해당 게시물은 learn_opencv사이트의 게시물을 번역하여 정리하였다.
이전 게시물에서 Pytorch의 장점과 배워야 하는 이유를 기재하였다.또한 Pytorch에서 사용되는 핵심 데이터 구조인 Tensor에 대해서 간단하게 살펴보았다.본 게시물에선 image classification을 위해 Torchvision 모듈에 있는 pre-trained 네트워크를 사용하는 실습을 진행한다.
Torchvision 패키지는 많이 사용되는 dataset, model architecture 및 CV를 위한 일반적인 이미지 변환으로 구성된다.
기본적으로 CV에 관심이 있고 Pytorch를 사용하고 있다면 Torchvision이 많은 도움이 될 것이다.
Image classification을 위한 Pre-trained 모델
Pre-trained 모델은 ImageNet과 같은 대규모 벤치마크 dataset에서 train된 신경망 모델이다.딥러닝 커뮤니티는 이러한 open source 모델의 혜택을 많이 받았고 사전 훈련된 모델은 CV연구의 급속한 발전을 위한 주요 요인이다.다른 연구원과 실무자는 처음부터 모든걸 다시 만드는 대신 이런 최신 모델을 사용할수 있다. 아래의 사진은 모델이 시간 순으로 어떻게 개선되었는지에 대한 지표이다.Torchvision패키지에 있는 모델만 포함하였다.
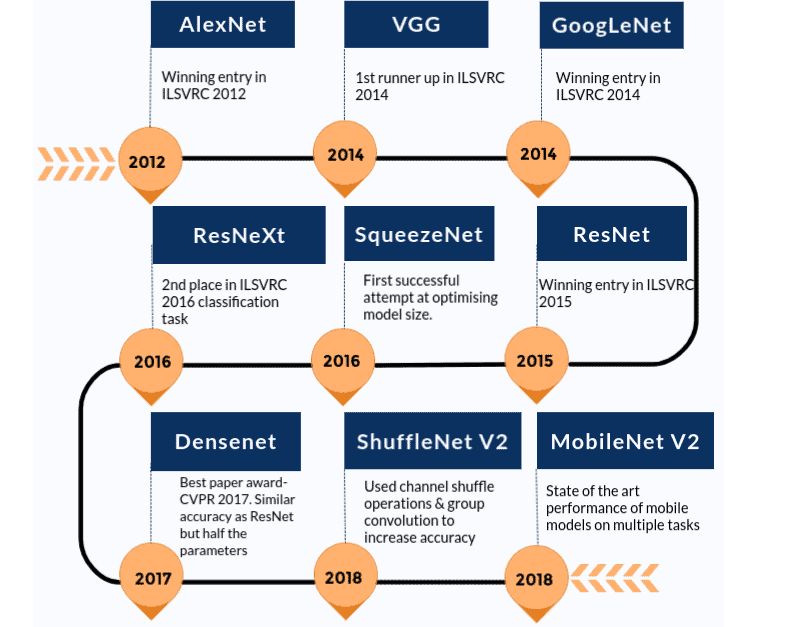
Image classification을 위해 Pre-trained모델을 사용하는 방법에 대해 자세히 알아보기 전에 사용가능한 다양한pre-trained 모델을 알아본다.본 게시물에서는 AlexNet과 ResNet101을 두가지 주요 예로 논의 할 것이다.두 네트워크 모두 ImageNet Dataset에 대해 학습되었다.
ImageNet데이터세트에는 Stanford University에서 유지관리하는 1400만개 이상의 이미지가 있다.다양한 이미지 관련 딥러닝 프로젝트에 광범위하게 사용된다.
이미지는 다양한 class또는 lable에 속한다.두 용어를 같은 의미로 사용할 수 있지만 class로 사용하겠다.AlexNet 및 ResNet101과 같은 pre-trained 모델의 목표는 image를 입력값으로 가져와 class를 예측하는 것이다.
여기서 pre-trained 라는 단어는 예를 들자면 딥러닝 아키텍처 AlexNet 및 ResNet101이 일부(거대한)dataset에 대해 이미 train되었으므로 결과적인 가중치(weight)와 bias를 전달하는 의미이다.아키텍쳐와 weight,bias간의 이러한 차이는 다음 섹션에서 볼 수 있듯이 TorchVision에 아키텍처와 사전 훈련된 모델이 모두 있기 때문에 매우 명확해야 한다.
모델 추론 프로세스
Input class를 예측하기 위해 pre-trained 모델을 사용하는 방법에 중점을 둘 것이므로 이와 관련된 프로세스도 논의해본다.
모델 추론 프로세스는 다음과 같은 단계로 진행된다
- input image읽기
- image 변형 ex.크기 조정,crop,nrmalization 등
- Forward Pass:pre-trained된 가중치를 사용해 출력 벡터를 찾는다. 이 출력 벡터의 각 요소는 모델이 특정 class에 속하는 입력 값을 예측하는 confidence(정확도/신뢰도)를 나타낸다.
Torchvision을 사용하여 Pre-trained 네트워크 로드
torchvision 모듈에서 모델을 가져와 사용가능하 다양한 모델과 아키텍쳐를 보여준다.
AlexNet이라는 항목과 alexnet이라는 항목이 있다.
대문자로 되어있는 이름은 Python class(AlexNet)를 참조하는 반면 alexnet은 AlexNet class에서 인스턴스화된 모델을 반환하는 편의함수이다.이러한 편의 기능이 서로 다른 매개변수 집합을 가질수 있다.예를 들어 Densenet121,Densenet161,Densenet169,Densenet201은 모두 DenseNet클래스의 인스턴스 이지만 layer수는 각각 121,161,169,201이다.
이미지 분류에 AlexNet사용
먼저 AlexNet부터 시작한다.초기 Image Recognition의 획기적인 네트워크 중 하나이다.AlexNet의 아키텍처에 대한 사전 내용은 AlexNet에 정리해 놓았다.
1.Pretrained model load
2. 이미지 변환
모델을 다운받았으면 다음단계는 입력 데이터가 적절한 shape와 평균 및 표준 편차와 같은 기타 특성을 갖도록 변환하는 것이다.
이 값은 모델을 treain하는 동안 사용된 값과 비슷해야 한다.이렇게 하면 네트워크가 의미있는 결과를 보여줄 것이다.
Torchvision 모듈에 있는 Transforms을 이용해 입력 데이터를 전처리 할수 있다.이경우 AlexNet과 ResNet 모두 사용 가능하다.
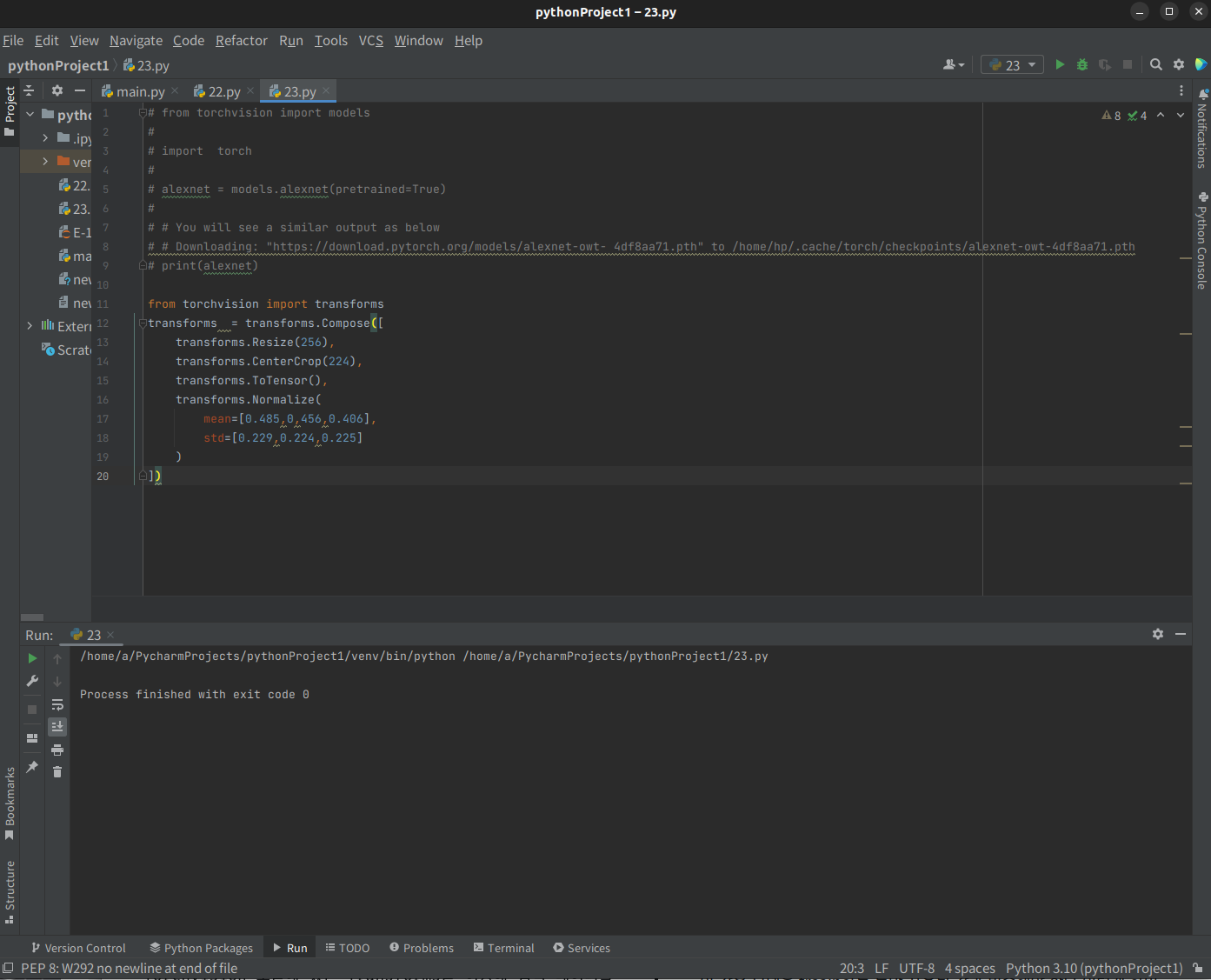
코드 분석을 해본다.
from torchvision import transforms
transform = transforms.Compose([ #[1]
transforms.Resize(256), #[2]
transforms.CenterCrop(224), #[3]
transforms.ToTensor(), #[4]
transforms.Normalize( #[5]
mean=[0.485, 0.456, 0.406], #[6]
std=[0.229, 0.224, 0.225] #[7]
)])Line [1] :입력 이미지에 대해 수행할 모든이미지 transform의 조합인 가변 변환 을 정의한다.
Line [2]: 이미지 크기를 256×256 픽셀로 조정한다.
Line [3] : 중심을 기준으로 이미지를 224×224 픽셀로 자른다.
Line [4] : 이미지를 PyTorch Tensor 데이터 유형으로 변환한다.
라인 [5-7]: 평균과 표준 편차를 지정된 값으로 설정하여 이미지를 정규화한다.
3.Input image load 및 전처리
입력 이미지를 load하고 위에서 지정한 이미지 변환을 진행한다.
TorchVision에서 지원하는 기본 이미지 백엔드로,Torchvision과 함께 Pillow모듈을 사용한다.

4. 모델 추론
마지막으로 pre_trained model을 사용하여 모델이 이미지가 무엇인지 확인할 차례이다.
먼저 모델을 평가(eval)모드로 전환후, 추론을 진행한다.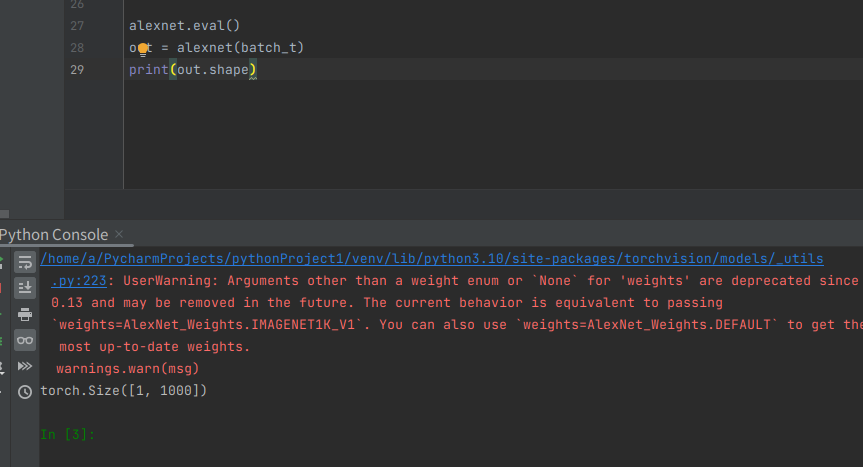
아직 image의 class(label)가 없다.따라서 1000개의 요소가 있는 이 출력 벡터의 모든 레이블 목록이 있는 txt파일에서 읽고 저장한다.줄 번호는 class번호를 지정하므로 순서를 변경하면 안된다.
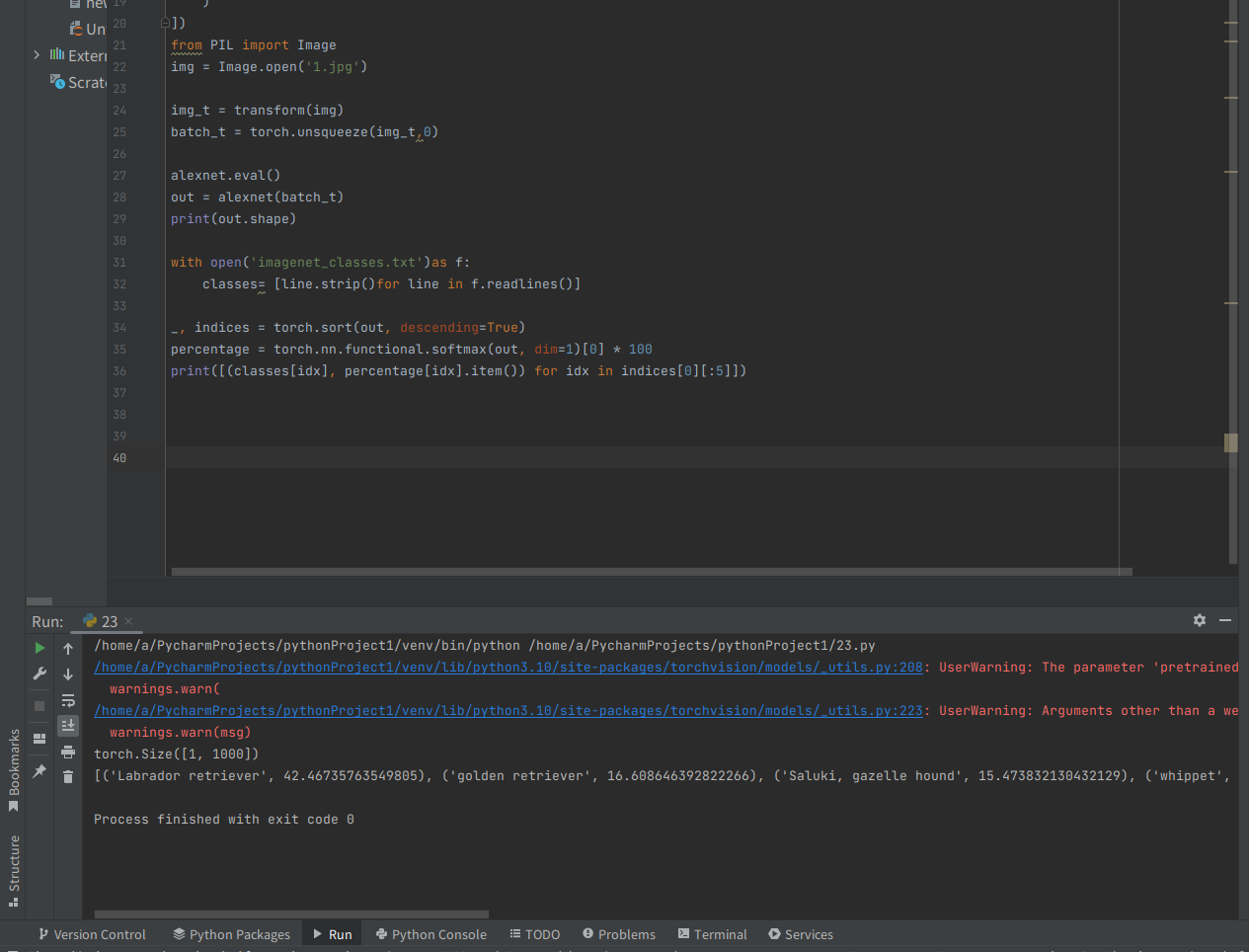
출력된 값들은 모두 개 품종이다.모델은 상당히 높은 신뢰도를 가진 개 라고 예측할 수 있지만 품종에 대해서 까지는 확신할 수 없었다.
이미지 분류에 ResNet 사용
ResNet정리
이번에는 resnet101-101 layer Convolutional Neural Network를 사용한다.resnet101에는 training 과정에서 조정된 약 4450만개의 매개변수가 있다.
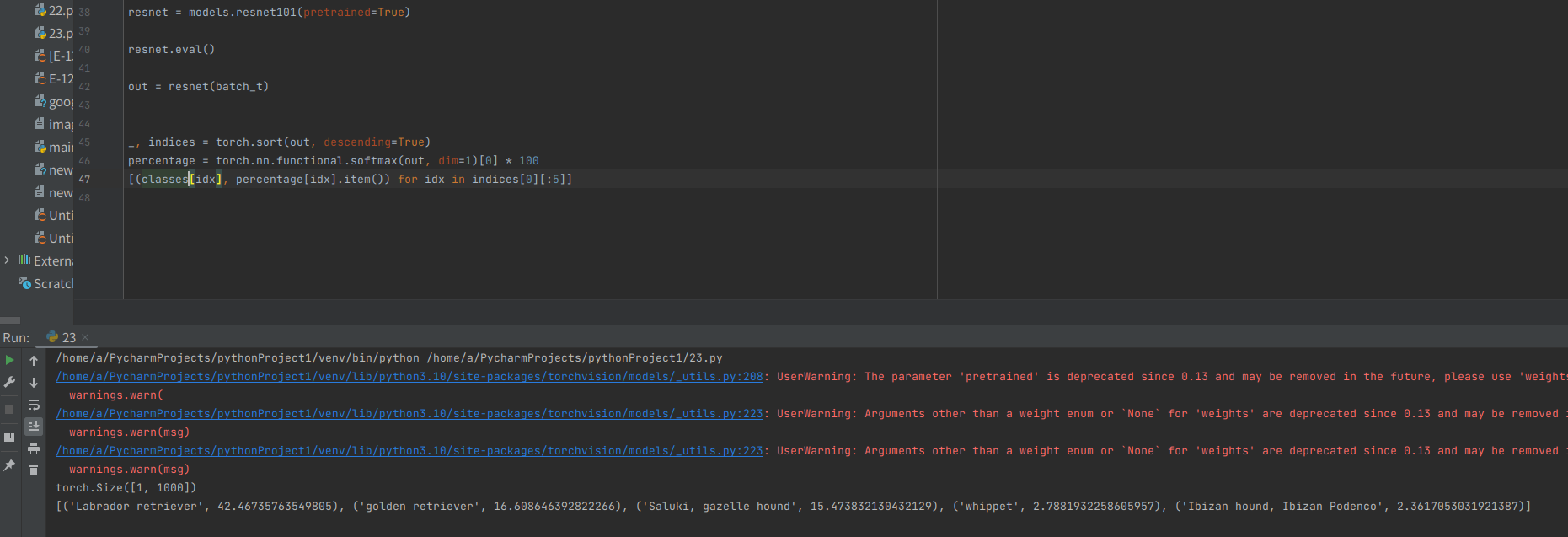
AlexNet과 마찬가지로 ResNet은 매우 높은 신회도로 개를 예측하고 48.25%의 신뢰도로 래브라도 리트리버임을 예측했다.
모델 비교
전 단계까지 pre-trained모델을 사용하여 이미지 분류를 진행하는 방법을 실습해 보았으나,특정 작업에 어떤 모델을 선택할지 결정하는 방법은 알 수 없었다.따라서 아래 기준으로 pretrained 모델을 비교한다.
- Top-1 Error : 신뢰도가 가장 높은 모델이 예측한 클래스 가 실제 클래스와 같지 않으면 Top-1 오류가 발생한다 .
2.상위 5개 오류 : 상위 5개 오류는 실제 클래스가 모델에서 예측한 상위 5개 클래스(신뢰도 기준으로 정렬)에 없을 때 발생한다.
3.CPU 의 추론 시간 : 추론 시간은 모델 추론 단계에 소요되는 시간이다.
4.GPU의 추론 시간
모델 크기 : 여기서 크기는 PyTorch에서 제공하는 사전 훈련된 모델의 .pth 파일이 차지하는 물리적 공간을 나타낸다.
모델 정확도 비교
첫번째 기준은 Top-1 및 Top-5 오류로 구성된다.Top-1오류는 상위 예측 클래스가 실제와 다를 때의 오류를 나타낸다.
문제가 다소 어려운 문제이므로 Top-5오류라는 또 다른 오류 측정이 있다.상위 5개의 예측클래스 중 어느것도 맞지 않을 경우에 예측은 오류로 분류된다.
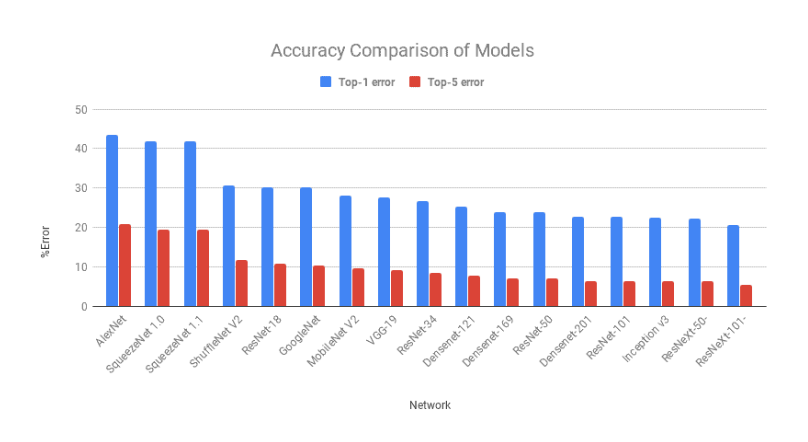
그래프에서 두 오류가 비슷한 양상을 띄는것을 유의해야 한다.
AlexNet은 Deep Learning을 기반으로 한 첫번째 시도였으며 후에 오류가 개선되었다.주목할 만한 점은 GoogLeNet,ResNet,VGGNet,ResNext이다.
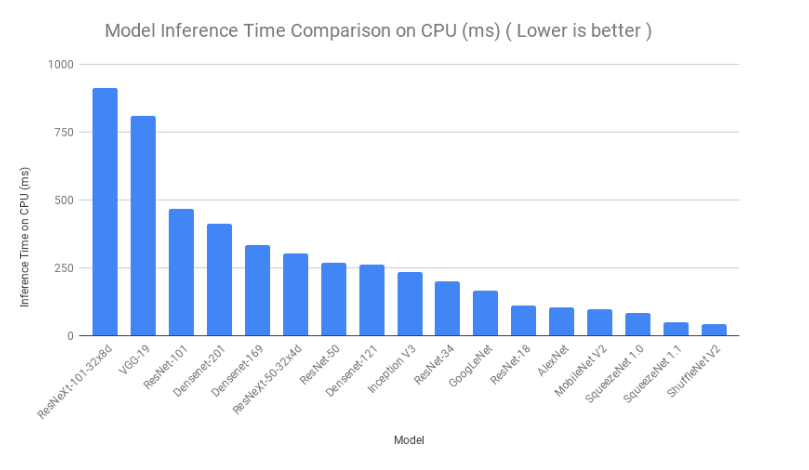
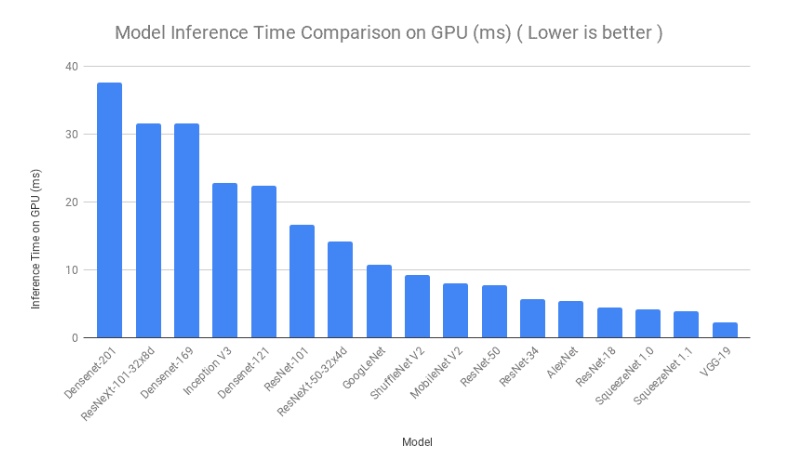
추론시간 비교
다음은 모델 추론에 소요된 시간을 기준으로 모델을 비교한다.하나의 이미지가 각 모델에 여러 번 제공되었고 모든 반복에 대한 추론 시간이 평균화 되었다.Google colab에서 CPU와 GPU를 이용해 프로세스가 실행되었다.순서에 약간의 변형은 있었으나 SqueezeNet,ShuffleNet및 ResNet-18의 추론시간이 매우 낮았음을 알 수 있다.
모델 크기 비교
Android 또는 ios기기에서 딥러닝 모델을 사용할때 모델 크기가 결정적인 요소가 되며 때때로 정확도보다 더 중요하다.
SqueezeNet의 최소 모델 크기(5MB)가 가장 작았으며 ShuffleNet V2(6MB) 및 MobileNetv2(14MB)이 차례로 작았다.모바일 환경에선 이런 모델을 사용하는것이 다른 모델보다 더 유리하다.
결론
특정 기준에 따라 어떤 모델이 더 나은 성능을 보여주는지 살펴보았다.아래 Bubble 차트를 참고해 모델을 선택할 수 있다.
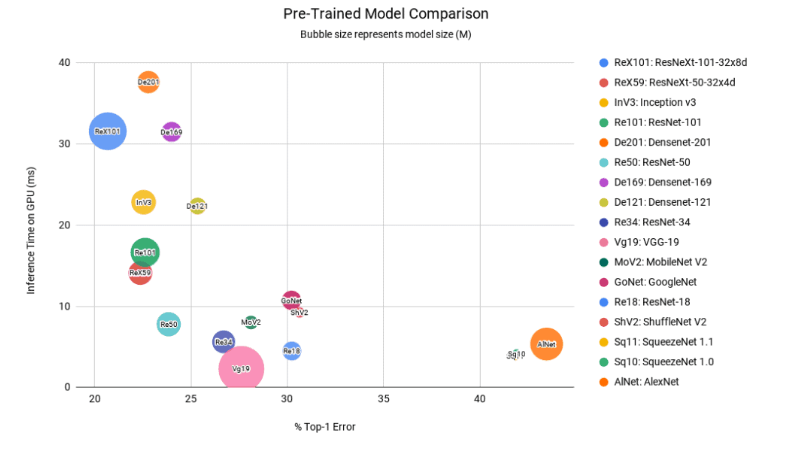
x좌표는 Top-1오류이다(낮을수록 좋음).y좌표는 GPU의 추론시간(ms,낮을수록 좋음).Bubble의 크기는 모델의 크기를 보여준다(작을수록 좋음).또한 원점 근처의 Bubble은 정확도와 속도 모두 좋다.
해당 그래프로 추론할수 있는 내용은
-
ResNet50이 세가지 조건(크기가 작고 원점에 가까움)측면에서 제일 만족한다.
-
DenseNets및 ResNext101은 추론시간이 길다.
-
AlexNet과 SqueezeNet의 오류율은 꽤 높다.
다음 게시물에서는 Pytorch를 이용해 custom dataset을 이용해 모델을 훈련하기위한 전이학습 방법을 다룬다.
