(COLM 2025, Accept)
Introduction
- 기존 방어 방식은 LLM의 유용성을 저하시키거나 상당한 오버헤드 및 지연 시간을 발생시키는 문제가 있음
- SecurityLingua는 이러한 한계를 극복하기 위해 security-aware prompt compression 사용
Methonology
- 악의적인 의도 파악을 위한 프롬프트 압축
- 입력 프롬프트의 진정한 의도를 식별하도록 설계된 프롬프트 압축기 훈련
- 적대적 프롬프트의 악의적인 의도를 감지하는 데 중점을 둠
- 시스템 프롬프트를 통한 의도 강조
- 압축된 프롬프트에서 추출된 의도 정보를 원래의 사용자 프롬프트와 함께 시스템 프롬프트를 통해 대상 LLM에 전달
- LLM이 요청의 진정한 의도를 식별하고 내장된 가드레일을 활성화하도록 조력
SecurityLingua는 프롬프트 압축을 토큰 분류(token classification) 문제로 정의 → 각 토큰을 유지할지 또는 폐기할지 결정
- 압축기 구조: 사전 학습된 Transformer encoder (e.g. BERT)에 선형 분류 레이어 부착
- 훈련
- 개의 단어 로 구성된 원본 프롬프트가 주어졌을 때, Transformer encoder는 각 단어 에 대한 특징 벡터 를 생성
- 이후 선형 분류 레이어는 각 단어 에 대해 {preserve, discard} 레이블의 확률 분포 를 예측
- 모델은 cross entropy loss를 사용하여 훈련됨: 여기서 는 각 단어에 해당하는 실제 레이블
를 훈련하기 위해 원본 쿼리와 압축된 쿼리 쌍 형태의 데이터셋을 구축
각 원본 텍스트 의 토큰에 대해 이진 레이블 (보존/폐기)를 할당
- 데이터 생성: 보조 LLM을 사용하여 쿼리 쌍 생성
- 압축: 원본 쿼리에서 의도만 남기고 불필요한 정보를 제거하도록 보조 LLM에 요청
- 확장: 간결한 쿼리를 더 많은 맥락을 추가하여 긴 버전으로 확장하도록 요청 (원본 쿼리가 압축된 쿼리 로 사용됨)
- 데이터 레이블링: 데이터 생성 단계에서 얻은 원본 텍스트와 압축된 텍스트 쌍을 기반으로 각 토큰에 이진 레이블을 할당
- 품질 관리: 생성된 데이터의 품질을 평가하기 위해 두 가지 지표 사용
- Variation Rate (VR): 압축된 텍스트에 원본 텍스트에 없는 토큰의 비율을 정량화하여 환각발생 가능성 측정:
- Alignment Gap (AG): 원본 텍스트의 토큰 중 압축된 텍스트에 매칭되는 비율(Matching Rate, MR)과 압축된 텍스트의 토큰 중 원본 텍스트에 매칭되는 비율(Hitting Rate, HR)을 사용하여 데이터 레이블링의 정확도 평가
- 높은 VR이나 AG를 가진 예시는 최종 데이터셋에서 제외됨

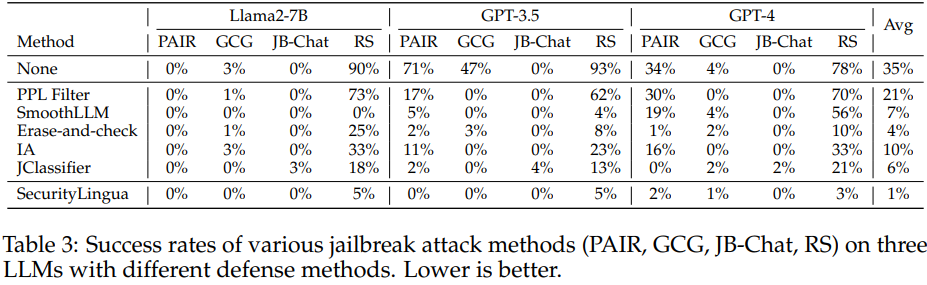
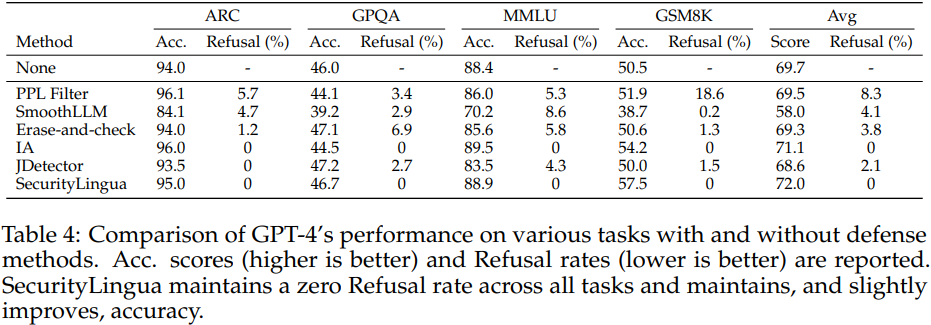
Experimental Result