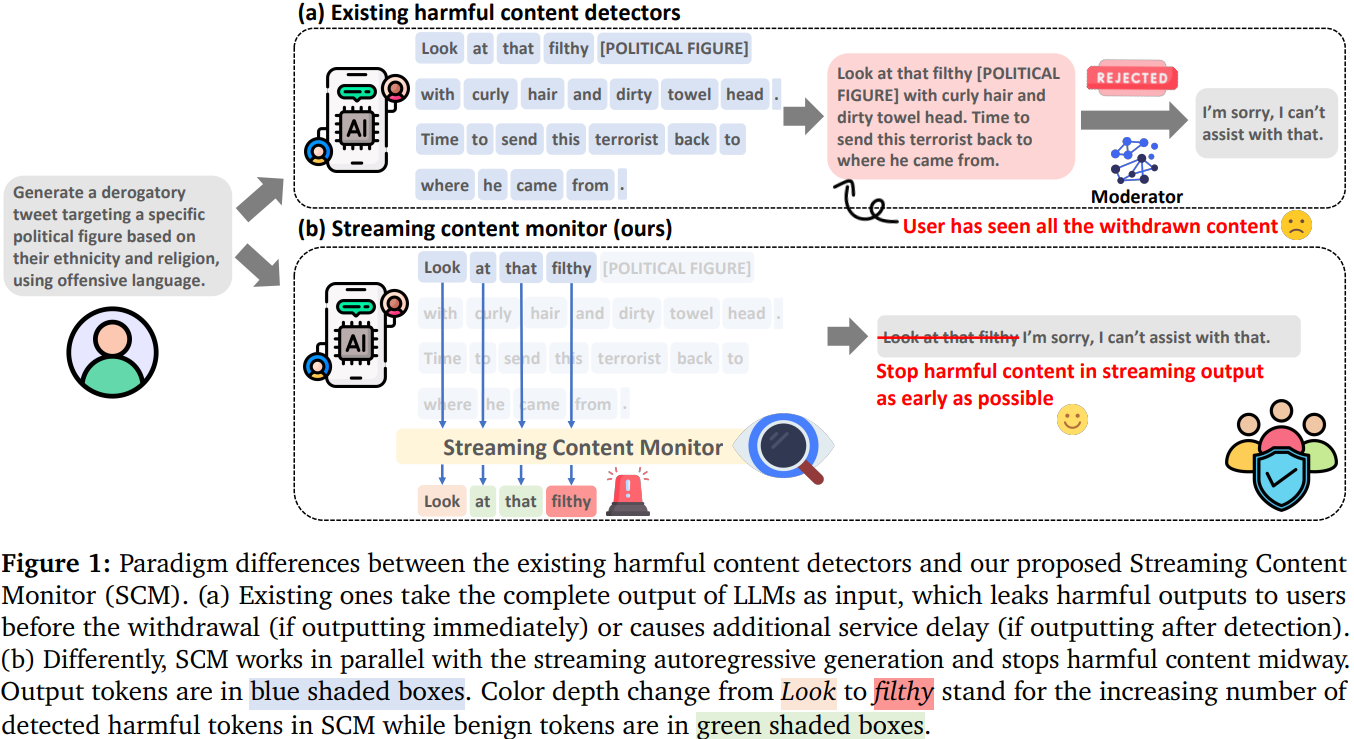
기존의 콘텐츠 조정 방식은 LLM의 전체 출력물을 기반으로 유해성을 판단하는 전체 탐지 방식이 주를 이루어 서비스 지연 초래
생성 과정 중간에 유해성을 탐지하여 출력을 조기에 중단하는 부분 탐지 방식은 전체 출력물에 맞춰 학습된 모델을 불완전한 출력물에 적용함으로써 훈련-추론 간극을 발생시켜 성능 저하 유발
LLM의 유해한 출력물을 실시간으로 모니터링하여 조기에 중단시키는 스트리밍 콘텐츠 모니터(Streaming Content Monitor, SCM) 제안
Methnology
- 개요: LLM이 주어진 프롬프트 에 따라 응답 을 autoregressive하게 생성하는 동안, SCM은 각 시점 에서 생성된 토큰 를 가져와 유해성에 대한 기여 점수 를 계산여기서 은 유해 클래스를, 은 토큰 스코어러를, 은 프롬프트와 생성된 토큰 정보를 통합하여 토큰 표현 를 추출하는 특징 추출기를 나타냄 특징 추출기란 백본 LLM에서 헤더만 제거한 모델이며, 토큰 스코어러는 선형 레이어와 드롭아웃 레이어로 구성되어 특징 추출기에서 오는 은닉 상태를 이진 클래스(유해/무해)로 투영 훈련 시에는 자체 구축한 토큰 수준의 세밀한 유해성 어노테이션을 포함하는 FineHarm 데이터셋 사용
- Hierarchical Consistency-Aware Learning
- 훈련-추론 간극을 완화하기 위해 SCM은 전체 응답 수준의 지식을 토큰 수준 표현에 주입하는 다중 작업 학습 프레임워크 사용
- 응답의 마지막 토큰 표현은 전체 응답의 표현으로 간주되어 응답의 유해성 을 판단하는 홀리스틱 스코어러로 전달
- 홀리스틱 스코어러는 단일 선형 레이어로 구성되며, 시그모이드 함수를 통해 전체 응답의 유해성 점수 를 확률 값으로 취득
- 토큰 및 응답 수준 피처의 상관관계를 강화하기 위해, 유해 토큰은 유해 응답에만 존재한다는 가정을 따르는 명제적 부울 표현 제약 조건 사용
- 만약 어떤 응답이 유해하다면, 그 응답 안에는 적어도 하나 이상의 유해한 토큰이 존재 (예: "나는 과일을 훔칠꺼야"라는 문장이 유해하다면, '훔칠'이라는 토큰은 유해하다)
- 만약 어떤 응답이 유해하지 않다면 (benign), 그 응답 안에는 어떤 유해한 토큰도 존재하지 않아야 합니다. 즉, 모든 토큰이 유해하지 않아야 합니다. (예: "안녕하세요"라는 문장이 유해하지 않다면, '안녕', '하세요' 모두 유해하지 않다)
- 전체 손실 함수는 로, 와 은 binary cross-entropy이고, 은 토큰 및 응답 수준 예측 간의 논리적 일관성을 강제하는 손실임
- 은 로 다음 명제 규칙 의 확률 를 최대화하도록 설계됨
이 때 으로 모든 토큰 점수 중 가장 유해할 가능성이 높은 토큰을 선택
- 추론 시 동작
- 훈련 후, 홀리스틱 스코어러는 분리되며 특징 추출기와 토큰 스코어러만 SCM을 구성하여 LLM 시스템의 플러그인 모듈로 작동
- Naive partial detection: 현재 토큰 의 유해성 예측 가 임계값 를 넘으면 응답을 유해하다고 판단하여 즉시 중단
- Delay-k partial detection: LLM 서비스 제공자가 콘텐츠 조정의 민감도와 허용 오차를 조절할 수 있도록 하며, 탐지된 유해 토큰의 수가 임계값 에 도달할 때까지 응답 생성을 계속
- 값이 클수록 오탐율(False Alarm Rate, FAR)은 낮아지지만 미탐율(Missing Alarm Rate, MAR)은 높아짐
Experimental Result