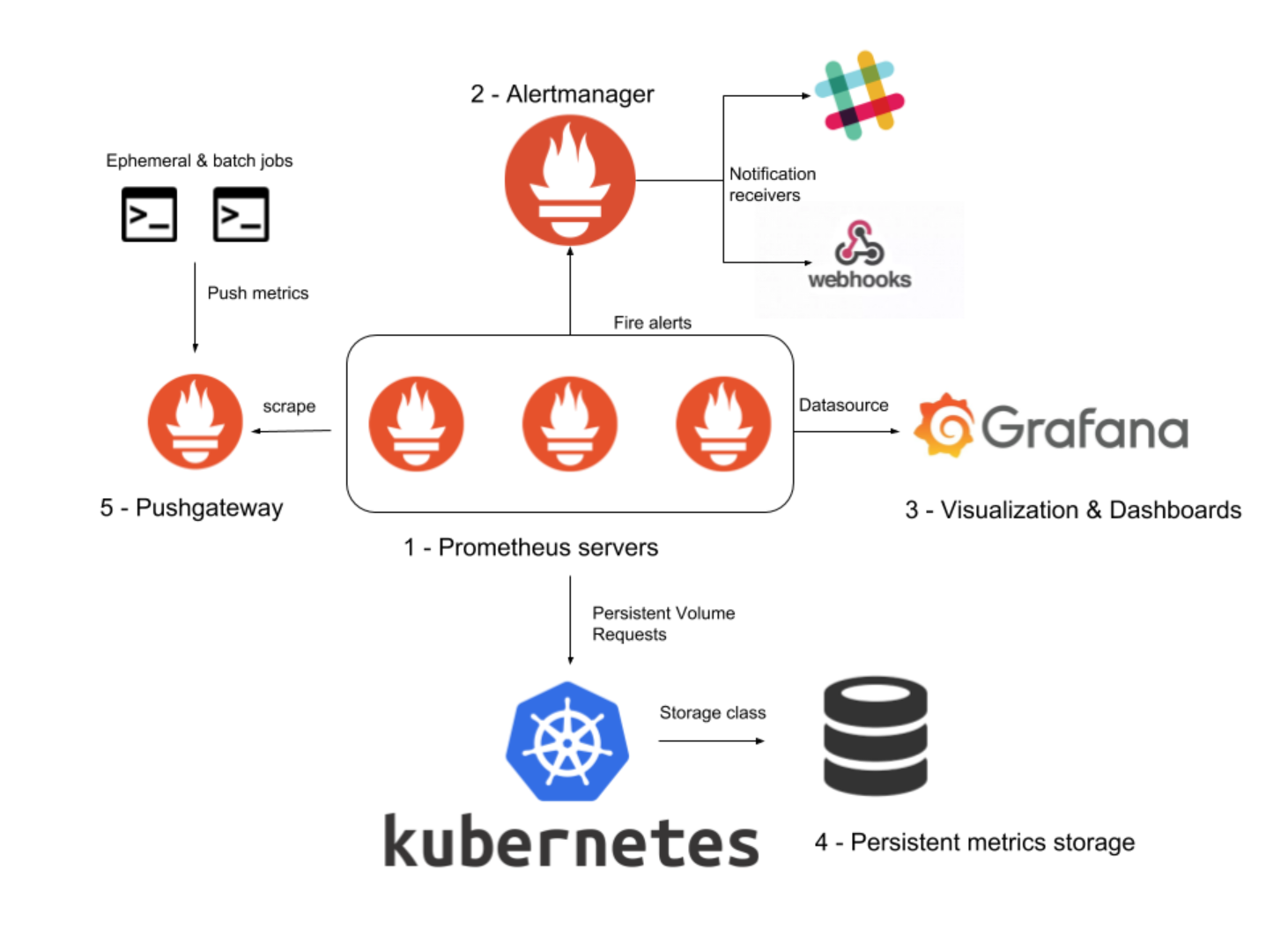
📌 목표
이번주는 Prometheus 구성, 메트릭 수집이후 Grafana 로 대시 보드 구성, 슬랙으로 얼럿 연동까지 해보자.
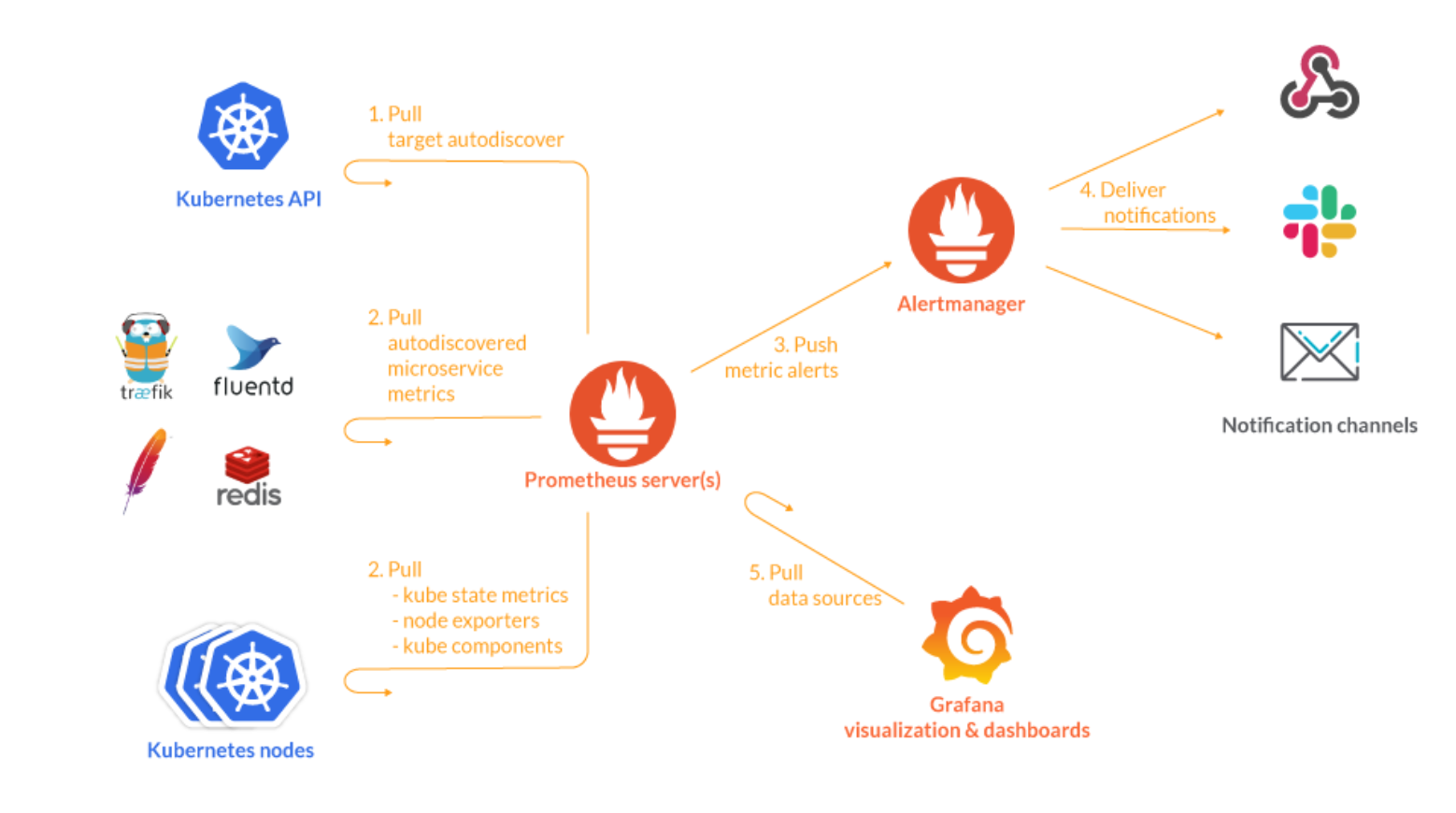
(이미지 출처: https://sysdig.com/blog/kubernetes-monitoring-prometheus/ )
실습환경
비교 : t3a.xlarge 4/16 $0.1872 , t3a.2xlarge 8/32 $0.3744 , *c5a.2xlarge 8/16 $0.344 , c5.2xlarge $0.384
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/kops-oneclick-f1.yaml
# CloudFormation 스택 배포 : 노드 인스턴스 타입 변경 - MasterNodeInstanceType=t3.medium WorkerNodeInstanceType=c5d.large
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl top node
(sparkandassociates:harbor) [root@kops-ec2 ~]# k get pod -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-5f65d889cd-4qpzv 1/1 Running 0 6d2h
metrics-server-5f65d889cd-v6clk 1/1 Running 0 6d2h
Prometheus 구성
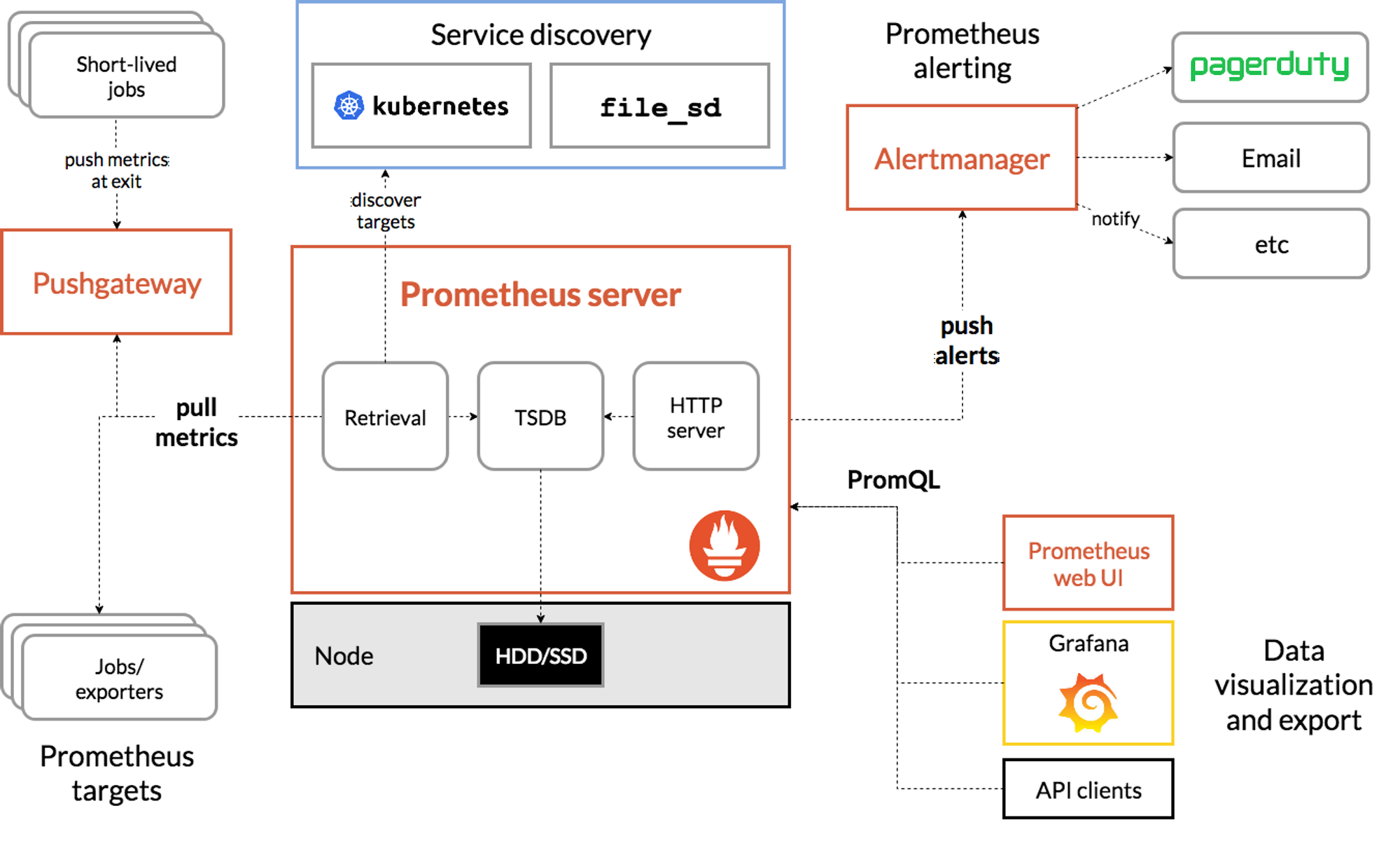
(이미지 출처:https://prometheus.io/docs/introduction/overview/)
프로메테우스 스택 설치
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get crd | grep monitoring선언한 alb 주소로 접속
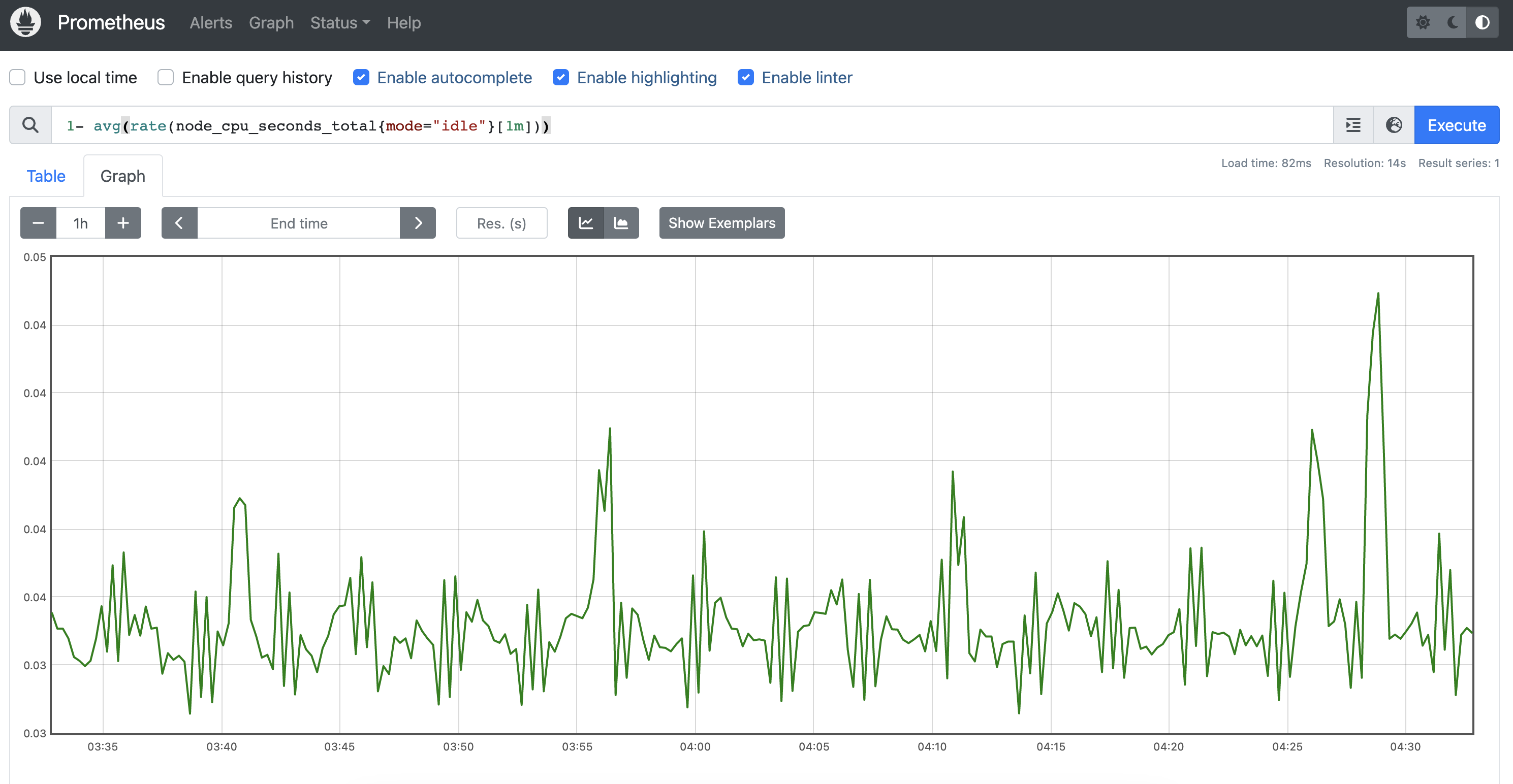
수집 잘 됨.
Grafana 구성 및 연동
Grafana는 시각화 도구.
실 데이터는 데이터 소스로서 prometheus, influxdb, mariadb등 다양한 소스를 활용할 수 있음.
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"접속 정보 확인 및 로그인 : 기본 계정 - admin / prom-operator
Configuration → Data sources : 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠 ← 서비스 주소 확인
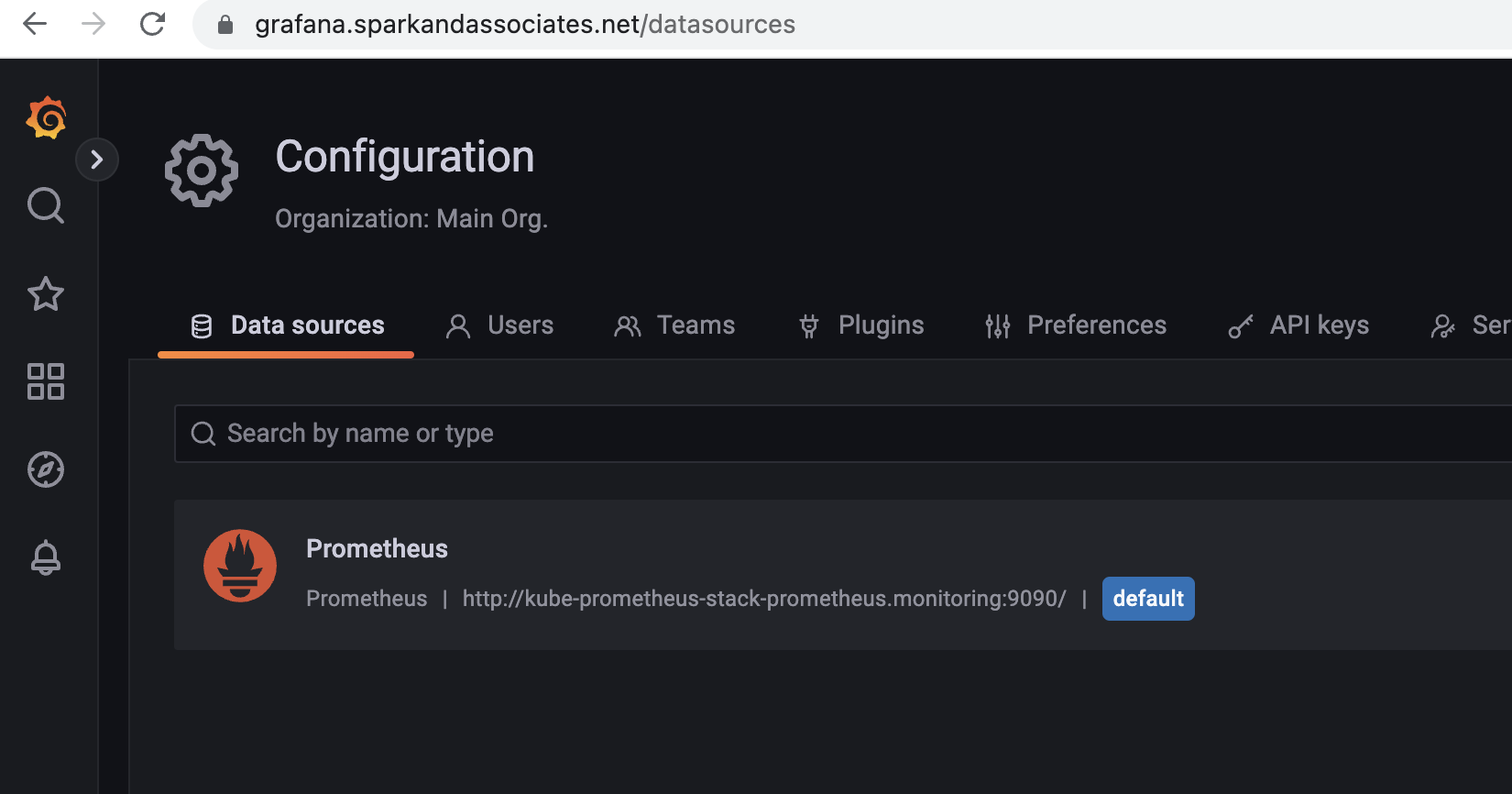
데이터 소스 접속확인.
# 테스트용 파드 배포
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
kubectl get pod
# 접속 확인
kubectl exec -it pod-1 -- nslookup kube-prometheus-stack-prometheus.monitoring
kubectl exec -it pod-1 -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v
# 삭제
kubectl delete -f ~/pkos/2/netshoot-2pods.yaml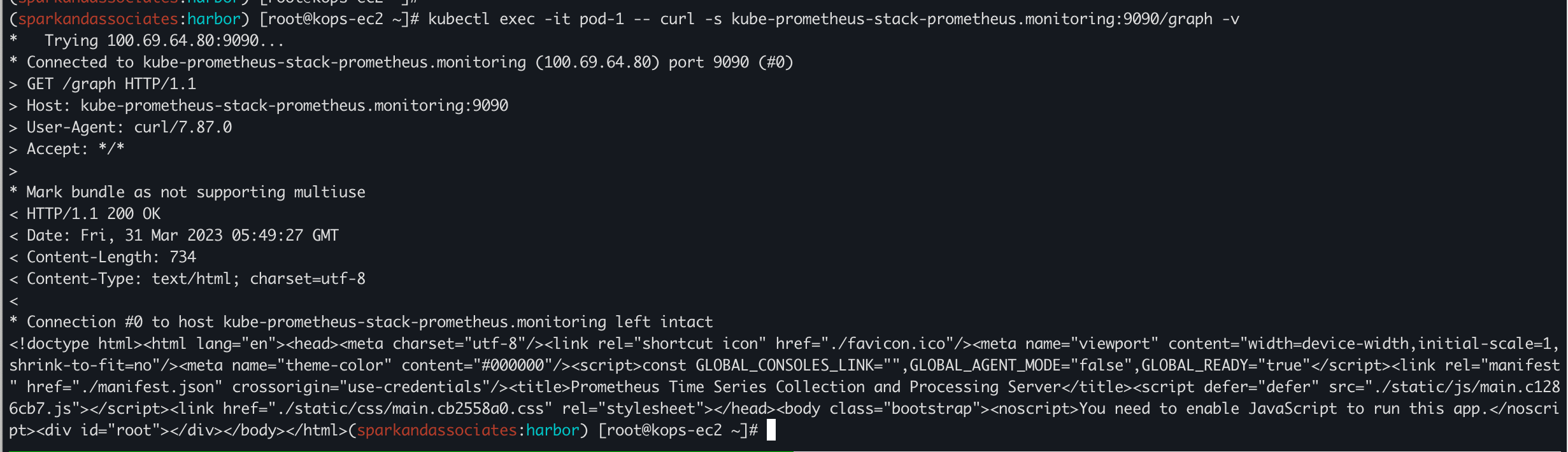
grafana 대시보드 구성
그라파나 홈페이지에서 공개된 대시보드를 이용해보자.
두가지 방법으로 가능.
1. json 다운로드 후 import
"1 Kubernetes All-in-one Cluster Monitoring KR"
https://grafana.com/grafana/dashboards/13770-1-kubernetes-all-in-one-cluster-monitoring-kr/
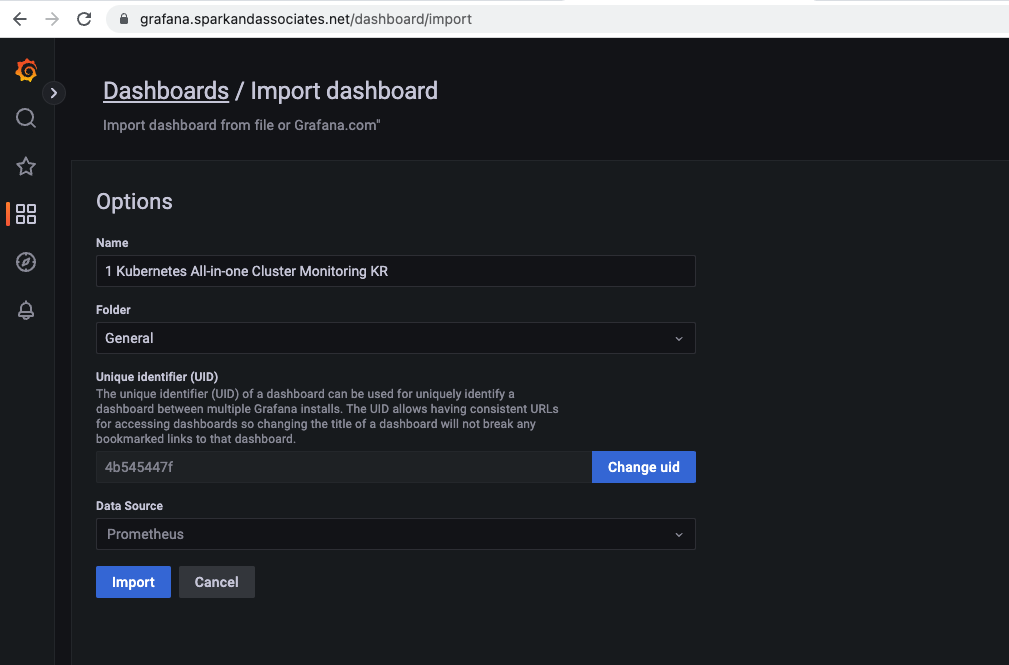
- import via grafana.com 에 ID 입력 import 가능 (ID : 13770 )
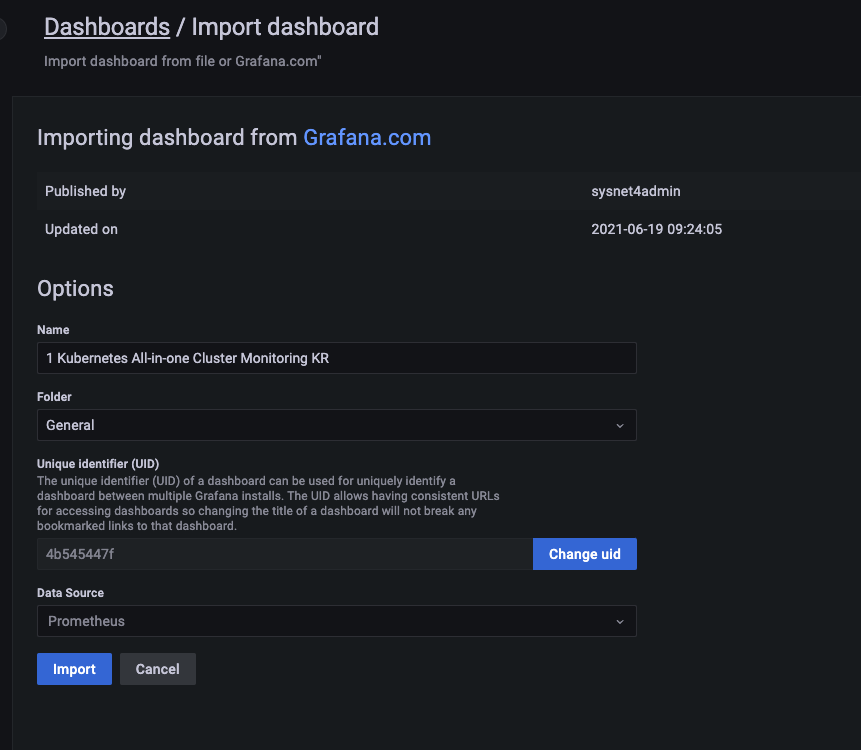
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → Import → 13770 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Kubernetes / Views / Global] Dashboard → Import → 15757 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- kube-state-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-state-metrics-v2] Dashboard → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Node Exporter Full] Dashboard → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
kwatch
kwatch helps you monitor all changes in your Kubernetes(K8s) cluster, detects crashes in your running apps in realtime, and publishes notifications to your channels (Slack, Discord, etc.) instantly
(https://artifacthub.io/packages/helm/kwatch/kwatch)
k8s 모니터링, 이벤트 등을 슬랙 채널에 webhook 으로 연동해보자.
(slack webhook 주소는 가림.)
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/T03G2,,,909iMIrewV'
#title:
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yaml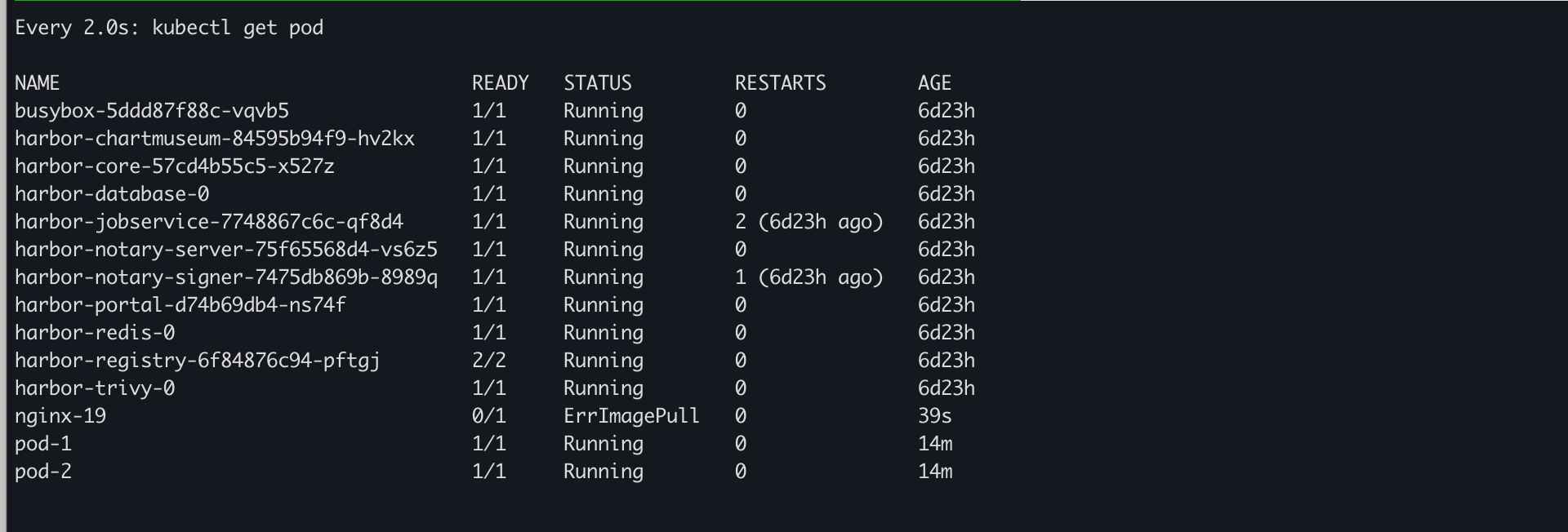
잘못된 이미지의 pod 이 배포되고, 연동한 webhook 채널에 알림이 갔다.
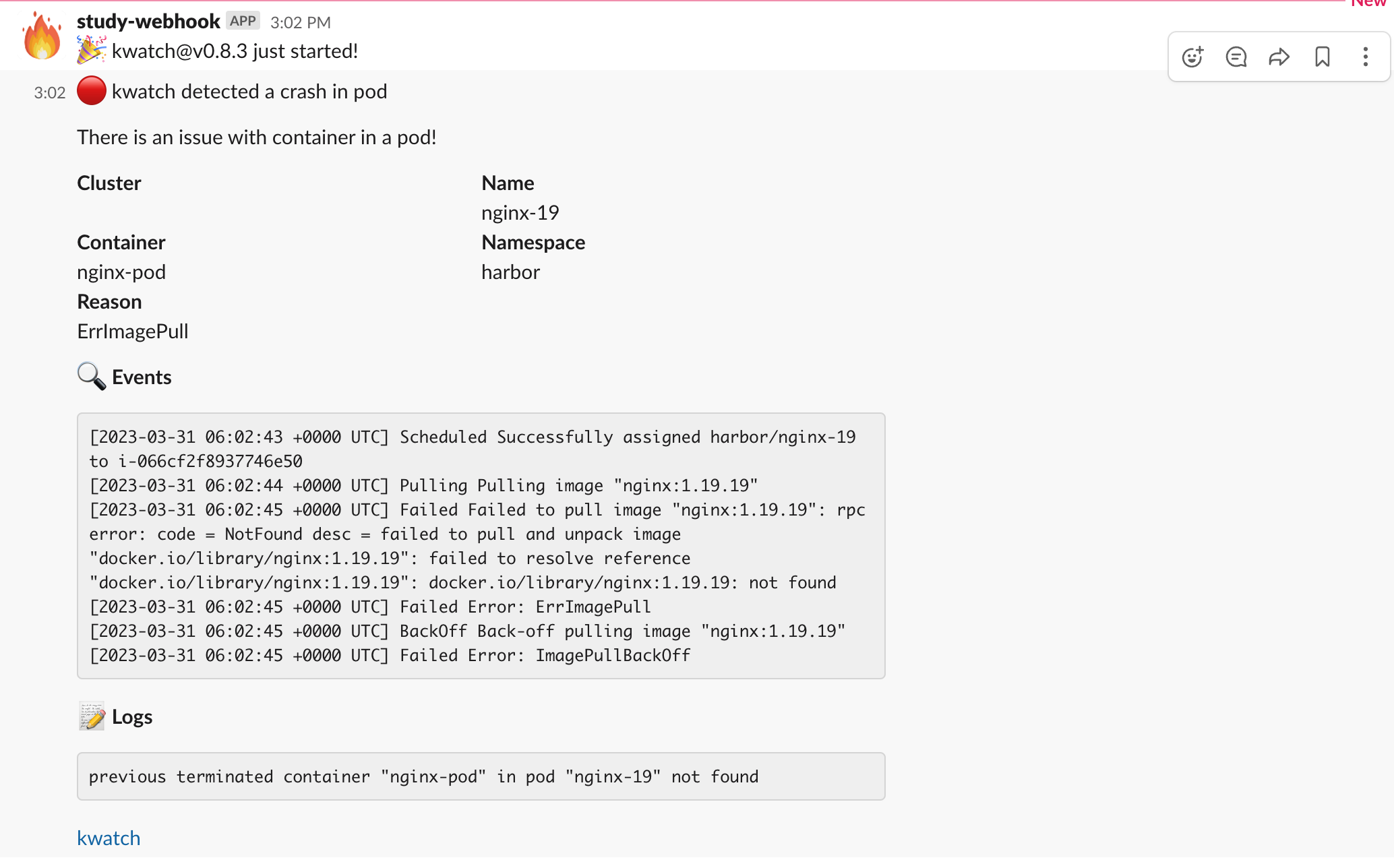
Alerting
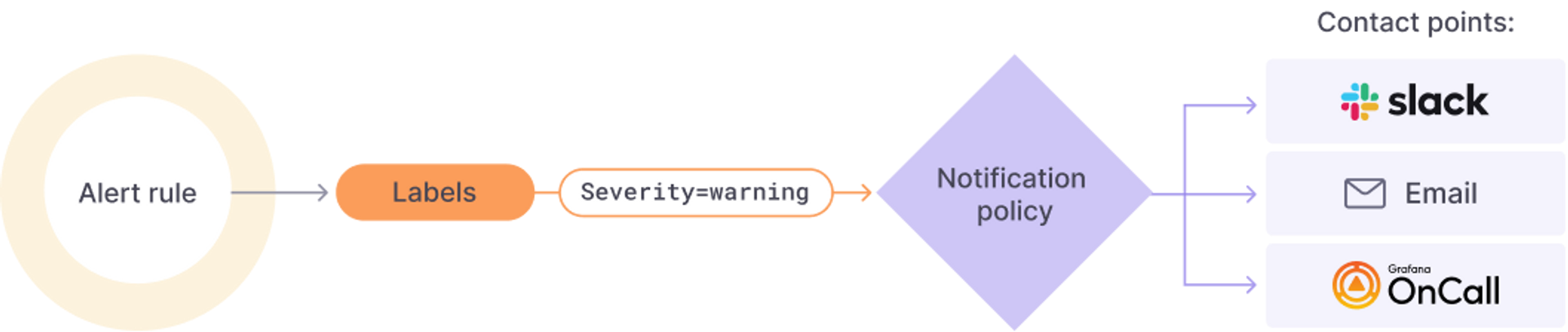
grafana dashboard 에 있는 alert 기능을 사용해보자.
테스트용 파드 생성
# 테스트용 파드 배포
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
kubectl get podalert contact point 설정
email, slack 등 연락처 관리를 할 수 있다.
pkos 로 앞서 사용한 slack webhook 을 연동해보자.
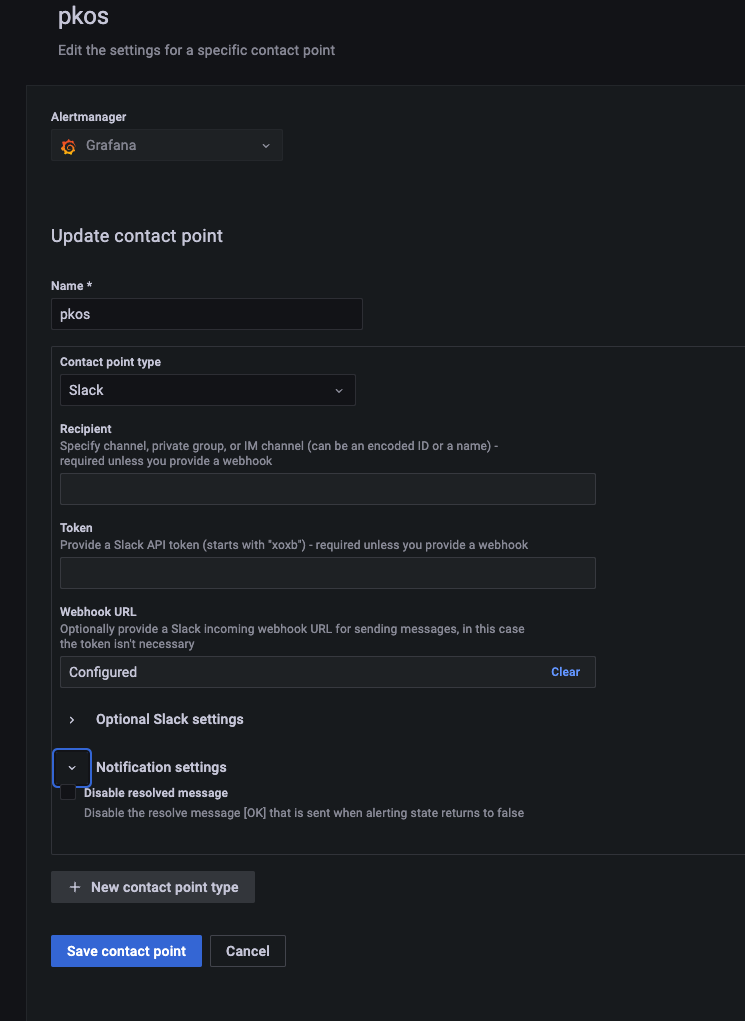
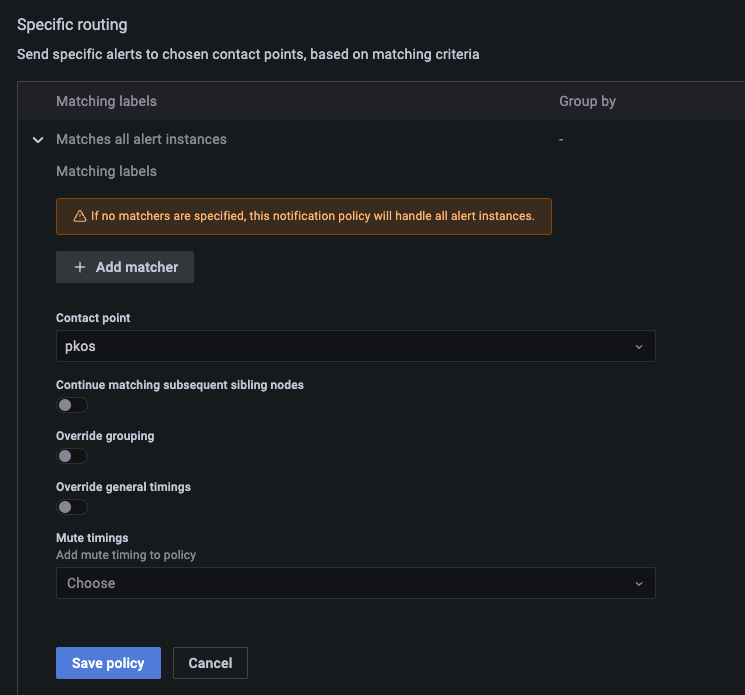
Notification policy 설정
알림 정책을 만들어야한다.
label을 만들어 지정한 label에 해당하는 얼럿들을 별도 지정한 연락처 그룹으로 전송한다.
예를들어 부서, 조직 또는 서비스 별로 label을 만들어
담당자, 그룹에 일괄 전송 가능하다.
본 테스트에서는 label 지정을 하지 않고 모든 얼럿을 기본 설정한 연락처로 전송하도록 한다.
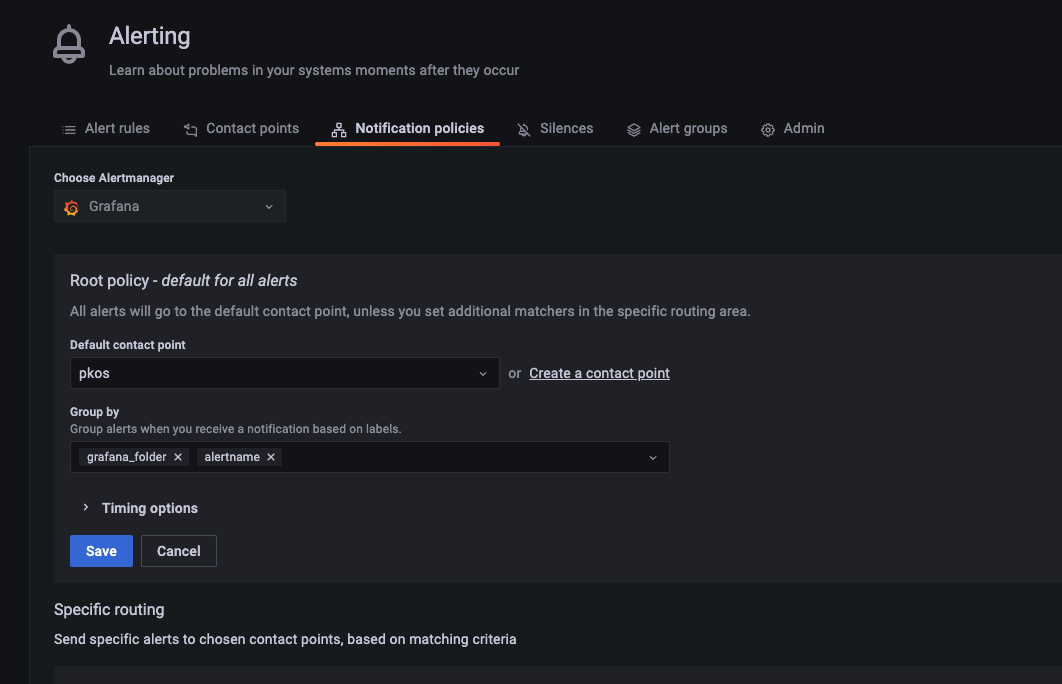
alert 트리거 설정
테스트 pod-1 의 network receive bandwidth에 트리거 설정을 해보자.
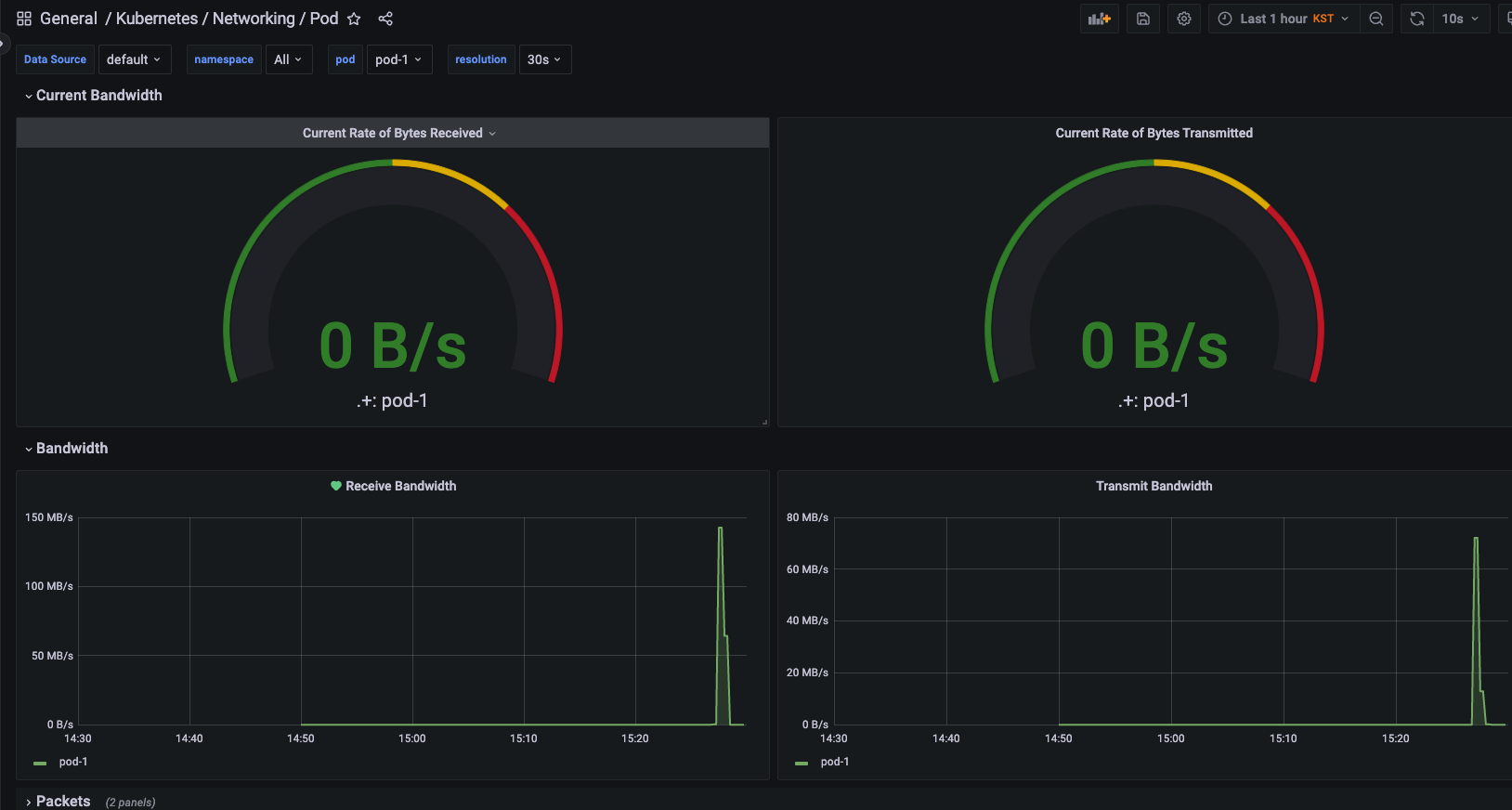
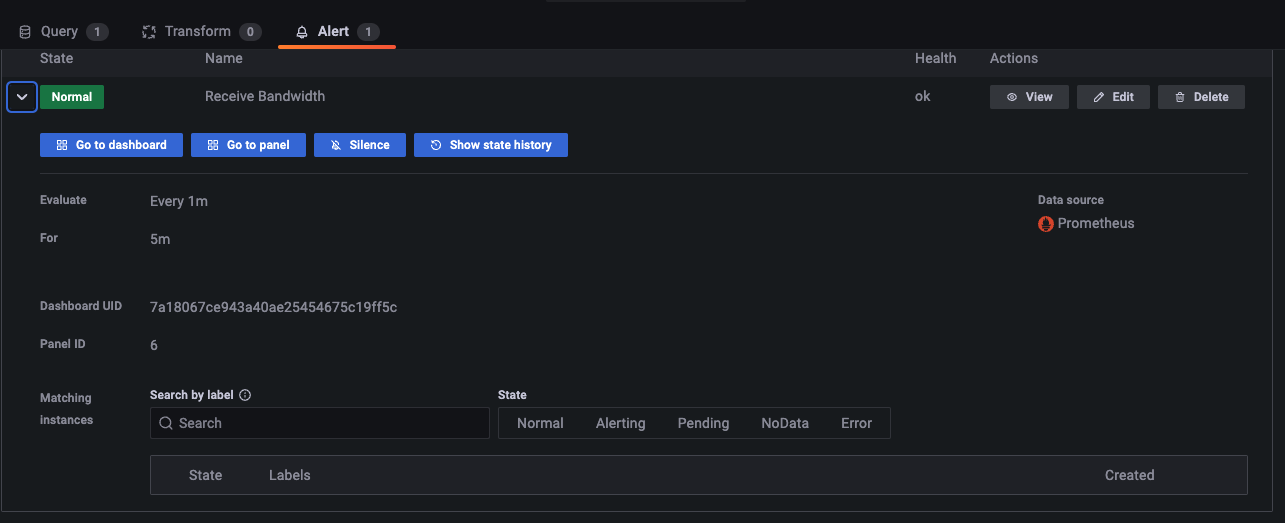
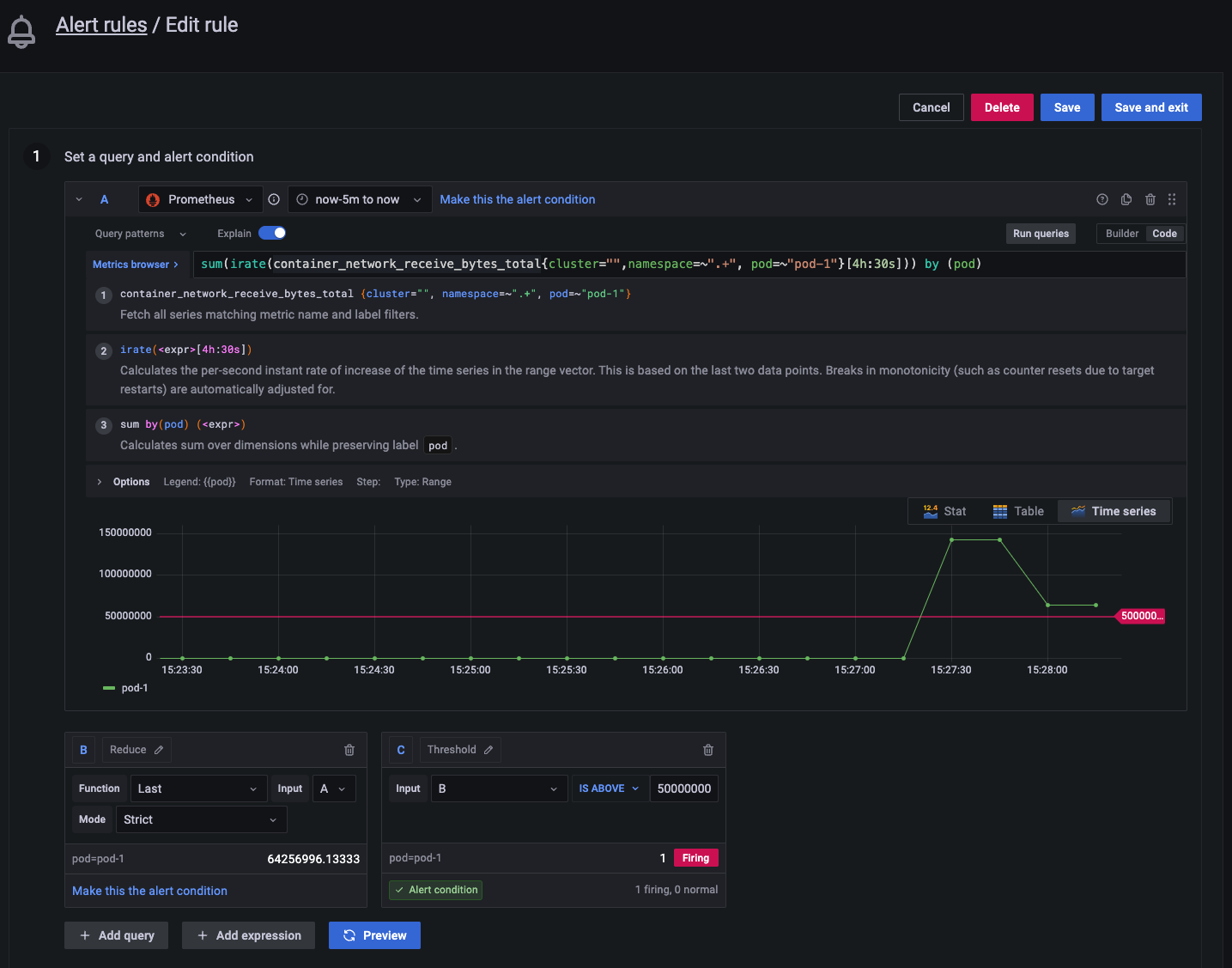
얼럿 테스트 (이벤트 발생)
테스트 pod-1을 iperf를 이용해 server로 띄우고
pod-2을 client로 pod-1 쪽으로 패킷을 던져보자.
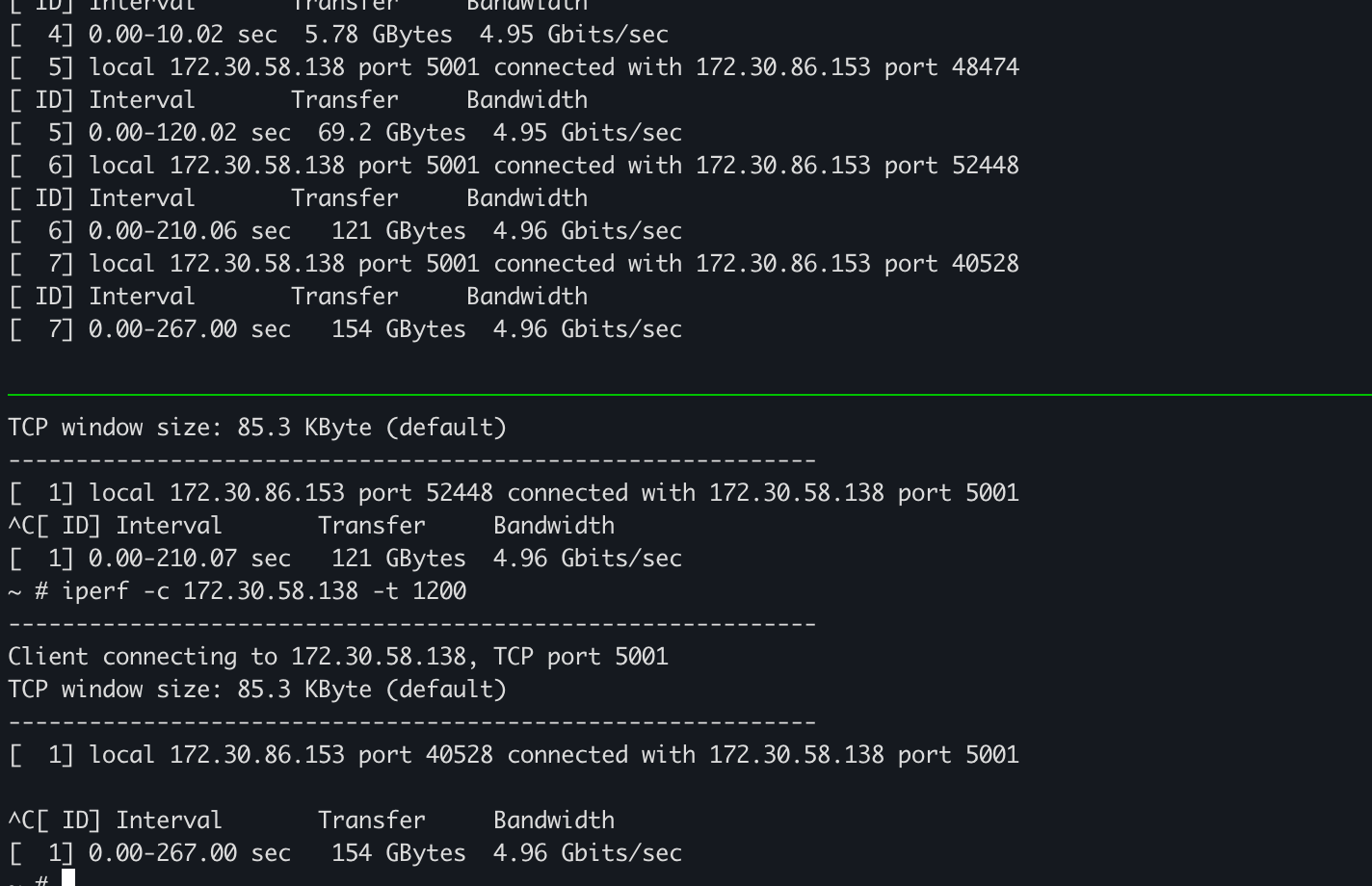
트래픽이 설정한 임계치를 초과하면 얼럿이 발생하며
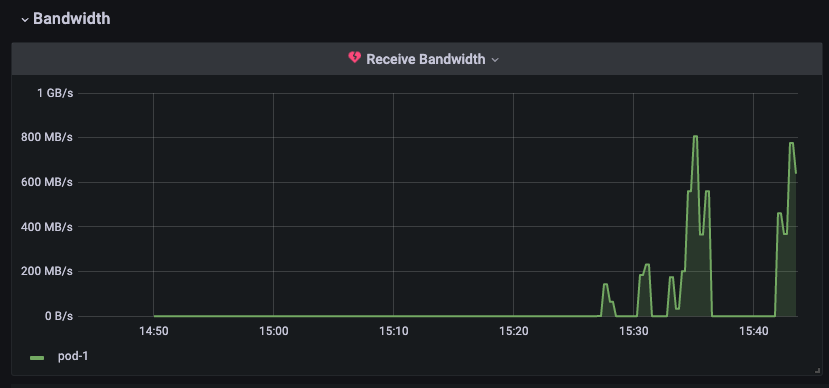
패널 이름 옆에 하트 아이콘이 초록색에서 주황색 -> 빨간색 깨진 하트 모양으로 변경된다.
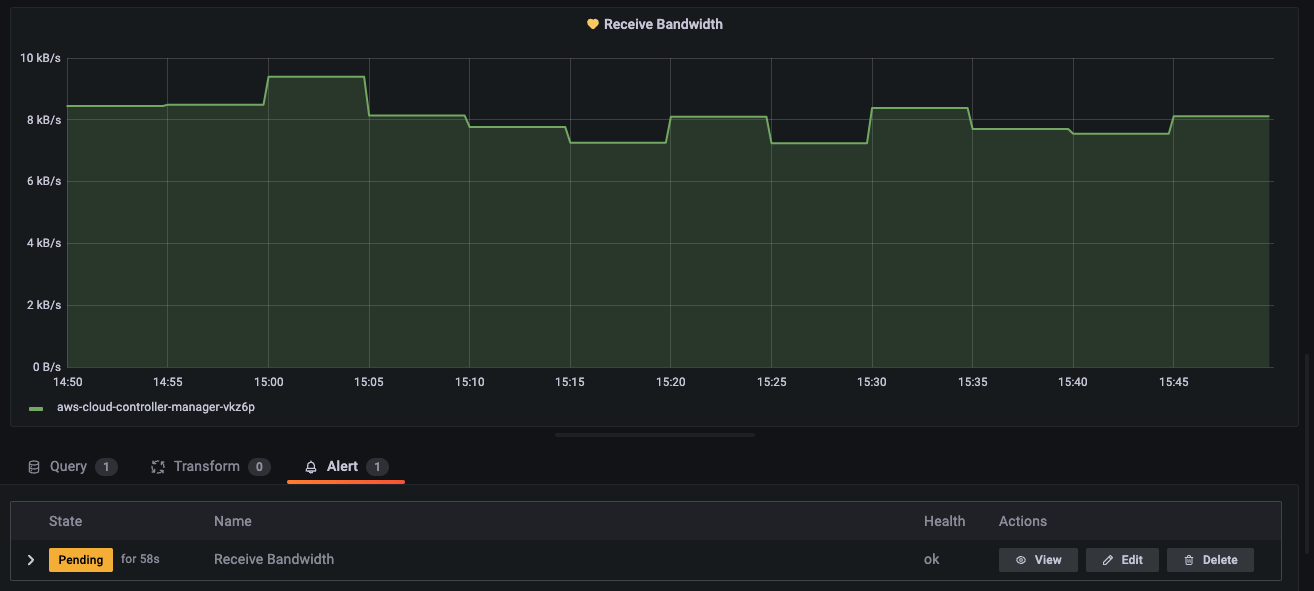
설정한 시간 *1분 까지 pending으로 기다린 이후 얼럿을 Firing 시킨다.
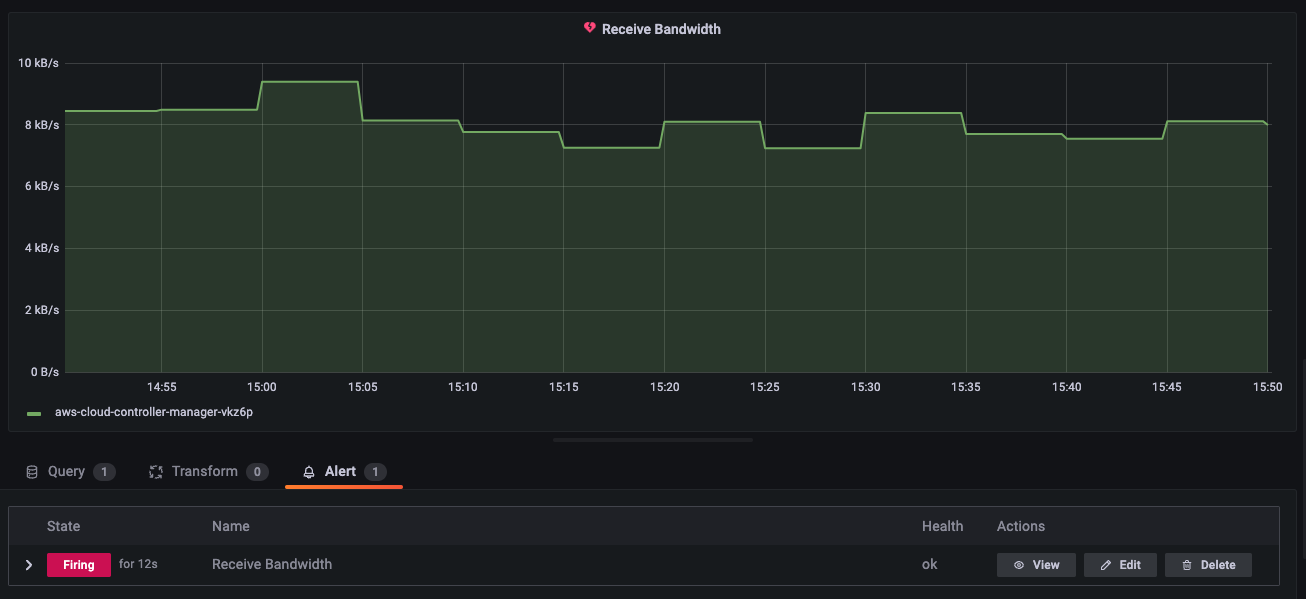
알림 확인
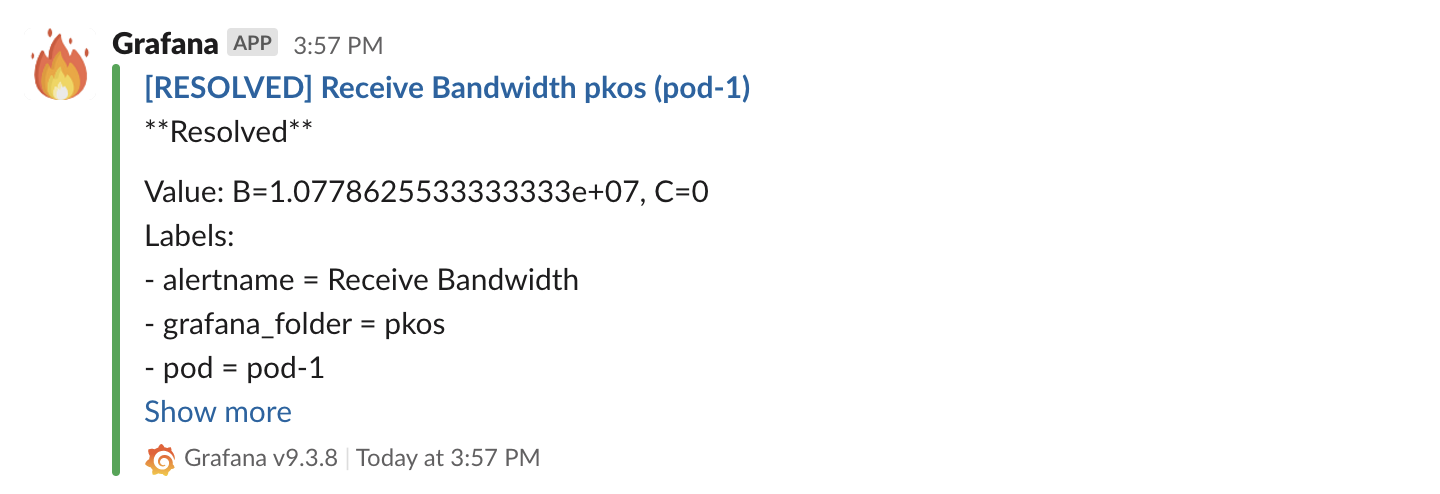
slack 채널로 아래와 같이 이벤트 알림이 온다.
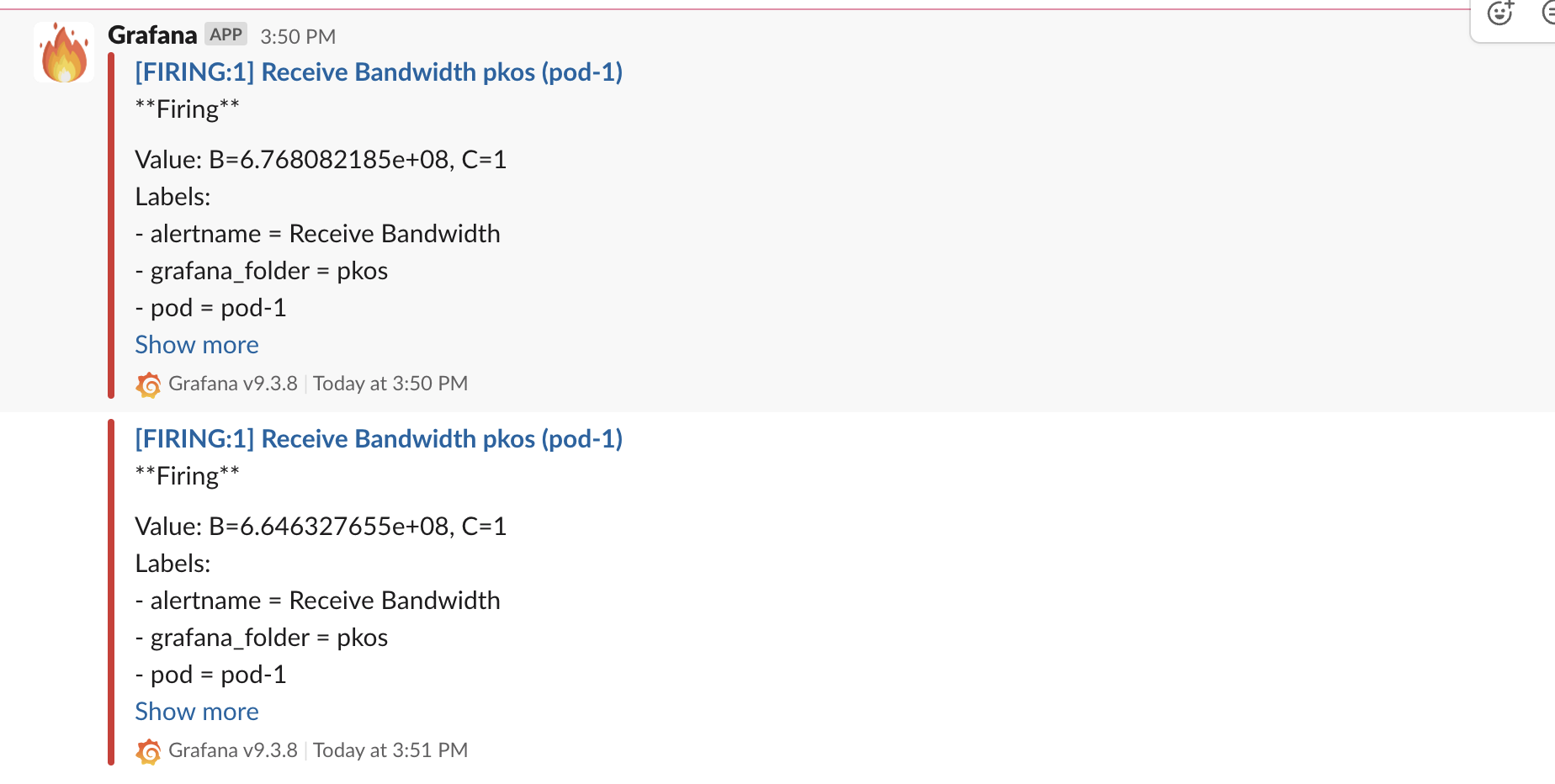
다시 정상범위로 돌아오면 "Resolved" 메세지를 받을 수 있다.