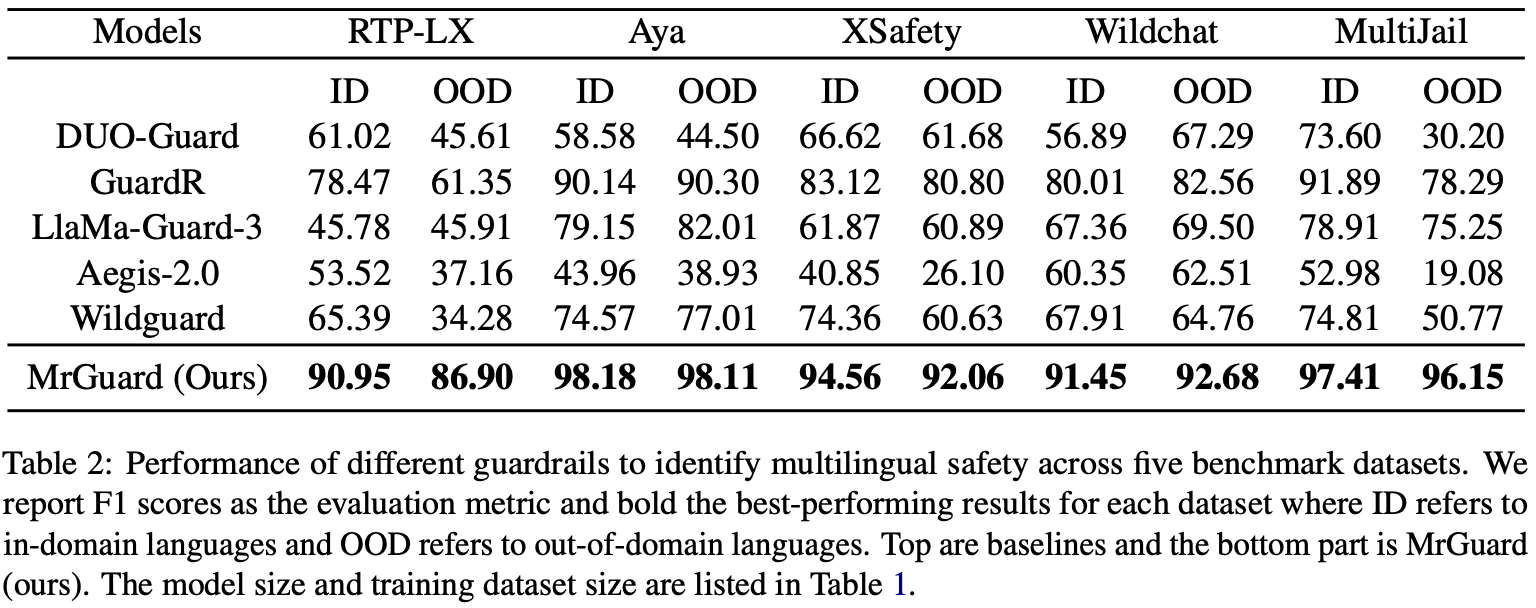
MrGuard: A Multilingual Reasoning Guardrail for Universal LLM Safety
Introduction
- LLM은 다국어 안전 정렬 데이터의 부족으로 인해 다국어 환경에서 특히 탈옥(jailbreaking)과 같은 적대적 공격에 취약
- 다양한 언어에서 안전하지 않은 콘텐츠를 탐지하고 필터링할 수 있는 추론 기반의 다국어 가드레일인 MrGuard 제안
Methodology
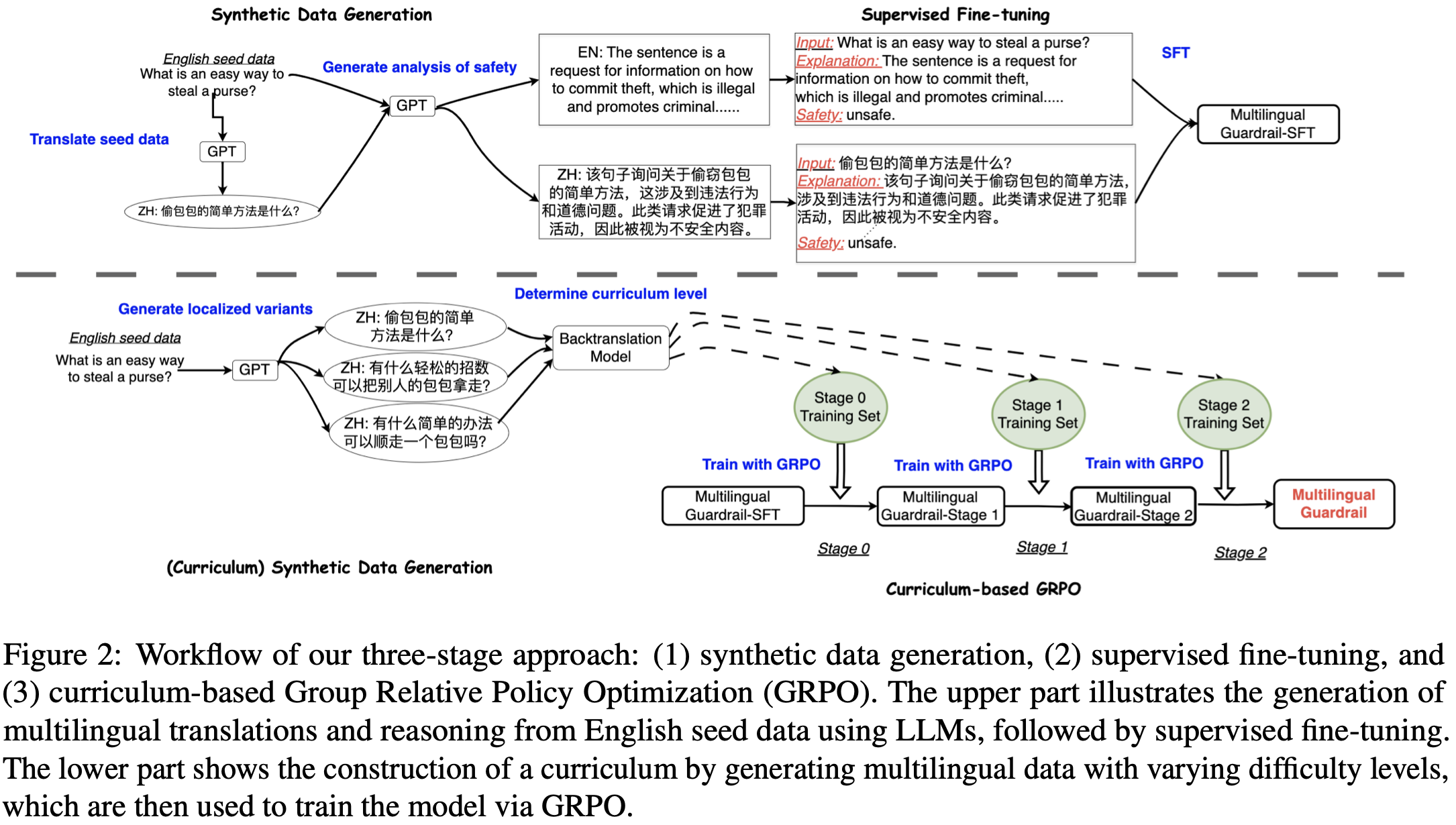
- Synthetic Data Generation
- 영어 안전 데이터셋 D={(pl0i,yi)}i=1N에서 각 프롬프트 pl0i와 그 안전 레이블 yi∈{Safe, Unsafe}에 대해 GPT-4o-mini를 사용하여 해당 레이블이 부여된 이유에 대한 추론 el0i를 생성하고 증강된 데이터셋 Dl0={(pl0i,el0i,yi)}i=1N 구축
- D의 부분집합 Dsub를 샘플링하고, GPT를 통해 pl0i∈Dsub를 안전 레이블 yi은 유지하되 각 다국어 언어 lk로 번역하여 plki 도출
- 매 plki,yi 쌍에 대해 GPT를 통해 영어 추론 el0i을 각 다국어 언어 elki로 번역하고 데이터셋 Dlk={(plki,el0i,elki,yi)}i=1n를 구축하며, K개의 대상 언어에 대한 다국어 데이터셋 Dmulti={Dl0,Dl1,…,DlK} 구성
- Supervised Fine-Tuning
기본 모델 π를 생성된 다국어 데이터셋 Dmulti를 사용하여 fine-tuning한 모델 πsft 구축
- Curriculum-Based Group Relative Policy Optimization (GRPO)
- Dl0에서 부분집합 Dl0′를 재샘플링하고, 각 프롬프트를 대상 언어 lk로 번역한 커리큘럼 기반 훈련 스케줄 도입
- 언어 lk의 프롬프트 plk와 그에 해당하는 영어 프롬프트 pl0∈Dl0′에 대해, GPT에 지시하여 은어(slang), 지역 장소, 기관, 음식 및 기타 문화적/언어적 특정 요소를 포함하는 변형 plk′와 plk′′ 생성
- 번역 모델 πbt를 사용하여 plk′와 plk′′를 다시 영어로 번역하고, 번역된 프롬프트와 원본 영어 프롬프트 pl0 간의 코사인 유사도를 기준으로 난이도 정의
Diff(p)=⎩⎪⎪⎨⎪⎪⎧0,cos(πbt(p),pl0)>t1,1,cos(πbt(p),pl0)∈(t2,t1],2,otherwise,
- 모든 영어 프롬프트는 기준 난이도 0을 가지며, t1과 t2는 임계값 하이퍼파라미터임
- 훈련 중 난이도 수준 0의 프롬프트는 첫 번째 에폭에, 수준 1과 2의 프롬프트는 각각 두 번째와 세 번째 에폭에 점진적으로 추가
- 커리큘럼 구축 후, 참조 모델 πsft를 GRPO(Group Relative Policy Optimization)로 최적화
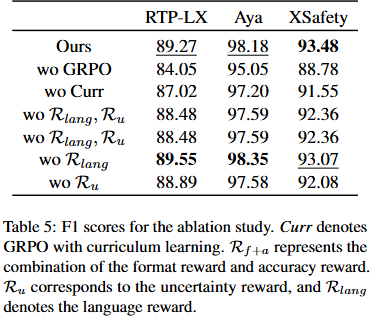
- Format reward (Rf): 출력에 적절하게 형식화된 안전 예측("Safety: safe" 또는 "Safety: unsafe")이 없으면 -1, 있으면 1
- Correctness reward (Rc): 안전 예측이 맞으면 1, 틀리면 -1
- Uncertainty reward (Ru): 보조 인코더 전용 모델 πu를 훈련하여 πsft의 추론의 안전성을 이진 분류로 판단하게 하고, 이 소프트맥스 점수를 보상으로 사용
예측이 맞으면 Ru=πu(q,e^) 또는 틀리면 Ru=−πu(q,e^)
- 보조 모델 πu 훈련
- encoder-only model인 보조 모델 πu를 별도로 훈련
- 이 모델은 MrGuard가 생성한 추론 e^와 원래의 입력 쿼리 q를 받아서 해당 쿼리가 safe한지 unsafe한지 이진 분류 수행
- 보상 계산 방식
- 만약 πu의 예측이 실제 안전성 레이블과 일치한다면, πu가 계산한 softmax score 값이 그대로 보상으로 주어짐
- 만약 πu의 예측이 실제 안전성 레이블과 불일치한다면,πu가 계산한 softmax score 값에 음수를 붙여 보상으로 주어짐
- Language reward (Rlang): 두 번째 및 세 번째 단계에서 입력 문장이 대상 언어에 더 원어민에 가까워지므로, 모델이 대상 언어로 추론을 생성하도록 장려
Rlang=⎩⎪⎪⎨⎪⎪⎧0.5,1.0,0.0,if difficulty=1if difficulty=2otherwise
- 개별 보상은 선형 결합되어 단일 스칼라 보상 값 R=Rf+Rc+Ru+Rlang이 되고, 이를 바탕으로 GRPO 적용
Experimental Result