회사 업무적으로 필요한 내용은 아니었다. 동료 분석가들끼리 고민하는 내용이 상무, 회장 등 임원분들의 이해를 돕게끔 설명하는 과정에서 어려운 부분이 많았다. 예측력보다는 설명력을 요구하는 경우가 많았고, 그러던 도중에 자연스럽게 XAI(설명가능한 인공지능)을 접하게 되었다.

머신러닝, 딥러닝을 진행하다보면 블랙박스(머신러닝 모델의 의사결정 과정을 인간이 이해할 수 없을 때) 부문에 있어서 궁금증이 생길 수 밖에 없다. XAI는 이러한 블랙박스 성향을 인간이 이해할 수 있을 때까지 분해하는 기술이다. 시각화와의 XAI의 차이점은 해석이 가능한지 유무에 따라 차이를 보인다. 일전에 의사결정나무에서 배웠던 피쳐 중요도(Feature Importance), 분류 모델에서 어떤 영역을 집중적으로 분석했고 분류 근거로 사용했는지를알려주는 LIME(Local Interpretable Model-agnostic Explanations), 어떠한 결과값의 기여도를 측정하는 샤플리 값(Sharply Value)이 기억에 남는다. 신경망이나 이미지 분석은 분석 경험과 지식이 부족해 필터 시각화와 LRP는 크게 기억에 남지 않았다.
[LIME]
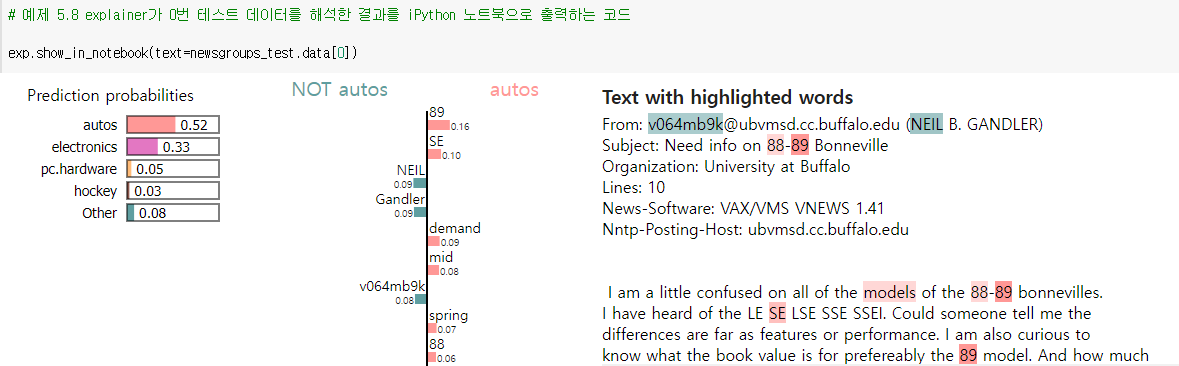
업무 특성상 텍스트 분류를 많이 진행하는 데, LIME을 이용한 텍스트 분류 사례는 흥미로웠다. 분류 카테고리에 해당할 확률과 어떠한 텍스트가 해당 카테고리에 미칠 영향을 색칠로 보여준다. 다음은 Scikit-Learn의 20 news Group 예제를 적용한 결과물이다. Lime에 따르면 해당 문서는 Autos(자동차)로 분류되었고 Autos에 분류에 긍정적인 단어는 Spring, 89, 88, SE 등으로 확인되었으며 우측에 Highlighted Word로 이를 확인해 볼 수 있다.
[Sharply Value]
샤플리 밸류는 어떠한 결과값에 대한 기여도를 측정해주는 방법론으로, 보스톤 부동산 가격에 끼치는 요인에 대한 분석이 예제로 주어졌다. 부동산 가격에 긍정적인 영향을 끼치는 요인은 LSAT(하위 계층 비율), AGE(30년 이상 주택 비율), 부정적인 요인으로는 RM(방 개수), DIS(주요 업무지구 접근성)으로 드러났다.

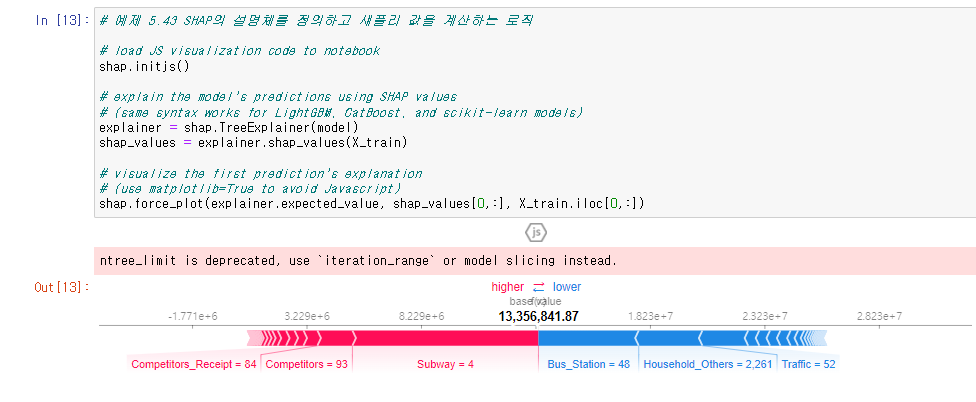
내가 맡고 있는 메인 업무는 아니지만 상권 분석에 이를 접목해 볼 수 있을 것 같다는 생각이 들었다. 현재 회사는 300개의 로드샵 매장을 운영 중인데 로드샵 매출에 끼치는 요인을 분석하면 매장 관리 등에 있어서 아이디어를 도출할 수 있을 것이라고 보았다. 현재 매장별 매출, 고객, 주문 정보를 추출하고 공공데이터 포털(sg.sbiz.or.kr/godo/index.sg)을 활용해서 매장 위치 1km 이내의 유동인구, 직장인구, 거주인구, 소득 정보, 화장품 판매업 매장 수, 중고등학생 수 등의 공공데이터를 취합시키는 작업을 진행했다. 1차 테스트 결과, 지하철 수, 경쟁업체, 경쟁업체 매출이 로드샵 매출에 있어서 긍정적인 요소로 확인되었고 버스정류장, 아파트 제외 주택, 교통 시설 등이 부정적인 요소로 확인되었다.
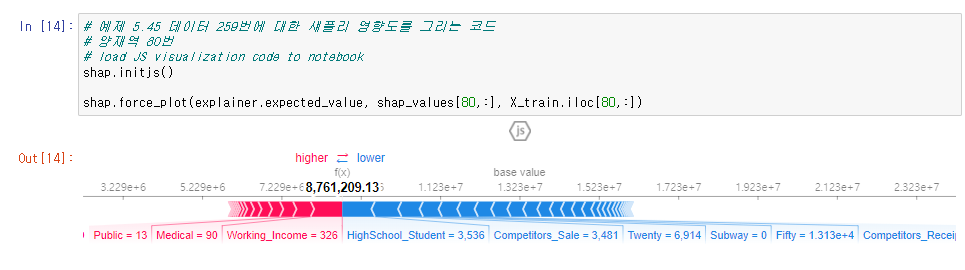
매장별로 나눠서도 보았다. 양재역점(60번)을 보았는데 고등학생, 20대, 지하철, 50대 인구, 경쟁업체 매출, 경쟁업체 판매갯수 등이 부정적인 영향을 보였고, 직장인구의 소득, 의료시설 및 공공시설 수가 긍정적인 영향을 미친 것으로 확인되었다. 팀장님 보고했을 때는 나쁘지는 않은 데 설명 부문에서 좀 아쉬운 부문이 있고 피쳐 엔지니어링 등을 좀 더 검토해보기로 했다.