충격적인 사실 .. 🌀
저번에 설치하고 다운 받은 Dataset이 일반 식물 잎이 아닌 사과 나무의 잎과 관련한 질병 Data였다. 그래서 다시 시작된 Dataset 찾기 🥲
(하지만, 아무리 찾아도 우리가 원하는 반려식물처럼 일반 식물과 관련한 Data는 나오지 않았다.) 결국 농작물과 관련한 식물 질병을 판단하는 앱으로 변경 .
jupyter notebook kaggle 실행
1. kaggle download
2. kaggle info & config 확인
kaggle dataset 다운
1. Dataset download
저번주에 들었던 의문점
Q. 'Kaggle에서 Competition 탭에서만 Data를 다운받고 사용 가능한 것 같은데 Competition이 아닌 Datasets 탭에서의 data는 사용 못 하는 걸까 ?'
A. Datasets탭 data도 사용 가능!!!!!
이 의문점이 드디어. 해결되었다.
How to solve?!
!kaggle datasets download -d "다운받을 data 경로"
나의 경우는 사용할 dataset의 주소가 아래와 같다. "https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset"
따라서 "경로"에 "vipoooool/new-plant-diseases-dataset"을 입력해주었다. 이 방법말고 API를 이용한 다운 방법도 있는듯하다.

친절하게 저장된 파일 위치도 알려준다.
(다운 100%와 이렇게 압축 파일 생성도 확인)
2. Data file unzip

(압축 해제)
ResNet
본격적으로 훈련을 들어가기에 앞서, ResNet을 이용하여 이미지 훈련을 하려 한다.
ResNet은 CNN을 활용한 이미지 분류 알고리즘 중, 대표 인공지능 네트워크로 잔차를 최소화해준다.
라이브러리 설치
!pip install torchsummary
torchsummary?
모델의 구조도에 대한 요약(summary), 파라미터의 개수, 메모리 등을 확인
keras 형태로 모델을 사용하려면 torchsummary 라이브러리가 필요함!
import os
import numpy as np
import pandas as pd
import torch
import matplotlib.pyplot as plt
import torch.nn as nn
from torch.utils.data import DataLoader
from PIL import Image
import torch.nn.functional as F
import torchvision.transforms as transforms
from torchvision.utils import make_grid
from torchvision.datasets import ImageFolder
from torchsummary import summary
%matplotlib inline그 외에 필요한 라이브러리를 import 해주었다.
Data Loading
data_dir = "C:/Users/cyh24/New Plant Diseases Dataset(Augmented)/New Plant Diseases Dataset(Augmented)"
train_dir = data_dir + "/train"
valid_dir = data_dir + "/valid"
diseases = os.listdir(train_dir)
print(diseases)os.listdir() method : 지정한 디렉토리 내의 파일과 리스트를 리턴한다.

파일 내에 존재하는 diseases가 리스트의 형태로 출력되었다.
plants = []
NumberOfDiseases = 0
for plant in diseases:
if plant.split('___')[0] not in plants:
plants.append(plant.split('___')[0])
if plant.split('___')[1] != 'healthy':
NumberOfDiseases += 1NumberOfDiseases : 해당 클래스에 대한 이미지 수
plants[] : 모든 식물 리스트
diseases : 모든 질병 클래스 나열
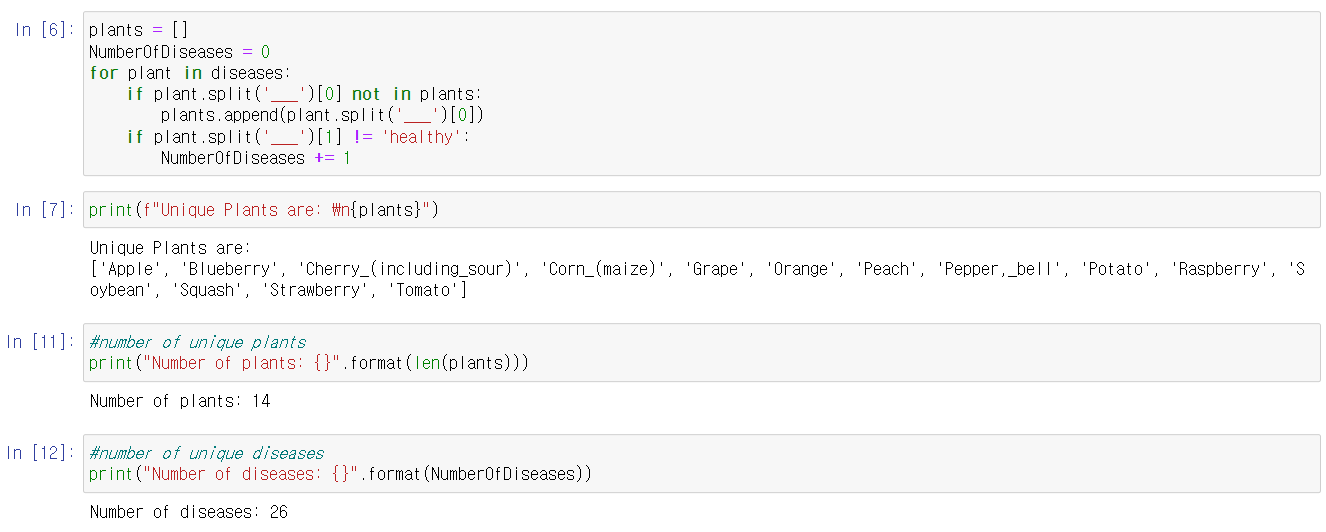
식물의 수 : 14
질병의 수 : 26으로 확인할 수 있다.
nums = {}
for disease in diseases:
nums[disease] = len(os.listdir(train_dir + '/' + disease))
img_per_class = pd.DataFrame(nums.values(), index=nums.keys(), columns=["no. of images"])
img_per_classnums[disease] = len(os.listdir(train_dir + '/' + disease)) : 각 질병 클래스 디렉토리에 있는 이미지 파일의 수를 세어 nums 딕셔너리에 저장함. 이 때, 디렉토리 내의 파일 수는 os.listdir() 함수를 사용하여 계산함. 이 정보는 disease를 키로 하여 딕셔너리에 저장함.
img_per_class = pd.DataFrame(nums.values(), index=nums.keys(), columns=["no. of images"]): nums 딕셔너리를 데이터프레임 형식으로 변환하여, 각 질병 클래스별로 이미지 수를 표시하는 데이터프레임을 생성함. 데이터프레임의 각 행은 질병 클래스를 나타냄.
no. of images : 열은 해당 클래스의 이미지 수를 나타냄.
img_per_class : 데이터프레임 img_per_class을 출력하여 결과를 표시함.
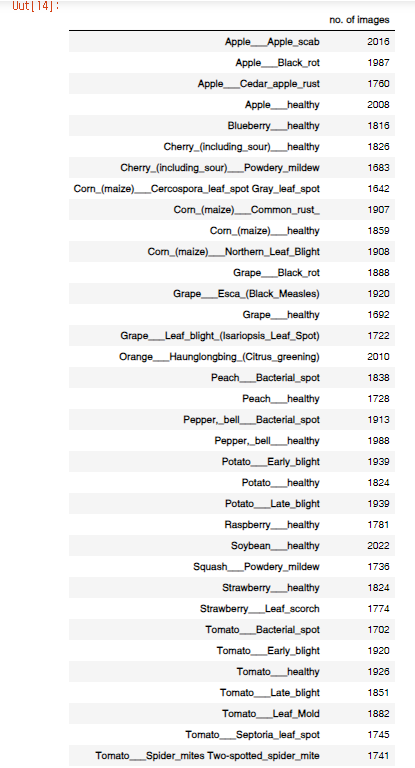
각 질병에 대한 이미지 수가 출력되었다.
문제 발생 🌀
잘 진행되나 싶었으나, 이 모든 질병 이름이 영어로 표기된 것을 자각하고 .. .csv파일이 있는 dataset의 경우 엑셀 파일에서 표기법을 한글로 변경하면 되지만, 이처럼 따로 파일이 존재하지 않고 폴더 이름 자체가 영어로 표기되어 있는 경우엔 일단 폴더명을 한글로 변환해주는 방법을 택하였다.
한글 변환부터 해보고 훈련을 이어나가도록 하겠다.
다음 포스팅에서 처음부터 다시 작성 start ..
도움 됐던 사이트
dataset download_1
dataset download_2
ResNet
ResNet
