(ICML 2025, Accept)
Introduction
- 자율주행과 같은 실제 AI 응용에서는 안전이 최우선이며, 하나의 치명적인 위험도 용납될 수 없음
- 기존 CMDP(Constrained MDP) 접근은 사용자 지정 안전 예산에 의존하므로 필요 조건 이상의 최적 위험 수준을 학습하지 못함
- 불안전 확률을 최소화한 뒤, 가장 안전한 정책들 중에서 보상을 최대화하는 강화학습 프레임워크 MAXSAFE 제안
Methodology
-
State-Action Reachability Estimation Function (SA-REF)
- 현재 정책 하에서 상태 와 액션 에서 시작하여 불안전 상태 에 도달할 확률 SA-REF()를 정의
- SA-REF는 다음 Bellman 백업을 통해 계산될 수 있음 최적의 SA-REF()를 학습하며, 수렴을 보장하는 역방향 귀납법(backward induction)을 통해 가중치 업데이트
- 현재 정책 하에서 상태 와 액션 에서 시작하여 불안전 상태 에 도달할 확률 SA-REF()를 정의
-
Learning Optimal Action Masks
- 를 통해 상태 에서의 최소 불안전 확률 *$\zeta(s) := \min_{a\in A} \psi^(s, a)$를 정의
- 최적 액션 마스크 생성
- 학습 과정에서는 상수 를 포함하여 로 정의된 학습된 액션 마스크 사용
-
Safe Q-Learning Update
- 최적 액션 마스크가 적용된 Q-Learning
- 최적 액션 마스크가 적용된 Q-Learning
대규모 실험을 위해 2가지 훈련 기법 도입
-
Safety Polarization
불안전 상태-액션 쌍에 낮은 값을 할당하여 해당 액션의 선택을 억제하는 소프트 마스킹 기법 적용
-
Safety Prioritized Experience Replay (SPOM PER)
- 희소한 비용 신호 문제를 해결하기 위해, SA-REF의 시간차(Temporal-Difference) 에러에 기반하여 샘플의 우선순위()를 지정
- PER은 Off-policy 강화 학습의 샘플 효율성을 높이고 수렴 속도를 가속화하는 기법
- 리플레이 버퍼에서 샘플을 무작위로 추출하는 대신, TD(Temporal-Difference) 에러와 같은 특정 기준에 따라 각 전환에 우선순위를 할당
- TD 에러가 큰 전환은 학습에 더 유용하거나 예측과 실제 값 사이에 큰 차이가 있음을 의미하므로, 이러한 전환에 높은 우선순위를 부여하여 에이전트가 더 중요한 경험에 집중하도록 함
- 이며, 샘플링 확률 와 중요도 샘플링 가중치 사용
- 희소한 비용 신호 문제를 해결하기 위해, SA-REF의 시간차(Temporal-Difference) 에러에 기반하여 샘플의 우선순위()를 지정
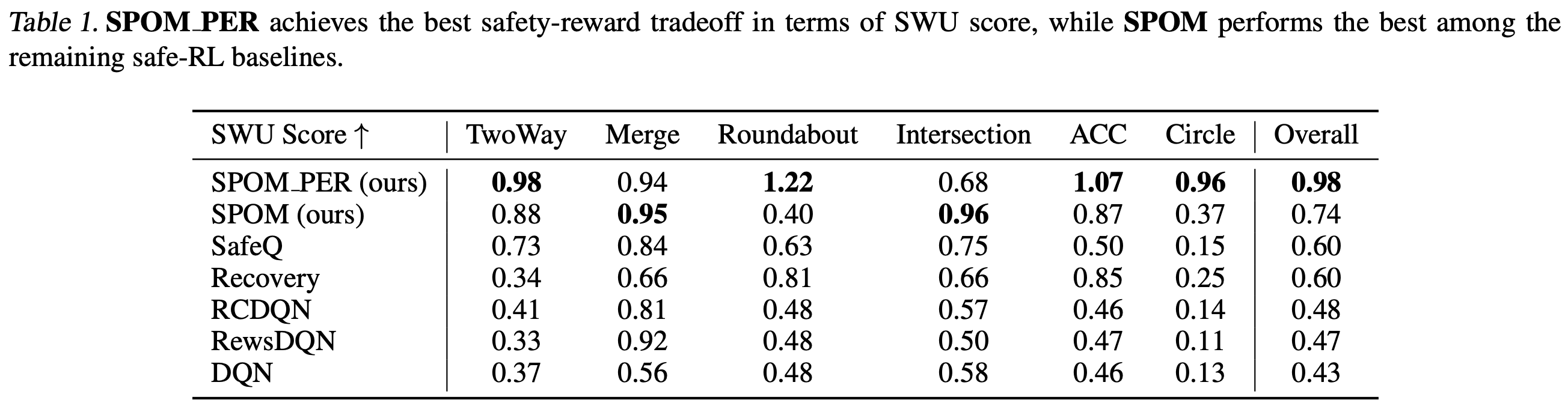
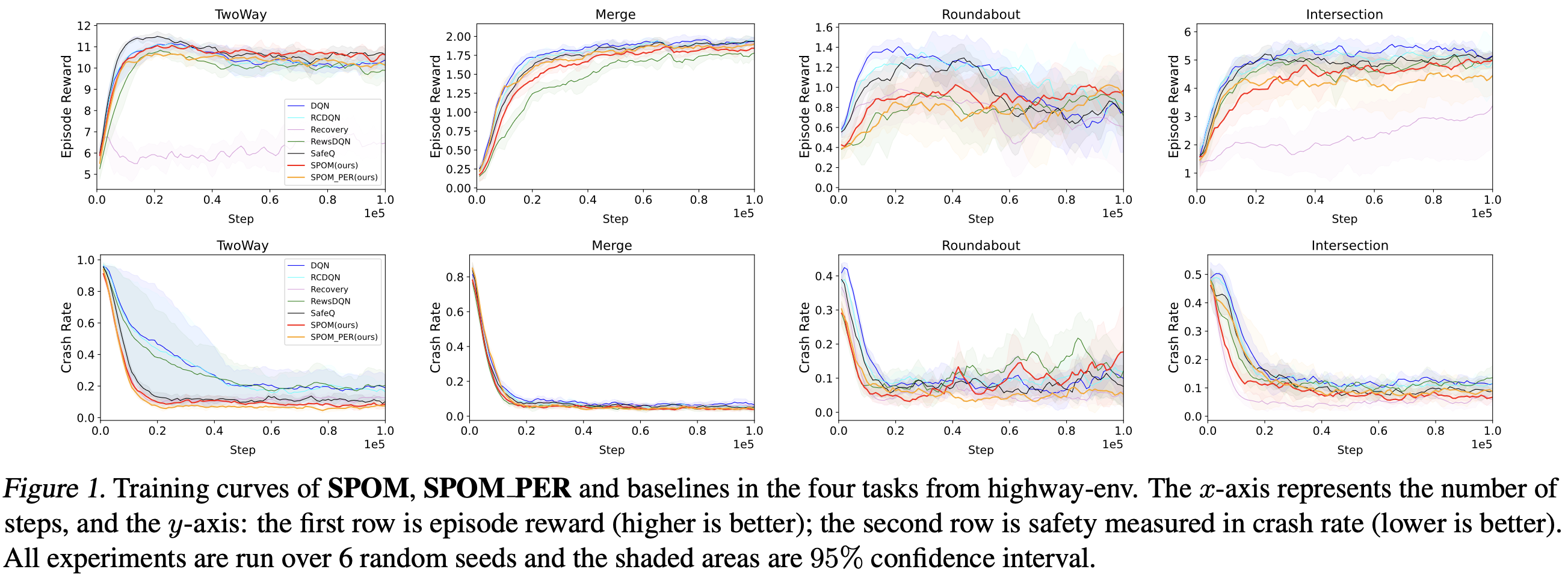
Experimental Result