iloc[] : 위치를 기준으로 인덱싱
loc[] : 이름을 기준으로 인덱싱
boolean indexing : 조건을 만족하는 데이터 추출
- 논리 연산자
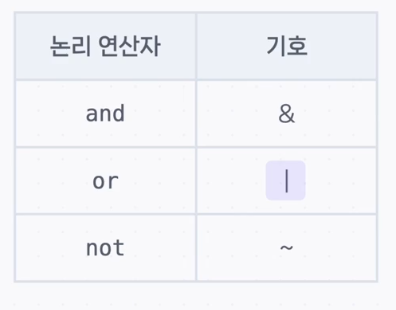
.median()(중앙값)
- multi boolean indexing
condition1 = loan_df['married'] == 'Y' // 조건1
loan_df['income'].mean() // 평균
condition2 = loan_df['income'] > loan_df['income'].mean() //조건2
loan_df[condition1 & condition2]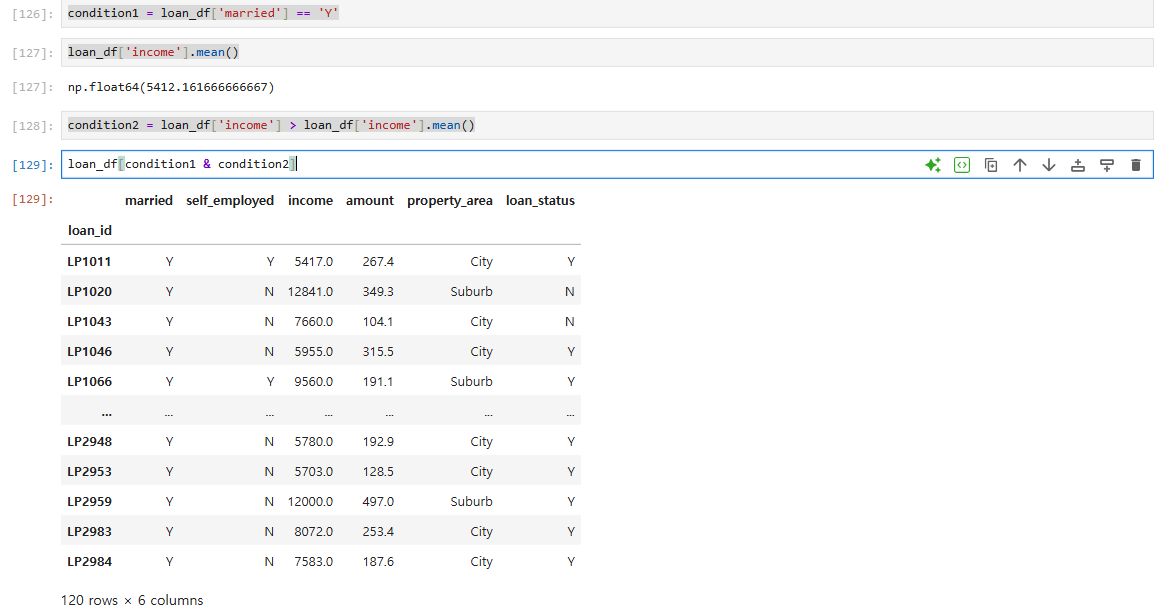
loan_df[condition1 | condition2]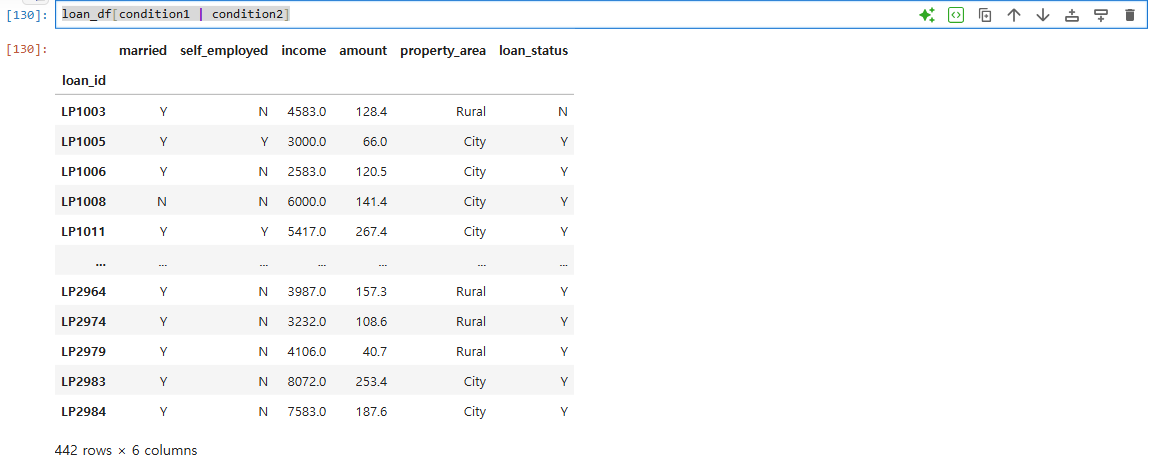
-
조건식을 변수가 아닌 직접입력
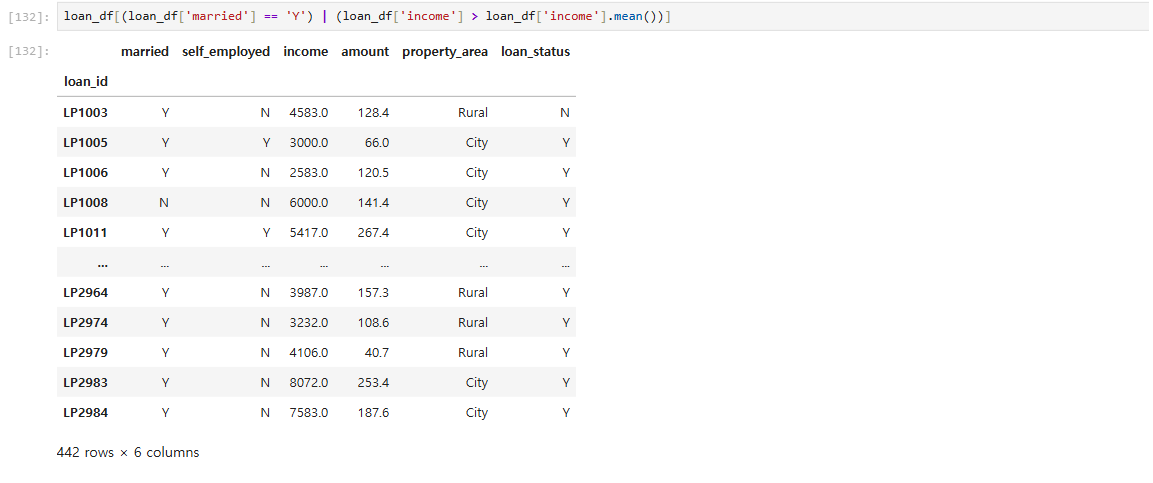
-
논리연산자 우선순위 : not > and > or
condition3 = loan_df['property_area'] == 'City'
loan_df[condition1 | condition2 & ~condition3] 혹은 loan_df[condition1 | (condition2 & ~condition3)]처리순서는 위와 같음
import pandas as pd
loan_df = pd.read_csv('data/loan.csv')
loan_df = loan_df.set_index('loan_id')
new_columns = {'married_or_not': 'married',
'self_employed_or_not': 'self_employed',
'applicant_income': 'income',
'loan_amount': 'amount'}
loan_df = loan_df.rename(columns=new_columns)
condition1 = loan_df['loan_status'] == 'Y'
condition2 = loan_df['self_employed'] == 'N'
condition3 = loan_df['income'] >= loan_df['income'].median()
group1 = loan_df[condition1 & condition2 & condition3]
group1
개발자