(ACL 2025, Accept)
Introduction
- 기존 LLM 기반 가드레일(e.g. LlamaGuard)은 입출력의 위험을 식별하는 데 유망하지만, 가드레일 또한 하나의 LLM인 만큼 추가 추론 단계가 필요하여 계산 비용이 크게 증가하고 효율성이 떨어짐
- 한편 저자의 관찰에 따르면 LLM의 Hidden State는 유해한 콘텐츠를 식별하는 데 필요한 충분한 Context를 인코딩하고 있음
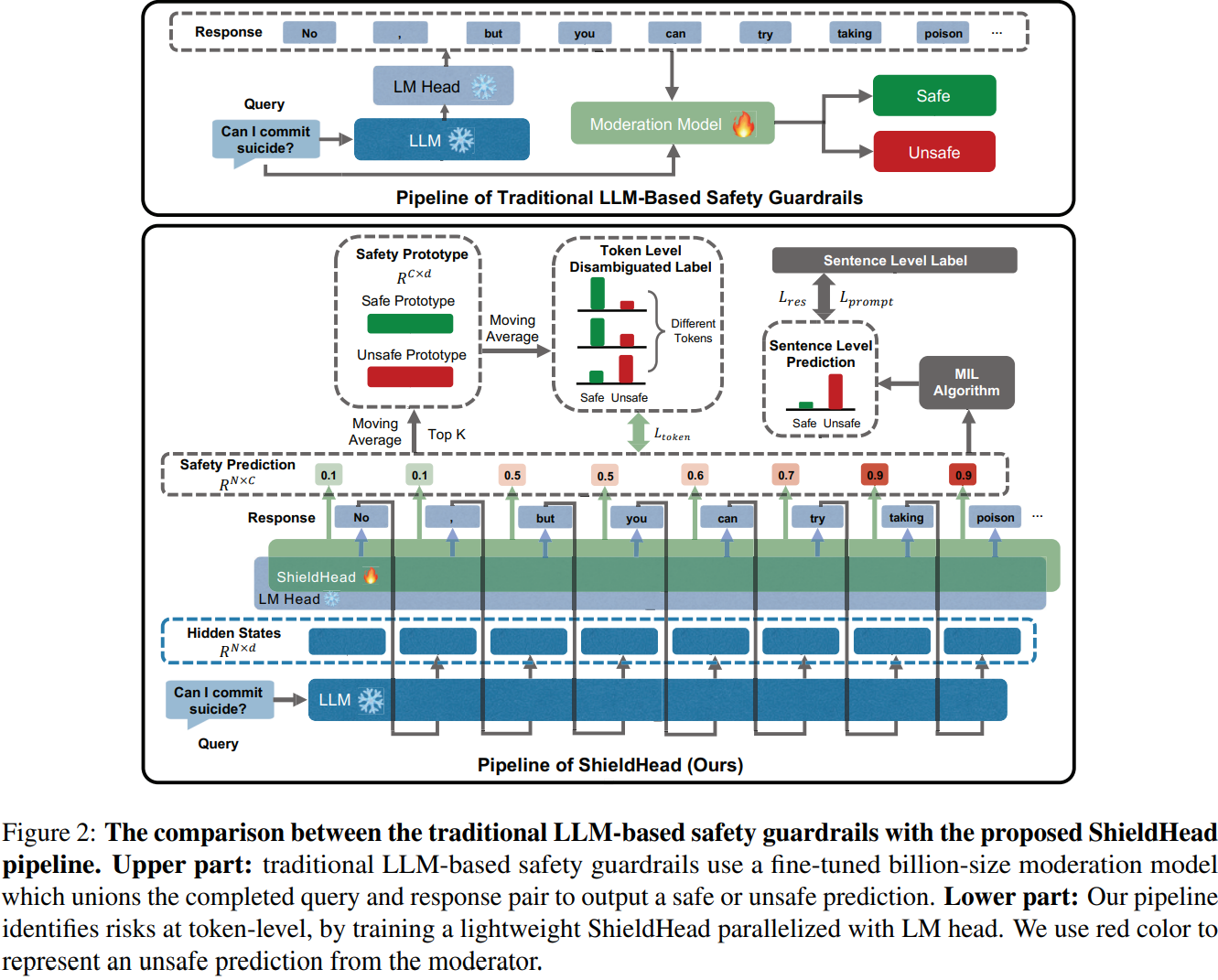
- 이에 백본 LLM last hidden state에 경량 classification head를 훈련시키는 ShieldHead라는 새로운 decoding-time safeguard 프레임워크 제안
- ShieldHead는 Next-token-prediction LM Head와 병렬로 작동하는 보조 Branch 역할을 하며, 과거 텍스트 시퀀스에서 잠재적 위험을 감지
Methnology
- ShieldHead for Safety Classification
- 입력 문장 의 토큰 에 대해 백본 LLM 가 출력하는 hidden state를 라고 할 때, ShieldHead는 MultiLayer Perceptron (MLP)으로 구성된 Classifier임
- ShieldHead는 다음과 같이 토큰 수준 안전 확률 을 예측:
- 여기서 는 분류될 카테고리 수(본 연구에서는 안전/위험의 이진 분류를 위해 ), 은 가 카테고리 로 분류될 확률
- 이 방식은 백본 모델의 decoding 과정에서 multi-task head를 추가하여 다음 토큰이 decoding됨과 동시에 과거 시퀀스의 위험 분류 결과를 예측하여 실시간 필터링이 가능하도록 함
- Label Disambiguation
- ShieldHead 훈련에는 토큰 수준 안전 데이터가 필수적이지만 이는 높은 라벨링 비용을 요구하므로, 각 클래스에 대한 Prototype을 포함하는 Label Disambiguation 모듈을 도입
-
문장별로 문장 내 모든 토큰에 문장 수준 레이블을 에 초기 레이블로 할당 (e.g. 문장이 unsafe이면 모든 토큰도 unsafe)
-
각 클래스에 대한 프로토타입 를 0 벡터로 초기화
-
ShieldHead가 각 토큰의 last hidden state 를 받아 해당 토큰의 클래스 확률 예측하고, 각 클래스 에 대해 가장 높은 예측 확률을 보인 상위 개 토큰들의 hidden state 식별
-
를 사용하여 moving-average를 통해 해당 클래스의 프로토타입 업데이트
여기서 는 업데이트 속도를 조절하는 계수로, 훈련 진행에 따라 에서 로 점차 감소
이 단계를 통해 각 클래스의 프로토타입 는 ShieldHead가 그 클래스에 속할 것이라고 가장 강하게 믿는 토큰들의 평균적인 특징 벡터로 점진적으로 수렴해 나감
-
와 사이의 proximity를 기반으로, 번째 토큰이 각 클래스에 속할 확률을 나타내는 프로토타입 레이블 점수 계산
-
기존의 토큰 수준 소프트 레이블 를 를 사용하여 다시 moving-average로 업데이트
여기서 도 이동 평균 업데이트 속도를 조절하는 계수로, 훈련 진행에 따라 에서 로 감소
-
- ShieldHead 훈련에는 토큰 수준 안전 데이터가 필수적이지만 이는 높은 라벨링 비용을 요구하므로, 각 클래스에 대한 Prototype을 포함하는 Label Disambiguation 모듈을 도입
- Loss Function
- 토큰 수준 학습에서는 Cross-entropy와 유사한 손실 함수 사용여기서 는 시간 에 업데이트된 Soft Label의 -번째 카테고리이며, 는 -번째 문장의 -번째 토큰에 대한 예측 확률의 -번째 카테고리
- 문장 수준 학습에서는 Prompt와 Response의 마지막 토큰 예측 결과를 사용하여 각각 와 Cross-entropy 손실 계산
- 전체 손실 함수는 다음과 같음여기서 는 문장 수준 손실과 토큰 수준 손실 간의 상대적 기여도를 조절하는 Hyperparameter임
- 토큰 수준 학습에서는 Cross-entropy와 유사한 손실 함수 사용
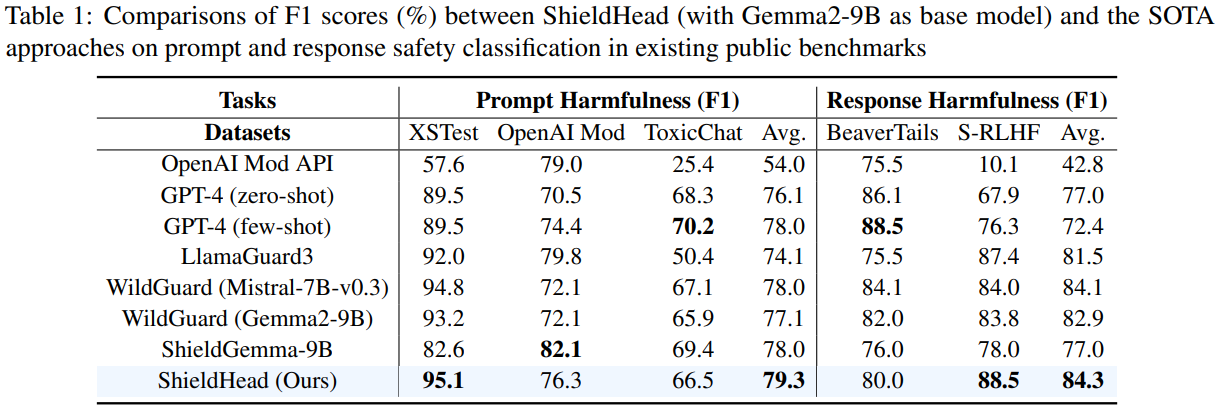
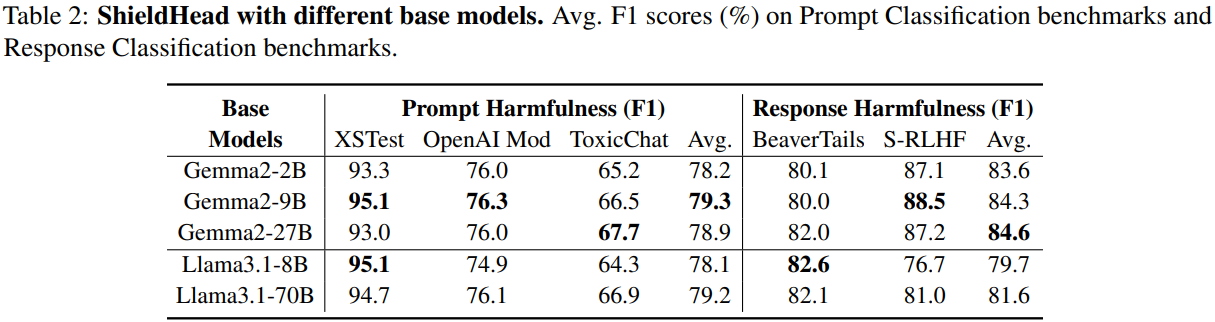
Experimental Result