전에 포스팅에 이어서 본격적인 학습을 하기 전, 폴더명을 한글로 변환할 예정
폴더명 한글 변환
이 많은 파일을 하나씩 변환해보자.
(변환 완료..)

질병들을 출력했을 때, 한글로 변환한 질병들 출력 완..
Data Loading
파일 명이 아예 달라졌으므로, dataset loading부터 다시 시작하였다.
plants = []
NumberOfDiseases = 0
for plant in diseases:
if plant.split(' ')[0] not in plants:
plants.append(plant.split(' ')[0])
if plant.split(' ')[1] != '정상':
NumberOfDiseases += 1
print(f"Unique Plants are: \n{plants}") if plant.split(' ')[0] not in plants : plant 문자열을 공백 2칸 (' ')으로 나눈 후, 그 결과에서 첫 번째 요소 ([0])를 가져와서 plants 리스트에 있는지 확인함. plants 리스트는 중복을 허용하지 않음.
if plant.split(' ')[1] != '정상' : plant 문자열을 공백 2칸 (' ')으로 나눈 후, 그 결과에서 두 번째 요소 ([1])를 가져와서 이것이 '정상'이 아닌지 확인함. 이 부분은 해당 식물이 '정상'이 아닌 (즉, 병에 감염된) 경우 NumberOfDiseases 변수를 증가시켜 병에 감염된 이미지의 수를 계산함.
이전 코드와 달라진 점이 있다면, 농작물 구분을 ('___') 으로 했는데
지금은 (' ') 공백 2칸으로 구분 지어주었다.

총 14개의 농작물을 잘 구분하는 것을 확인할 수 있다!

질병에 대한 이미지 수 출력 완.
Visualizing a Graph
#plotting number of images available for each disease
index = [n for n in range(38)]
plt.figure(figsize=(20, 5))
plt.bar(index, [n for n in nums.values()], width=0.3)
plt.xlabel('Plant/질병', fontsize=10)
plt.ylabel('사용 가능한 이미지 수', fontsize=10)
plt.xticks(index, diseases, fontsize=5, rotation=90)
plt.title('농작물 질병의 이미지 생성')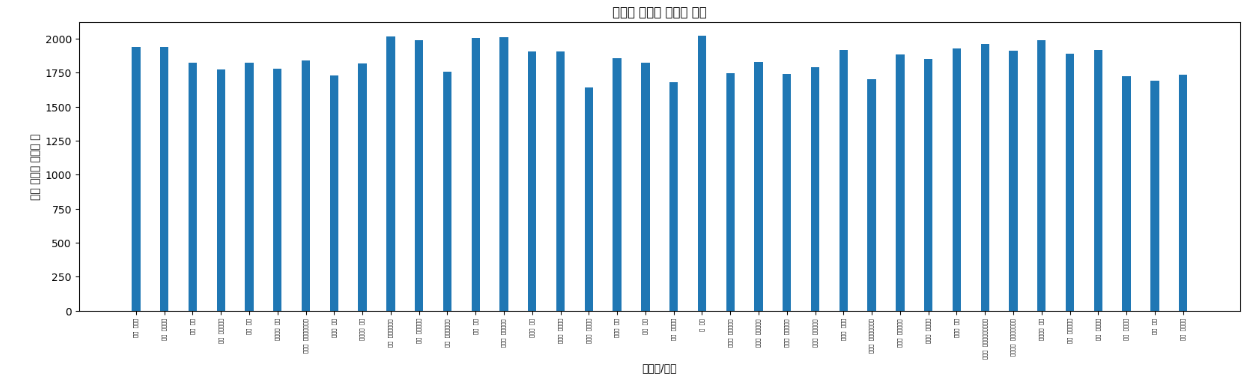
한글은 인식이 안되는 이슈발생 . . 💥
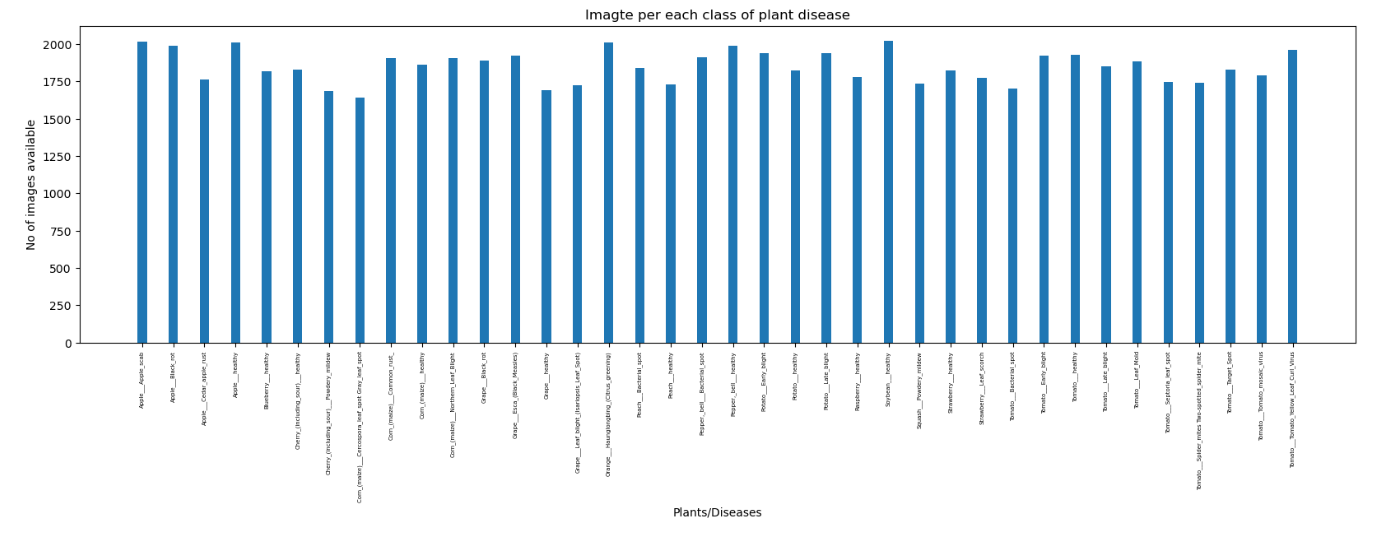
그래프 시각화는 Eng.ver인걸로
n_train = 0
for value in nums.values():
n_train += value
print(f"훈련에 사용될 이미지는 총 {n_train} 장 존재합니다.")
training에 사용될 총 이미지는 70295장이다.
Data Preparation of training
본격적인 데이터 훈련을 위한 준비이다.
Modeling
GPU Cuda
GPU 가능한지 CPU인지 확인 결과, CPU . . .
GPU가 가능하지 않아도 훈련이 가능할지 !!?!?!?!?!?!
다음 포스팅에 계속 . . . To be continued ...
