(ACL 2025, Accept)
Introduction
- RLHF 및 DPO는 주로 단일 언어에 초점을 맞추고 있으며, 노이즈가 많은 다국어 데이터에 취약
- MPO는 잘 정렬된 주류 언어의 안전 역량을 활용하여 다양한 목표 언어 전반에 걸쳐 안전 정렬 개선
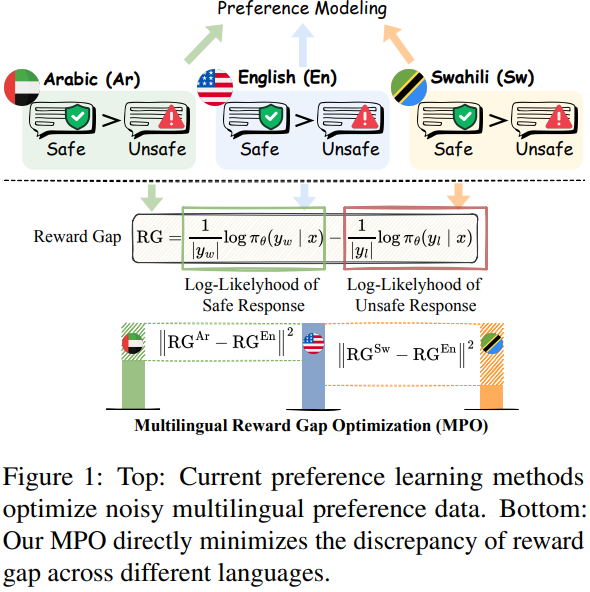
- 경험적 분석을 통해 주류 언어는 비주류 언어에 비해 리워드 갭, 즉 안전한 응답과 안전하지 않은 응답 간의 log-likelihood가 훨씬 크며, 이는 ASR과 반비례 관계를 가짐 → 리워드 갭이 클수록 ASR이 낮아져 안전 성능이 향상
- MPO는 비주류 언어의 리워드 갭이 주류 언어의 리워드 갭 수준에 달하도록 상호 간의 차이를 최소화
Methodnology
MPO는 SimPO(Simple Preference Optimization)에서 제안하는 average log-likelihood를 암시적 리워드로 채택
MPO의 전체 목적 함수는 다음 두 가지 항으로 구성됨
-
Reward Gap Alignment
- 큰 리워드 갭으로 나타나는 주류 언어의 강한 정렬과 비주류 언어의 약한 정렬 간의 불일치 최소화
→ 주류 언어의 안전 정렬을 비주류 언어로 전이와 는 각각 비주류 언어와 주류 언어이며, 는 하이퍼파라미터임
- 리워드 갭 와 는 다음과 같이 계산됨, , 은 비주류 언어의 입력 쿼리, 안전 응답, 안전하지 않은 응답이며, , , 은 주류 언어의 해당 쌍임
는 정책 모델, 는 레퍼런스 모델이며, 여기서 는 참조 모델에서 파생되므로 학습 가능한 파라미터 에 대해 상수로 간주
- 큰 리워드 갭으로 나타나는 주류 언어의 강한 정렬과 비주류 언어의 약한 정렬 간의 불일치 최소화
-
Hidden Representation Retention
주류 언어의 성능이 저하되지 않도록 마지막 토큰의 hidden representations을 손상시키지 않도록 제약
는 정책 모델에서 얻은 주도 언어 의 표현이고, 는 참조 모델에서 얻은 주도 언어 의 표현임
MPO의 최종 목적 함수는
MPO의 훈련은 비주류 언어에 대한 그래디언트 에 의해 이루어지며, 이는 가 비주류 언어에 대해 안전 응답 의 likelihood는 증가시키고 안전하지 않은 응답 의 likelihood는 감소시키는 방향으로 작동
이때 항은 목표 언어의 리워드 갭과 주도 언어의 리워드 갭을 비교하여 그훈련의 방향과 정도를 조절
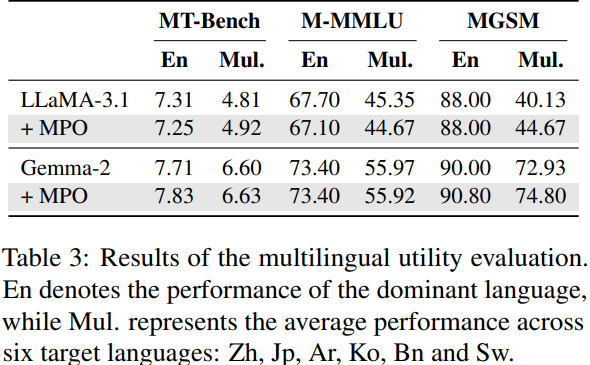
Experimental Result