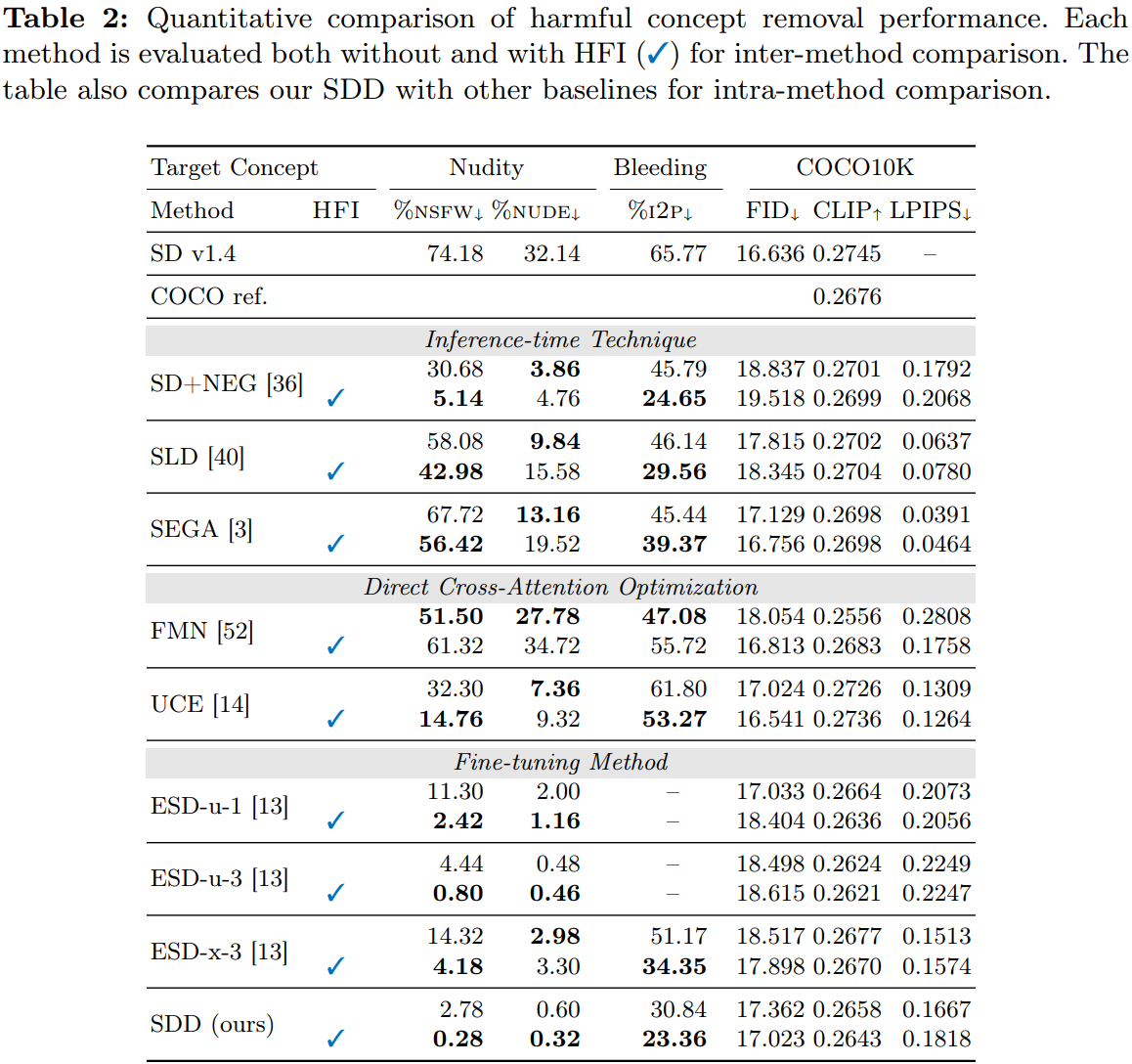
(ECCV 2024, Accept)
Introduction
대규모 텍스트-이미지 Diffusion 모델들이 유해하거나 저작권이 있는 콘텐츠를 생성할 수 있다는 사회적 우려
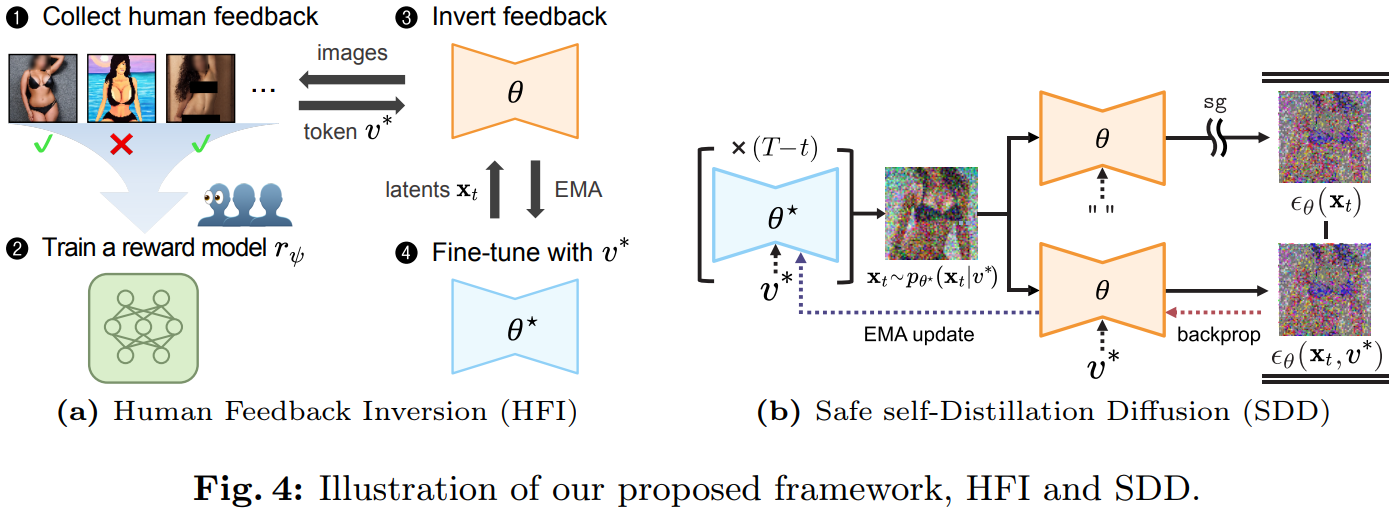
→ 모델이 생성한 이미지에 대한 인간의 피드백을 텍스트 토큰으로 응축하여 문제성 이미지의 완화 또는 제거를 유도하는 프레임워크 Human Feedback Inversion (HFI) 제안
Methonology
- Collecting and Modeling Human Feedback
- 원본 모델과 특정 컨셉(화가의 작풍, 유해성 종류 등)을 포함하는 프롬프트로 이미지 생성
- Human Feedback은 두 가지 종류로 나뉨
- Binary Feedback: 모델이 생성해서는 안되는 콘텐츠가 명확하고 이에 대한 가이드가 있는 경우 각 이미지에 대해 유해성 여부를 판단 (예: nudity)
Reward model 는 MSE loss를 사용하여 학습:
- 랭킹 피드백 (Ranking Feedback): 화가의 작풍과 같이 기준이 불분명하고 미묘한 개념의 경우 개의 이미지를 제시하고 1부터 까지 순위를 매기도록 요청
Reward model 는 Bradley-Terry model을 기반으로 NLL loss를 사용하여 학습:
- Binary Feedback: 모델이 생성해서는 안되는 콘텐츠가 명확하고 이에 대한 가이드가 있는 경우 각 이미지에 대해 유해성 여부를 판단 (예: nudity)
- 두 종류 모두 reward model 는 CLIP 임베딩을 점수로 매핑하는 MLP layer로 구성
- Inverting Feedback into Embeddings
- Diffusion 모델은 노이즈가 섞인 이미지 로부터 원래의 노이즈 을 예측하는 모델
- 수집된 피드백을 기반으로 해당 개념을 soft token으로 변환
- Textual Inversion을 활용하여 생성된 이미지의 기대 reward를 최대화하는 soft token 를 찾는 최적화 문제 정의
- 는 초기 "nudity", "artist", "bleeding"과 같은 단어의 임베딩을 기반으로 시작하여 업데이트
- 특정 컨셉에 대해 상위 K개의 점수를 받은 이미지들을 활용하는 reward-weighted sampler를 사용하여 최적화
- Safe Self-distillation Diffusion (SDD)
- SDD는 self-distillation 기반의 fine-tuning 방법
- student model를 , teacher model을 라 할 때 는 사전 학습된 모델에서 초기화되며, 이후 student model의 Exponential Moving Average (EMA)로 업데이트됨
- soft token 가 주어졌을 때 모델이 어떤 토큰도 주어지지 않은 것처럼 행동하도록, 즉 조건부 예측 가 비조건부 예측 와 유사해지도록 훈련:
이 때 은 stop-gradient 연산임
- Fine-tuning은 U-Net의 cross-attention layer에만 적용
Experimental Results