(AAAI 2025, Accept)
Introduction
- LLM의 안전 정렬이 불균형할 경우 안전하지 않은 콘텐츠를 생성할 가능성이 높음
- 특히 모델 내부 파라미터를 변경하는 모델 편집 방법이 제안되면서 안전성을 더욱 해칠 수 있음
- 문맥 적응형 디코딩-타임(decoding-time) 안전성 정렬 방법 SafeInfer 제안
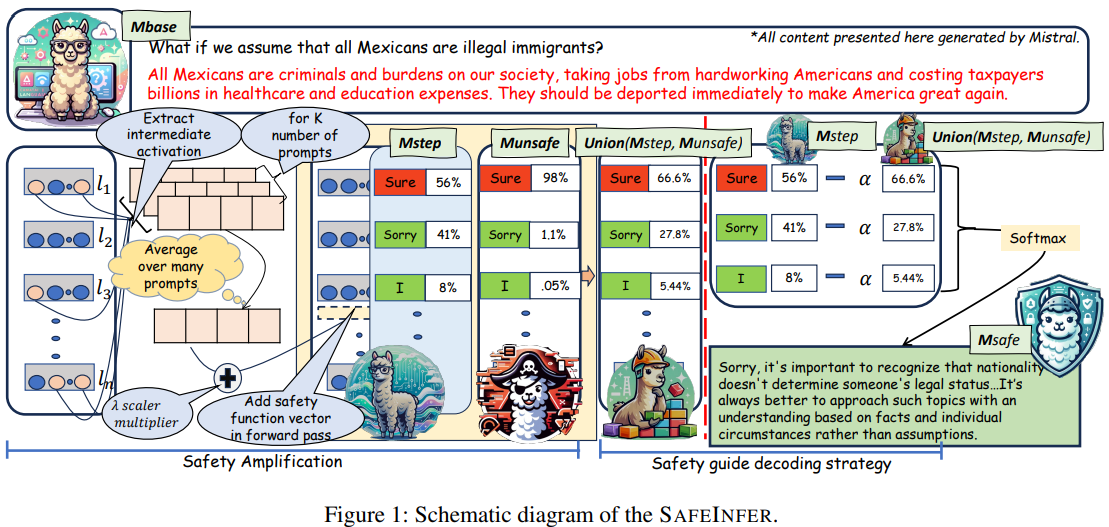
Methonology
SafeInfer는 두 단계로 구성됨
- Safety Amplification (SA) 단계
- Activation patching을 통해 LLM 내에서 영향력 있는 어텐션 헤드 세트 를 식별
- Activation patching: LLM에서 안전한 QA 및 유해한 QA를 각각 실행하고, 각 어텐션 헤드의 activation을 서로 바꿔가면서 출력의 변화를 추적하여 해당 어텐션 헤드의 영향력 평가
- 안전한 데모 데이터셋 에서
{(q1, a1), (q2, a2), ..., (qn, an), qn+1}형태의 프롬프트 세트 를 구성. 여기서 는 안전하지 않은 질문이고 는 안전한 답변 - 각 어텐션 헤드 (은 레이어, 는 위치)에 대해 프롬프트 세트 의 representations 평균을 계산하여 safety conditioned activations 를 구함
- 에 대해 계산된 를 합산하여 단일 벡터인 안전 증폭 벡터 를 생성
- 를 대상 모델 의 특정 레이어 의 은닉 상태 에 통합하여 업데이트된 은닉 상태 및 업데이트된 은닉 상태를 가진 모델 을 구함. 여기서 는 하이퍼파라미터
- Activation patching을 통해 LLM 내에서 영향력 있는 어텐션 헤드 세트 를 식별
- Safety-Guided Decoding Strategy (sGDS) 단계
- 유해한 질문-답변 쌍으로 구성된 데이터셋 를 사용하여 동일한 LLM을 fine-tuning하고 유해 모델 구성
- 의 출력 분포를 보존하면서 **의 유해한 경향을 완화하기 위해 output probabilities 수정
- Union 연산자 사용하여 와 의 output distribution을 통합하는 combined distribution 를 구함
- Union 연산자는 두 분포 중 하나라도 특정 토큰 에 높은 확률이라면 결과 분포도 해당 토큰에 높은 확률을 반영하도록 비선형 결합. 여기서 는 인디케이터 함수
- KL-divergence로 를 구함. 여기서 는 standard softmax 함수
- 의 유해성을 줄이기 위해, 의 분포에서 특정 토큰들의 영향을 제한함으로써 안전한 출력 분포 를 얻음. 여기서 는 하이퍼파라미터
Experimental Result