Data preparation steps
Target Data (Json): National Museum and Art Gallery Information Standard Data
Source: Public Data Portal
DownLoad: National Museum and Art Gallery Information Standard Data.json
Call required module
import json
with open('../data/전국박물관미술관정보표준데이터.json', 'r', encoding='utf-8') as f:
json_data = json.load(f)
Step 1: Create DataFrame with Json Data
1-1 Creating a Pandas DataFrame with Json Data
df_target = pd.json_normalize(json_data, record_path="records")
df_target.head(2)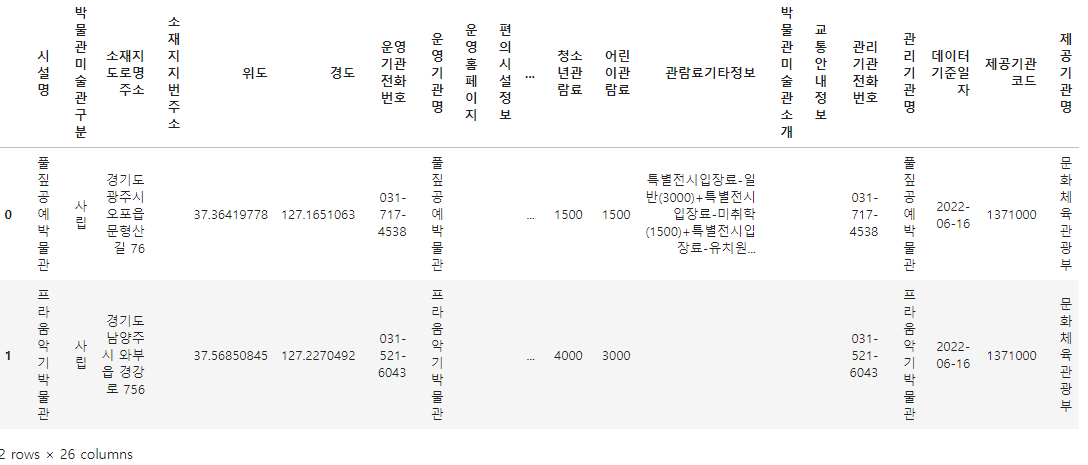
Step 2: Preprocessing DataFrame 01
2-1) Basic preprocessing
The null value of the corresponding json_data is composed of "", so if you check the null value using df_target.info() or df_target.isna(), etc., it will say that there is no null value. Therefore, in order to properly check this data, insert a Null value instead of "".
-
Condition 1: (""or '') consists only of double quotation marks (or single quotation marks) without spaces.
-
Condition 2: Change ""(or '') to a null value (None).
-
Condition 3: Do not change the index or order.
-
Condition 4: Assign the result DataFrame to the 'df_target' variable.
df_target.replace("", None, inplace=True)
df_target.isnull().sum()
2-2 Basic preprocessing 02
When creating json data as Pandas DataFrame, numeric data was recognized as string.
-
Condition 1: Change the Column Data of type_int_col below to integer (int) type Data.
-
Condition 2: Change the Column Data of type_float_col below to float type Data.
-
Condition 3: If there is a null value in the Data to be changed, fill it with 0.
-
Condition 4: Do not change the index or order.
-
Condition 5: Assign the result DataFrame to the 'df_target' variable.
type_int_col = ['어른관람료', '청소년관람료', '어린이관람료']
type_float_col = ['위도', '경도']
# con 1, 2
df_target[type_int_col] = df_target[type_int_col].astype('int')
df_target[type_float_col] = df_target[type_float_col].astype('float')
# con 3
df_target['경도'] = df_target['경도'].fillna(0)
df_target.head(2)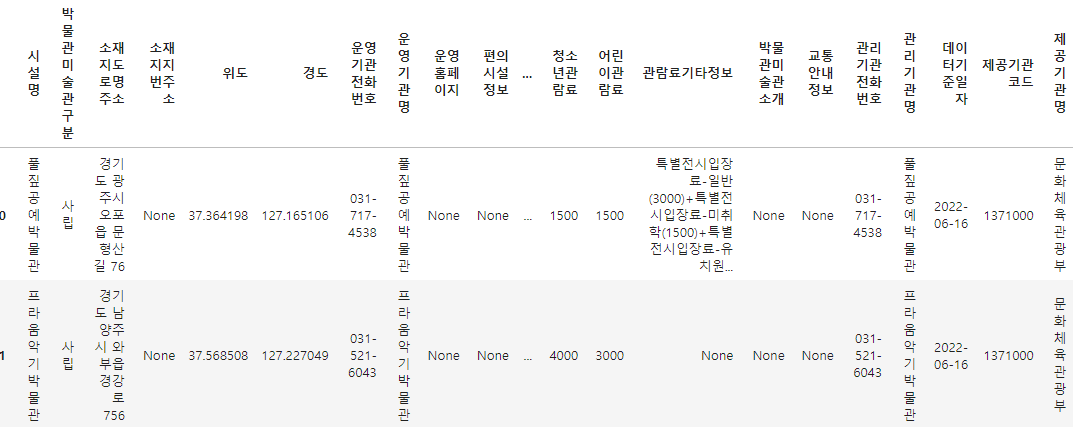
2-3 Basic Preprocessing 03
Improve the readability of the data by deleting the data of the column that is not related to the analysis.
-
Condition 1: Delete the column data of drop_col below.
-
Condition 2: Do not change the index or order.
-
Condition 3: Assign the result DataFrame to the 'df_target' variable.
drop_cols = ['소재지지번주소', '위도', '경도', '운영기관전화번호','운영기관명', '운영홈페이지', '편의시설정보', '휴관정보',
'관람료기타정보', '박물관미술관소개', '교통안내정보', '관리기관전화번호', '관리기관명', '제공기관코드', '제공기관명']
df_target.drop(drop_cols, axis=1, inplace=True)
df_target.head(2)
2-4 Basic preprocessing 04
If the admission fee for adults, teenagers, and children is strange, delete the row data itself.
-
Condition 1: The column related to the admission fee is type_int_col defined above.
-
Condition 2: If the admission fee is not divisible by 10 won, it is judged as an outlier. Delete the row.
-
Condition 3: If the admission fee is 100,000 won or more, it is judged as an outlier. Delete the row.
-
Condition 4: Do not change the index or order.
-
Condition 5: Assign the result DataFrame to the 'df_target' variable.
for col in type_int_col:
df_target.drop(df_target[(df_target[col] % 10 != 0) |
(df_target[col] >= 100000)].index, inplace=True)
df_target.head(2)
Step 3: DataFrame Preprocessing 02
3-1 Advanced preprocessing 01
delete data of museums/art galleries that are closed or duplicated.
In addition to the conditions below, there are duplicate data, but this test proceeds by deleting only the duplicate data that meets the conditions below.
-
Condition 1: If the Facility Name Column data contains the word 'Closed', the corresponding row is deleted.
-
Condition 2: If the Facility Name Column data is duplicated, the data with the latest 'Data Reference Date' of the corresponding row is left and the row that is not the latest is deleted.
-
Condition 3: Whether the Facility Name Column data is duplicated is determined as a duplicate museum/art gallery if the value of the Facility Name Column data with the spaces removed matches.
-
Condition 4: Do not change the Index or order. - If you changed the order to solve the problem, sort it again in the Index order.
-
Condition 5: Assign the result DataFrame to the 'df_target' variable.
df_target.drop(df_target[df_target['시설명'].str.contains('휴관')].index, inplace=True)
df_target.sort_values(by='데이터기준일자', ascending=False, inplace=True)
df_target = df_target[~df_target.duplicated(['시설명'])]
df_target = df_target[~df_target['시설명'].str.replace(' ', '').duplicated()]
df_target = df_target.sort_index()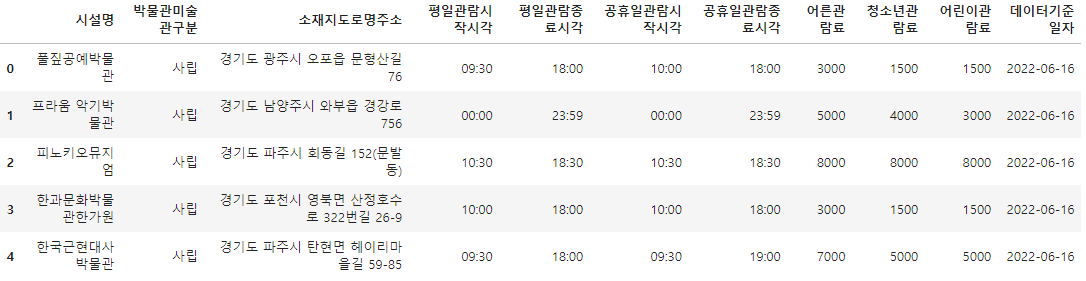
3-2 Advanced preprocessing 02
find out the 'opening hours' that tell me how many hours a museum/art gallery is open during the day on weekdays and public holidays.
-
Condition 1: The opening hours on weekdays are from 'Weekday opening time' to 'Weekday opening time'. Create a 'Weekday opening hours' column and enter the opening hours on weekdays.
-
Condition 2: The opening hours on public holidays are from 'Holiday opening time' to 'Holiday closing time'. Create a 'Holiday opening hours' column and enter the opening hours on public holidays.
-
Condition 3: 'Weekday opening hours' and 'Holiday opening hours' are expressed as floats in hours.
-
Condition 4: Do not change the index or order.
-
Condition 5: Assign the result DataFrame to the 'df_target' variable.
time_cols = ['평일관람시작시각', '평일관람종료시각', '공휴일관람시작시각', '공휴일관람종료시각']
for idx, row in df_target[time_cols].iterrows():
open_hour, open_min = map(int, row.평일관람시작시각.split(':'))
close_hour, close_min = map(int, row.평일관람종료시각.split(':'))
total = (close_hour - open_hour) + round((close_min - open_min) / 60, 2)
df_target.loc[idx, '평일관람가능시간'] = 24 if total > 23 else total
open_hour, open_min = map(int, row.공휴일관람시작시각.split(':'))
close_hour, close_min = map(int, row.공휴일관람종료시각.split(':'))
total = (close_hour - open_hour) + round((close_min - open_min) / 60, 2)
df_target.loc[idx, '공휴일관람가능시간'] = 24 if total > 23 else total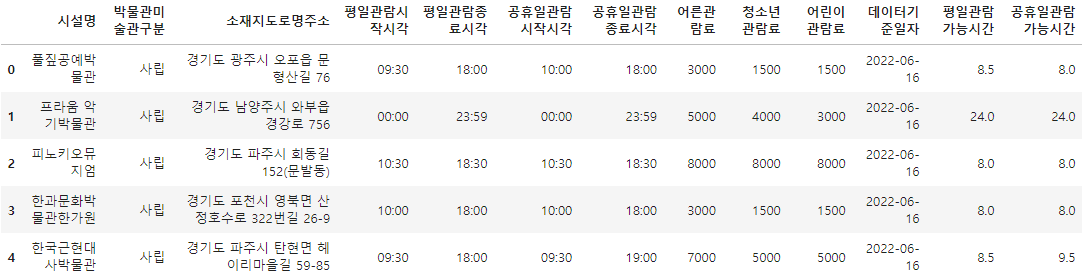
3-3 Advanced preprocessing 03
process the data of the 'Local Road Name Address' Column and divide it into Metropolitan Autonomy-Basic Autonomy (Administrative City)-Detailed Address.
-
Condition 1: The first word of the 'Local Road Name Address' Column data always means the name of the metropolitan autonomous government. Create a 'Metropolitan' Column and enter the name of the metropolitan autonomous government for the corresponding row data.
'Sejong Special City' has now been renamed to 'Sejong Special Self-Governing City'. Please reflect this. -
Condition 2: The second word of the 'Local Road Name Address' Column data mostly means the name of the basic autonomous government. Create a 'Basic' Column and enter the name of the basic autonomous government for the corresponding row data. - In the case of 'Jeju Special Self-Governing Province', there is no basic autonomous body, but the administrative city ('Jeju-si', 'Seogwipo-si') is located in the second word of the 'Location Road Name Address' Column data. Enter the administrative city in the 'Basic' Column. - In the case of 'Sejong Special Self-Governing City', there is no basic autonomous body. In the case of 'Sejong Special Self-Governing City', enter a null value (None) in the 'Basic' Column data.
-
Condition 3: In the 'Location Road Name Address' Column data, create a 'Detailed' Column and enter data that is not included in the metropolitan/basic autonomous body (including administrative city).
-
Condition 4: The data in the 'Location Road Name Address', 'Metropolitan', 'Basic', and 'Detailed Column (Row) must not have spaces before and after the data.
-
Condition 5: Do not change the index or order.
-
Condition 6: Assign the resulting DataFrame to the 'df_target' variable.
for idx, value in df_target['소재지도로명주소'].items():
if '세종특별' in value:
wide = '세종특별자치시'
basic = None
detail = tuple(value.split(' ', 1))[1]
else:
wide, basic, detail = tuple(value.split(' ', 2))
df_target.loc[idx, '광역'] = wide
df_target.loc[idx, '기초'] = basic
df_target.loc[idx, '상세'] = detail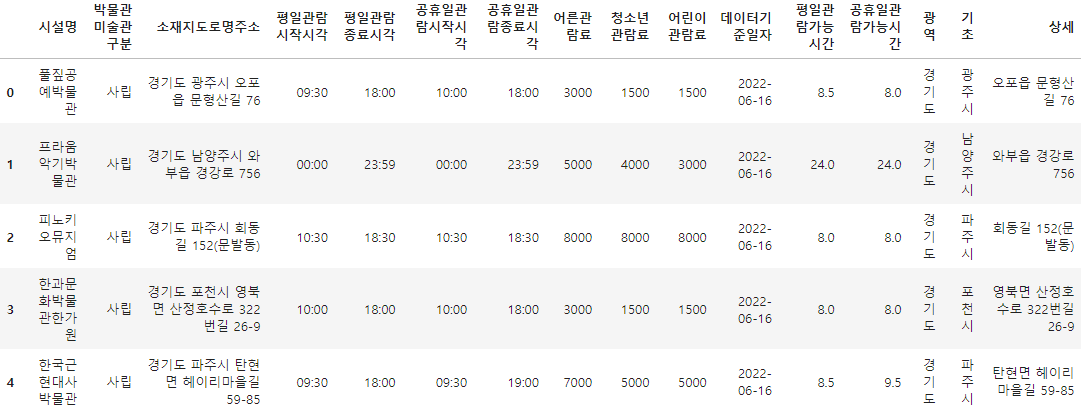
Step 4: Get the information
4-1 Get the information 01
Check the total number of museums/art galleries by metropolitan government.
-
Condition 1: Please display the total number of museums/art galleries by metropolitan government using the metropolitan government data in the 'metropolitan' Column of df_target.
-
Condition 2: The index of the result DataFrame is the metropolitan government. The priority of the metropolitan government is provided by the value of the province_dict below. Please list the order of the index according to the priority of the metropolitan government.
Source: Ministry of the Interior and Safety -
Condition 3: The name of the Column that displays the total number of museums/art galleries in the result DataFrame is 'Number of Museums/Art Galleries'.
-
Condition 4: Assign the result DataFrame to the 'df_result' variable.
province_dict = {
'서울특별시': 0,
'부산광역시': 1,
'대구광역시': 2,
'인천광역시': 3,
'광주광역시': 4,
'대전광역시': 5,
'울산광역시': 6,
'세종특별자치시': 7,
'경기도': 8,
'강원도': 9,
'충청북도': 10,
'충청남도': 11,
'전라북도': 12,
'전라남도': 13,
'경상북도': 14,
'경상남도': 15,
'제주특별자치도': 16
}
df_result = df_target.groupby('광역').size().to_frame(name='박물관미술관수')
df_result = df_result.sort_index(key=lambda x: x.map(province_dict))
display(df_result)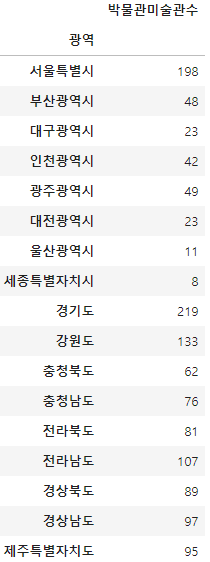
4-2 Get the information 02
check the metropolitan-basic autonomous governments (administrative cities) where the total number of museums/art galleries is 8.
-
Condition 1: Using the metropolitan autonomous government/basic autonomous government (administrative city) data in the 'metropolitan' and 'basic' columns of df_target, find the places where the total number of museums/art galleries is 8 by metropolitan autonomous government-basic autonomous government (administrative city).
-
Condition 2: Enter the metropolitan autonomous government in the 'metropolitan' column of the result DataFrame and the basic autonomous government (administrative city) in the 'basic' column.
-
Condition 3: List the 'metropolitan' column in order of metropolitan autonomous government priority, as in problem 4-1. Refer to province_dict in 4-1
-
Condition 4: If there is the same metropolitan autonomous body, list the data of the 'Basic' Column in reverse alphabetical order.
-
Condition 5: The name of the Column that indicates the total number of museums/art galleries in the result DataFrame is 'Number of Museums/Art Galleries'.
-
Condition 6: Set the Index in ascending order of numbers (integers).
-
Condition 7: Assign the result DataFrame to the 'df_result' variable.
df_result = df_target.groupby(['광역', '기초'], dropna=False).size().to_frame(name='박물관미술관수')
df_result = df_result[df_result['박물관미술관수'] == 8]
df_result = df_result.sort_index(level=1, ascending=False).sort_index(level=0, key=lambda x: x.map(province_dict), sort_remaining=False)
df_result = df_result.reset_index()
df_result.head(5)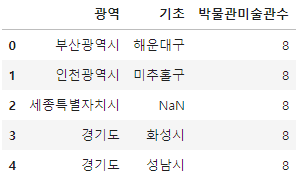
4-3 Getting the information 03
find out the average admission fee difference between metropolitan governments and museum art gallery categories (private, national, public, university).
-
Condition 1: Using the metropolitan government/museum art gallery category data in the 'metropolitan' and 'museum art gallery category' columns of df_target, find the largest and smallest differences between the average adult admission fee and the average child admission fee by metropolitan government-museum art gallery category.
However, if either the adult admission fee or the child admission fee is 0 won (free), please exclude museums/art galleries from the average calculation. -
Condition 2: Enter the metropolitan government in the 'metropolitan' Index of the result DataFrame, and the museum art gallery category in the 'museum art gallery category' Index.
-
Condition 3: List the 'metropolitan' Index in order of metropolitan government priority, as in problem 4-1. - Refer to province_dict in 4-1
-
Condition 4: The 'Adult Admission Fee' Column of the result DataFrame is the average adult admission fee by metropolitan government-museum/art gallery division, the 'Children's Admission Fee' Column is the average children's admission fee by metropolitan government-museum/art gallery division, and the 'Admission Fee Difference' Column is the average adult admission fee by metropolitan government-museum/art gallery division - average children's admission fee (difference). - For the adult/child admission fee and admission fee difference, enter an integer value rounded to the first decimal place from the average value. - Example: 2,978.5 won -> 2,980.0 won (rounded to the first decimal place) -> 2,980 won (integer value)
-
Condition 5: Assign the result DataFrame to the 'df_result' variable.
df_result = df_target[~((df_target['어른관람료'] == 0) | (df_target['어린이관람료'] == 0))]
df_result = df_result.pivot_table(index=['광역', '박물관미술관구분'],
values=['어른관람료', '어린이관람료'],
aggfunc='mean')
df_result = df_result.apply(lambda x: round(x, -1))
df_result['어른관람료'] = df_result['어른관람료'].astype(int)
df_result['어린이관람료'] = df_result['어린이관람료'].astype(int)
df_result['관람료차이'] = df_result['어른관람료'] - df_result['어린이관람료']
df_result = df_result[(df_result['관람료차이'] == df_result['관람료차이'].min()) |
(df_result['관람료차이'] == df_result['관람료차이'].max())]
df_result.head(2)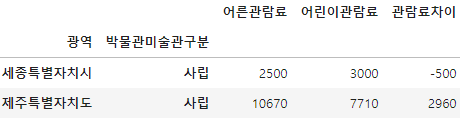
4-4 Get the information 04
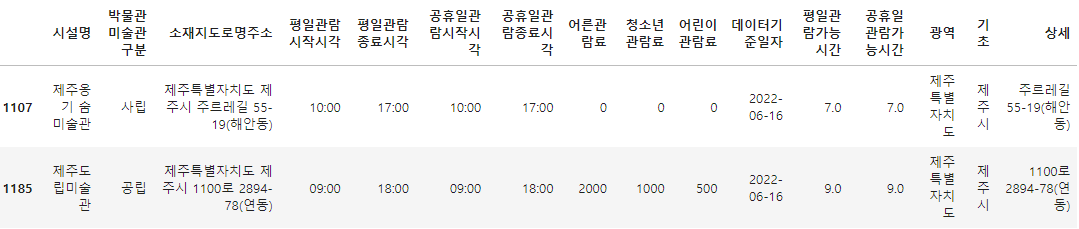
A family (2 adults, 1 teenager, 1 child) wants to visit an art gallery in Jeju-si, Jeju Special Self-Governing Province on a public holiday.
Please show a list of art galleries with a total admission fee of 20,000 won or less and a viewing period of 4 hours or more on a public holiday.
-
Condition 1: The total admission fee for a family (2 adults, 1 teenager, 1 child) must be 20,000 won or less.
-
Condition 2: We want to go to an art gallery in Jeju-si, Jeju Special Self-Governing Province.
Art Gallery: In this test, we define 'Art Gallery' as the data in the facility name column of df_target that contains the letters <'Art Gallery' or 'Gallery' or 'Art'>. -
Condition 3: We want to go on a public holiday. It must be an art gallery that can be viewed for 4 hours or more on a public holiday.
-
Condition 4: The Frame of the Art Gallery List is the same as df_target.
-
Condition 5: Assign the result DataFrame to the 'df_result' variable.
money = (df_target['어른관람료'] * 2 + df_target['청소년관람료'] + df_target['어린이관람료']) <= 20000
location = df_target['기초'] == '제주시'
gallery = df_target['시설명'].str.contains('미술관|갤러리|아트')
holiday = df_target['공휴일관람가능시간'] >= 4
df_result = df_target[money & location & gallery & holiday]