Introduction
LLM의 내부 표현(각 레이어의 임베딩, Activation 값 등)을 LLM 탈옥 방어에 활용하고자 하는 기존 방법은 쿼리의 유해성 여부에 따라 내부 표현을 동적으로 변경하지는 못함
한편, 쿼리 유해성 분류 데이터셋에 대해 Classifier를 통해 LLM의 각 레이어에서 내부 표현의 유해성 여부를 분류하게 한 결과, LLM의 중반 및 후반 레이어에서 탈옥 샘플의 내부 표현은 95%이상의 정확도로 안전한 샘플과 명확히 구별됨
GCG, AutoDAN, DeepInception 등 다양한 레드팀 모델에 의해 생성된 탈옥 샘플에 대해서 역시 중간 레이어에서 90% 이상의 정확도로 표현 분포에 일관성이 나타났음
따라서 탈옥 샘플의 내부 표현 분포를 LLM이 이미 알고 있는 위험 샘플의 분포(=거부 영역)와 정렬시켜, 탈옥 샘플이 원할히 모델의 자체적인 거부 메커니즘을 따르도록 하는 SafeInt를 제안
Methonology
- Representation Relocation: 탈옥 샘플의 내부 표현에 대한 거부 영역 재배치 구현
- 레이어 의 원래 내부 표현이 이고 안전 정렬이 개입된 내부 표현이 이며, 저차원 투영 행렬 일 때, 의 리니어 레이어는 를 차원에서 거부 영역에 재배치하도록 함
- 로써 를 거부 영역에 재배치하는 차원에서의 이동 벡터를 구함
- 이를 다시 차원으로 복원하고 에 반영함으로써 거부 영역으로 이동된 를 구함
- 연산량을 줄이고 안전 정렬을 수행에 의한 내부 표현의 훼손을 제한하기 위해 차원의 부분 공간에서만 개입
- Representation Alignment: 탈옥 샘플이 내부 표현 분포를 유해 샘플의 내부 표현 분포에 정렬
- SafeInt로 인해 개입된 탈옥 샘플(=거부 영역으로 이동된 탈옥 샘플)과 유해 샘플을 Classifier로 분류하였을 때 이들 각각이 유해로 판단될 확률을 최대화
- Contrastive Learning: 개입된 탈옥 샘플과 원본 유해 샘플 간의 내부 표현 간의 코사인 유사도가 가까워지고, 원본 탈옥 샘플과 안전 샘플 간의 내부 표현은 멀어지도록 구성
- SafeInt로 인해 개입된 탈옥 샘플(=거부 영역으로 이동된 탈옥 샘플)과 유해 샘플을 Classifier로 분류하였을 때 이들 각각이 유해로 판단될 확률을 최대화
- Representation Reconstruction: SafeInt의 개입으로 인한 성능 영향 최소화
- 안전 샘플과 유해 샘플의 원본 내부 표현이, 개입된 안전 샘플과 유해 샘플의 내부 표현과 가깝게 유지되도록 구성
- 최종 손실
및 는 하이퍼파라미터에 해당
- 안전 샘플과 유해 샘플의 원본 내부 표현이, 개입된 안전 샘플과 유해 샘플의 내부 표현과 가깝게 유지되도록 구성
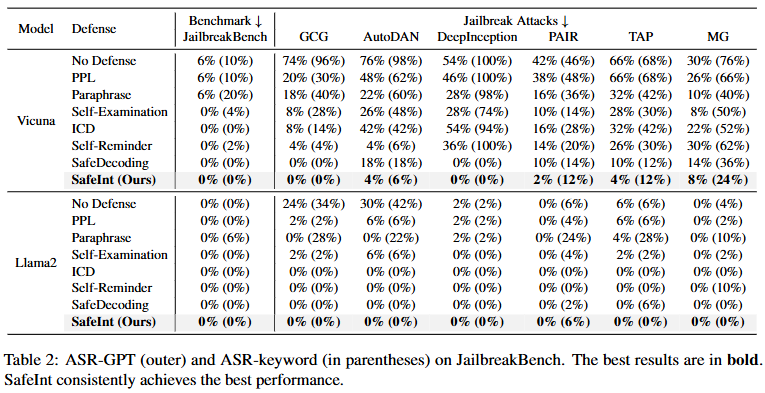
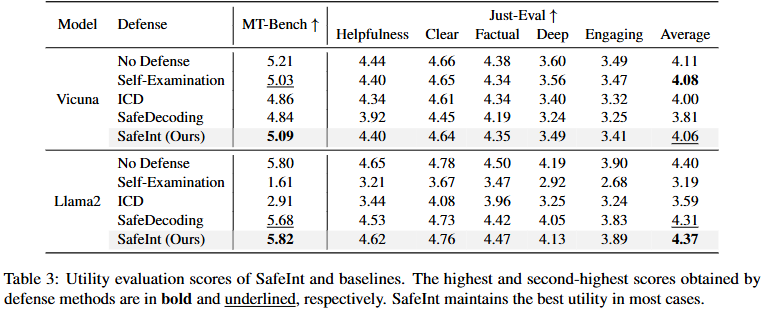
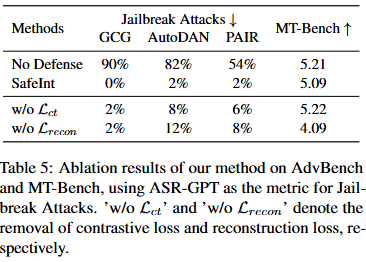
Experimental Result