데이터 분석 도구의 중요성: 데이터를 다양한 방법으로 분석하기 위해 적절한 도구 사용이 필수적이다.
pandas의 중요성: pandas는 표 형태의 데이터를 DataFrame 형식으로 불러와 자유롭게 분석하고 가공할 수 있는 강력한 도구이다.
loan_df라는 DataFrame의 통계 정보를 확인하고 싶을 땐 loan_df.describe(), DataFrame의 크기를 확인하고 싶을 땐 loan_df.shape
그런데 여기서 주의할 점은 describe() 뒤에는 괄호가 붙어 있는데 shape 뒤에는 괄호가 붙어 있지 않다. 설명하자면 뒤에 괄호가 붙는 건 DataFrame에 동작하는 일종의 '함수'고, 뒤에 괄호가 안 붙는 건 DataFrame의 정보를 담고 있는 일종의 '변수'.예를 들어 loan_df.describe()는 통계값을 계산하는 describe()라는 함수를 loan_df라는 DataFrame에 적용하는 코드라고 볼 수 있습니다. loan.shape는 DataFrame의 크기 정보가 저장되어 있는 변수를 가져오는 코드.
import pandas as pd
loan_df = pd.read_csv('data/loan.csv')
#dataFrame의 데이터 중 인덱스 0~4까지 5개
loan_df.head()
#dataFrame의 데이터 중 뒤에서 5개
loan_df.tail()
#데이터 크기 - 로우의 개수와 컬럼의 개수
loan_df.shape
(600,7) 600 row, 7개의 컬럼
#데이터 정보-각 컬럼의 데이터 타입과 결측치가 아닌 값의 개수를 확인
loan.info()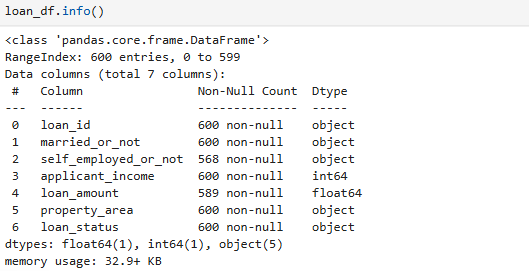
- 데이터 요약 -DataFrame의 평균, 중간값, 최소값, 최대값, 표준편차 등의 통계 정보를 요약
loan_df.describe()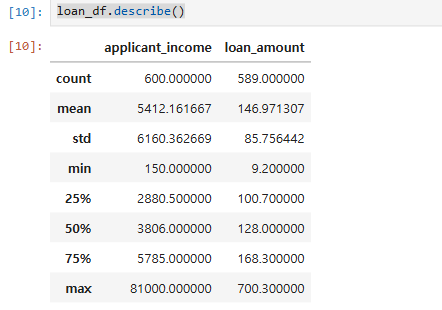
- 정렬 - 기본적으로 오름차순 정렬. loan_amount기준으로 오름차순 정렬을 하겠다는 의미
loan_df.sort_values(by='loan_amount')- 내림차순
loan_df.sort_values(by='loan_amount', ascending=False)인덱스, 컬럼명, 데이터 타입 설정
- 엑셀파일 읽기
엑셀 파일을 불러올 때는 read_excel()이라는 함수를 사용.loan_df = pd.read_excel('data/loan.xlsx')
- 사용할 시트의 이름도 지정
read_excel()은 기본적으로 첫 번째 시트에 있는 데이터를 가져옴. 그래서 위에서 불러온 loan_df를 출력해 보면 아무것도 안나옴. 원하는 시트에 있는 데이터를 가져오려면, 아래 코드와 같이 sheet_name이라는 파라미터를 사용. 여기에 'Sheet2'라고 직접 시트의 이름을 넣어 줘도 되고, 두 번째 시트를 가져온다는 뜻으로 1이라는 숫자 값을 넣어 줘도 됩. 두 번째 시트인데 2가 아니라 1을 넣는 이유는 index가 0부터 시작.
loan_df = pd.read_excel('data/loan.xlsx', sheet_name=1)
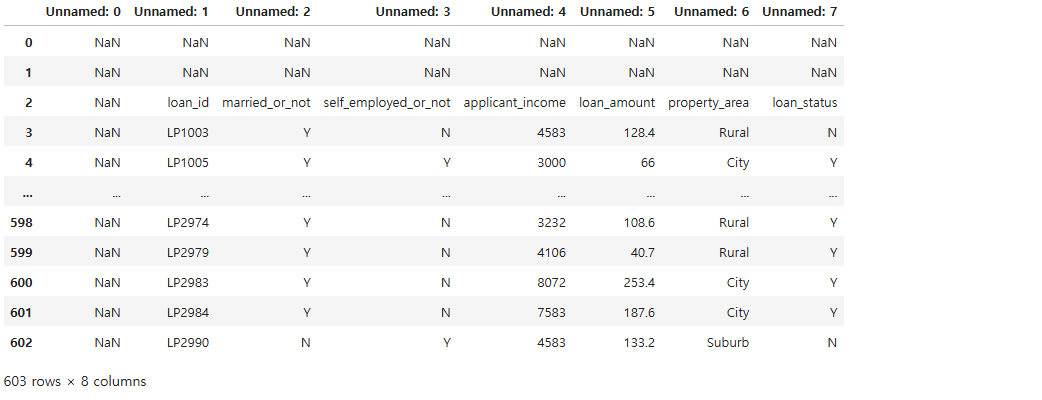
read_excel()은 기본적으로 A1 셀부터 데이터를 가져오고, 이때 비어 있는 셀들은 결측값으로 간주함. 그래서 위 코드에서 다시 불러온 loan_df를 출력해 보면 아래와 같이 컬럼명이 Unnamed: 0, Unnamed: 1, Unnamed: 2 이런 식으로 되어 있고, 첫 번째 컬럼과 첫 번째, 두 번째 로우가 모두 결측값(NaN).
여기서 header라는 파라미터를 사용하면 데이터를 몇 번째 줄부터 불러올지 설정할 수 있음. 지금 엑셀 파일은 네 번째 줄에 헤더가 있으니까, header 값으로 3을 넣어 주면 됩. 그러면 네 번째 줄에 있는 값을 컬럼으로 간주하고, 그 줄부터 데이터를 읽어옴.
usecols라는 파라미터를 사용해서, 데이터가 몇 번째 열부터 시작하는지 설정.
데이터가 B열부터 H열까지 있다면 B열부터 H열에 있는 데이터를 가져오려면 아래와 같이 usecols에 'B:H'라는 값을 넘겨주면 됩.loan_df = pd.read_excel('data/loan.xlsx', sheet_name=1, header=3, usecols='B:H')
