시리즈(Series): 1차원 데이터 구조로, 인덱스를 가지는 단일 열입니다. 한 종류의 데이터(예: 숫자, 문자열 등) 목록을 저장하고자 할 때 사용됩니다.
데이터프레임(DataFrame): 2차원 데이터 구조로, 여러 개의 시리즈(열)로 구성됩니다. 데이터프레임의 특정 열을 선택하면 시리즈가 반환됩니다.
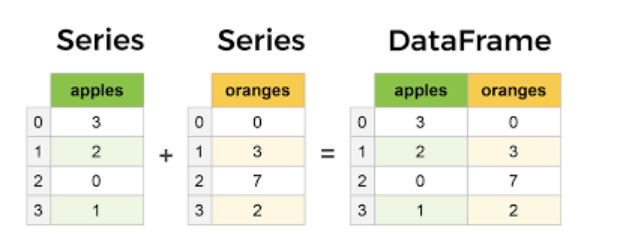
여러 개의 시리즈(Series)를 합쳐서 하나의 데이터프레임(DataFrame)을 만들 수 있습니다. 각각의 시리즈는 데이터프레임의 열이 됩니다.
Series: 각각의 시리즈는 하나의 열을 나타냅니다.
첫 번째 시리즈는 'apples' 열을 나타내며, 인덱스와 값이 있습니다.
두 번째 시리즈는 'oranges' 열을 나타내며, 인덱스와 값이 있습니다.
DataFrame: 두 개의 시리즈가 결합되어 하나의 데이터프레임을 형성합니다.
데이터프레임은 두 개의 열('apples'와 'oranges')과 여러 개의 행으로 구성됩니다.
- 한 컬럼의 데이터 타입
loan_df['self_employed'].dtype
- 컬럼별
loan_df['self_employed'].describe()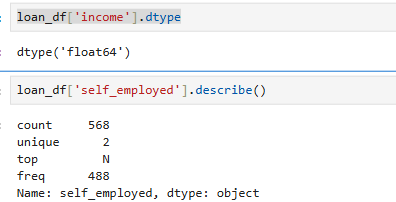
- object 타입에 쓰기 좋은 함수
loan_df['self_employed'].unique() # 값의 종류
loan_df['self_employed'].value_counts() # 값별 갯수
loan_df['self_employed'].value_counts(dropna=False) # 값별 갯수. nan 포함
loan_df['self_employed'].value_counts(dropna=False , normalize=True) # 값 별로 전체에서 차지하는 비중
- 인덱스 포함 원하는 컬럼만 출력
loan_df[['amount','income']]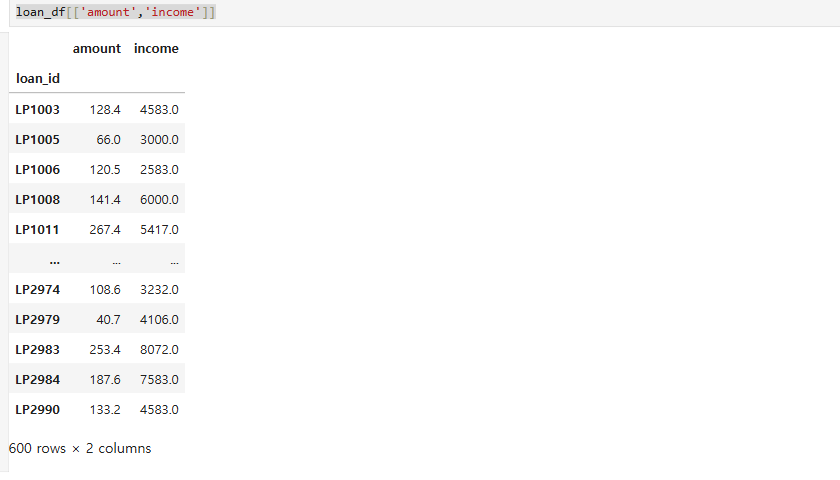
- 참조 - dataframe과 series의 차이
loan_df[['amount']] # dataframe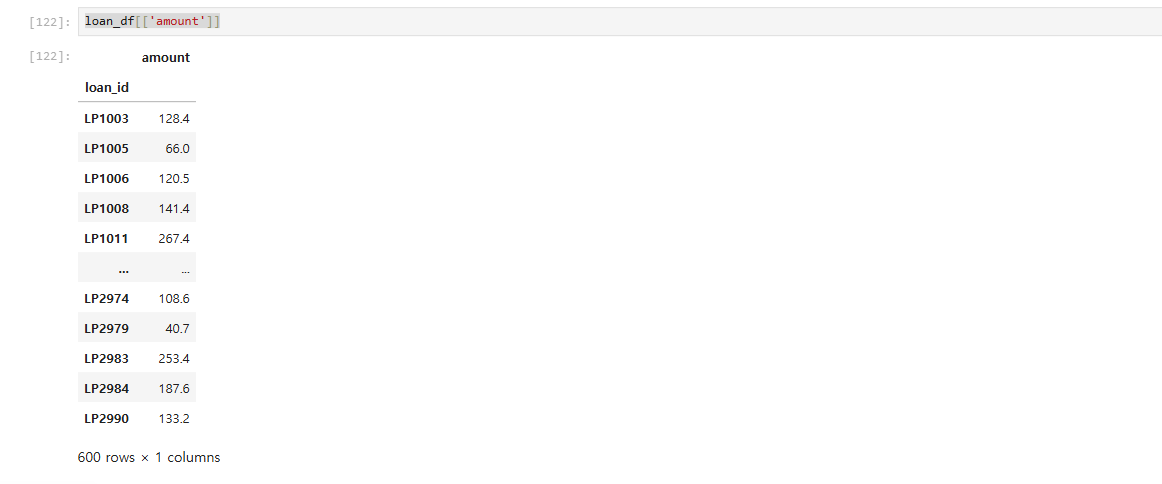
loan_df['amount'] # series
한개짜리 인 경우 series인지 dataFrame인지 잘 구분해야 함.

개발자