Introduction
- Large Reasoning Model(LRM)은 복잡한 태스크에서 뛰어난 성능을 보이지만 유해한 쿼리와 적대적 공격에 취약
- 기존의 Safety Alignment 방법인 SFT는 경험하지 못한 탈옥 프롬프트에 대한 일반화 능력이 부족
- safety aha moment라는 모델이 향후 답변을 안전하게 진행할지 여부를 결정하는 중요한 지표가 있는 것으로 나타나는 데, 이는 주로 LRM은 추론 중 쿼리 이해 과정 다음에 key sentence 생성에서 나타남
- 따라서 key sentence에서 safety aha moment를 더 잘 활성화하기 위해 2가지 보완적인 목표를 포함하는 SafeKey 프레임워크를 제안
Methonolodgy
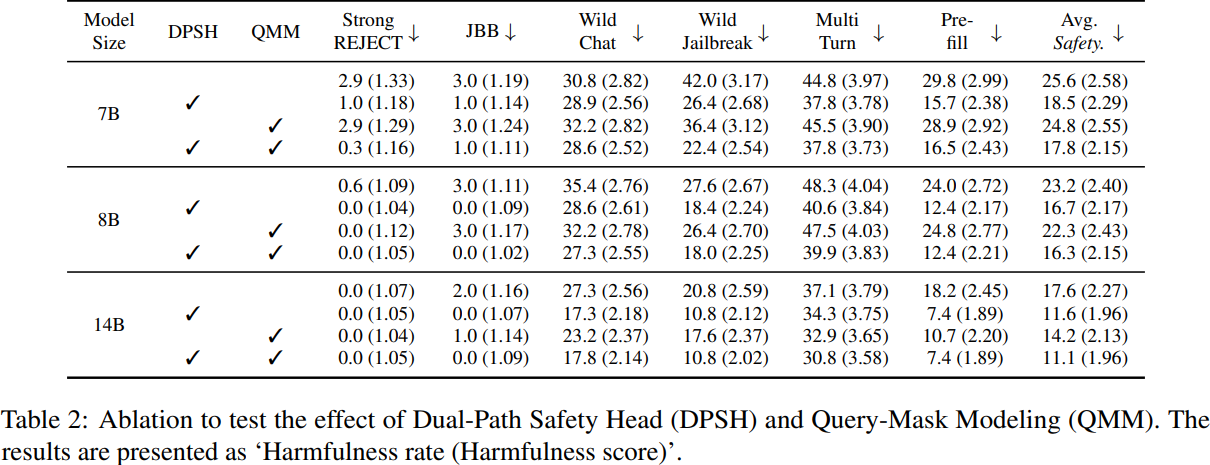
- Dual-Path Safety Head (DPSH): key sentence 이전의 모델 internal representations에 safety signal을 강화
- 모델의 마지막 hidden states를 입력으로 받아 쿼리의 안전성을 예측하는 두 개의 병렬 예측 헤드() 사용
- 는 입력 쿼리 와 쿼리 이해 과정 의 은닉 상태의 평균
- 는 쿼리 이해 과정 만의 은닉 상태 평균
- 두 예측 헤드는 binary cross-entropy를 사용하여 훈련여기서 는 실제 안전성 레이블이며 이 헤드들은 훈련 시에만 사용
- Query-Mask Modeling (QMM): 모델이 key sentence를 생성할 때 쿼리 이해 과정의 어텐션에 더 집중하도록 유도
- QMM 태스크에서는 입력 쿼리 토큰()을 마스킹하고, 모델이 쿼리 이해 과정()만을 바탕으로 key sentence()를 생성하도록 훈련여기서 은 마스킹된 입력 쿼리
- key sentence의 토큰()에 대해서만 교차 엔트로피 손실 계산경로를 통해 모든 학습 신호를 전달하여 에서 safety signal을 전달하는 파라미터와 어텐션 가중치를 증폭
- QMM 태스크에서는 입력 쿼리 토큰()을 마스킹하고, 모델이 쿼리 이해 과정()만을 바탕으로 key sentence()를 생성하도록 훈련
총 손실 함수:
여기서 은 원래의 언어 모델링 손실(language modeling loss)
Experimental Result