Internet usage data by country
Data original source
Target Data(CSV): Global Internet Usage(국가별 인터넷 사용률)
Source: Kaggle
DownLoad: archive.zip
Reference Data01(HTML Link): Population by country Data
Source: Wiki
Reference Data02(CSV): ISO code / region data by country
Source: Kaggle
DownLoad: archive.zip
data call
import pandas as pd
df_target = pd.read_csv('../data/gapminder_internet.csv')
df_target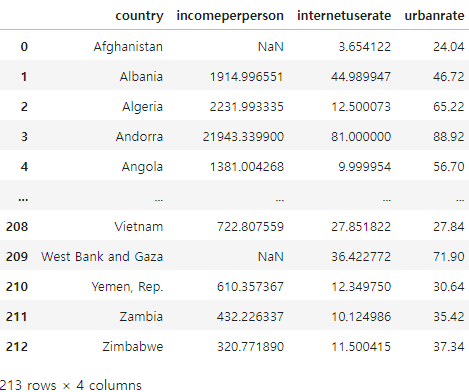
Step 1: Target Data Load & Preprocessing
1-1 Null value cleansing
- Condition 1: If there is a null value in any of the 'incomeperperson', 'internetuserate', and 'urbanrate' columns, drop the row.
Check basic data information
df_target.info()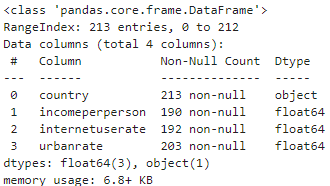
Check null value
df_target.isnull().sum()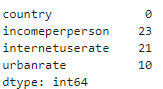
Clear null values
df_target.dropna(inplace=True)
df_target.isnull().sum()
Double-check data
df_target
1-2 Target Data Preprocessing
- Condition 1: Change the country name of df_target using df_target_change_list.
- Condition 2: Do not change Index or order.
df_target_change_list = [
(33, 'Cabo Verde'),
(35, 'Central African Republic'),
(41, 'Congo, The Democratic Republic of the'),
(42, 'Congo'),
(45, "Côte d'Ivoire"),
(49, 'Czech Republic'),
(53, 'Dominican Republic'),
(83, 'Hong Kong'),
(100, 'Korea, Republic of'),
(103, "Lao People's Democratic Republic"),
(112, 'Macao'),
(113, 'Republic of North Macedonia'),
(125, 'Federated States of Micronesia'),
(183, 'Eswatini'),
(210, 'Yemen')
]Change the value corresponding to the index using loc
for idx, val in df_target_change_list:
df_target.loc[idx, 'country'] = valCheck
df_target
1-3 Target Data Preprocessing 03
Use DataFrame(df_target) and pycountry Library to obtain the country code according to the conditions below.
Reference: pycountry.countries :
Python Library that allows you to obtain country-specific codes based on ISO 3166-2 (an international standard that assigns unique signs (codes) to the names of major constituent units of countries and territories around the world)
-
Condition 1: Add the 'code' column to df_target and enter the 2-character country code (alpha_2) that matches the country name of each row.
-
Condition 2: Try using general search (pycountry.countries.get(name=country_name)) first, and if no results are found, search using fuzzy search (pycountry.countries.search_fuzzy(country_name)).
-
Condition 3: When using fuzzy search, enter the country code of the first value (index=0) in the result list.
-
Condition 4: Do not change the index or order.
Convert to code for each country using pycounuty
import pycountry
country_list = []
for n in range(len(df_target)):
try:
country_name = df_target['country'].values[n]
country = pycountry.countries.get(name = country_name)
print(country.alpha_2)
country_list.append(country.alpha_2)
except AttributeError as e:
country_name = df_target['country'].values[n]
country = pycountry.countries.search_fuzzy(country_name)
print(country[0].alpha_2)
country_list.append(country[0].alpha_2)
Check
len(country_list)
Step 2: Reference Data01: Import & Preprocessing & Merge
Load the table of population by country in the link provided below into a Pandas DataFrame as shown in the example according to the conditions below.
using "read_html" function from pandas
call data
url = 'https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population'
table = pd.read_html(url)
df_population = table[0]
columns = ['Rank', 'Country / Dependency', 'Population', '% of the world', 'Date', 'Source (official or from the United Nations)', 'Notes']
df_population.columns = columns
2-2 Population Data Preprocessing 01
Condition 1: Leave only 2 columns: 'Country / Dependency' and 'Population'.
Condition 2: Change the column name as follows.
'Country / Dependency' -> 'country'
'Population' -> 'population'
Condition 3: Delete the first index (index=0) whose value in the 'country' Column is 'World'.
Condition 4: Do not change Index or order.
df_population.drop(columns=[''Rank','% of the world', 'Date', 'Source (official or from the United Nations)', 'Notes'], inplace=True)
df_population.rename(columns={'Country / Dependency' : 'country', 'Population' : 'population'}, inplace=True)
df_population.drop(0, inplace=True)Check
df_population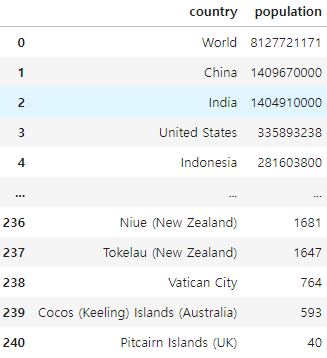
2-3 Population Data Preprocessing 02
Change the country name (column name: 'country') according to the conditions below using DataFrame (df_population) and df_population_change_dict below.
- Condition 1: Change the country name of df_population using df_population_change_dict.
- Condition 2: Do not change the index or order.
df_population_change_dict = {
'Bermuda (United Kingdom)': 'Bermuda',
'Cape Verde': 'Cabo Verde',
'DR Congo': 'Congo, The Democratic Republic of the',
'Ivory Coast': "Côte d'Ivoire",
'Greenland (Denmark)': 'Greenland',
'Hong Kong (China)': 'Hong Kong',
'South Korea': 'Korea, Republic of',
'Laos': "Lao People's Democratic Republic",
'Macau (China)': 'Macao',
'North Macedonia': 'Republic of North Macedonia',
'Micronesia': 'Federated States of Micronesia',
'Puerto Rico (United States)': 'Puerto Rico',
'Slovakia': 'Slovak Republic',
'East Timor': 'Timor-Leste',
}Changing values in a dataframe using a dictionary
df_population['country'] = df_population['country'].replace(df_population_change_dict)Check
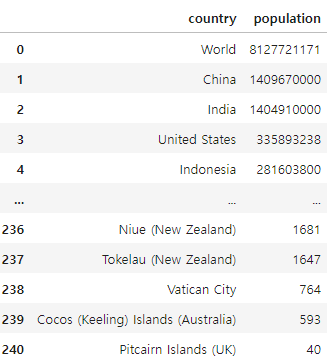
2-4 Merge Data
Merge the DataFrame (df_target) from step 1 and the DataFrame (df_population) from step 2-3 according to the conditions below.
-
Condition 1: Please combine data with the same country name (value of 'country' Column) in df_target and df_population.
-
Condition 2: Please specify the combining method as intersection (extract only cases where there are overlapping country names).
-
Condition 3: Merge DataFrames in the Column direction.
-
Condition 4: Sort in ascending order based on the 'code' Column.
-
Condition 5: Reset the index.
-
Condition 6: The resulting DataFrame must have 6 columns ('country', 'incomeperperson', 'internetuserate', 'urbanrate', 'code', 'population').
-
Condition 7: Specify the variable of the resulting DataFrame as 'df'.
Compare two data to find countries with different country names
t_co = df_target['country'].unique()
p_co = df_population['country'].unique()
for val in t_co:
if val not in p_co:
print(val)Change the country name accordingly
df_population = df_population.replace('Bermuda (UK)', 'Bermuda')
df_population = df_population.replace('Puerto Rico (US)', 'Puerto Rico')
df_population = df_population.replace('Democratic Republic of the Congo', 'Congo, The Democratic Republic of the')
df_population = df_population.replace('Republic of the Congo', 'Congo')
df_population = df_population.replace('Turkey', 'Türkiye')Merge data
df = pd.merge(df_target, df_population, on='country', how='inner')
df.sort_values(by='code', ascending=True, inplace=True)
df = df.reset_index(drop=True)Check
len(df)
Step 3: Reference Data02: Import & Preprocessing & Merge
call data
df_region = pd.read_csv('../data/continents2.csv')
df_region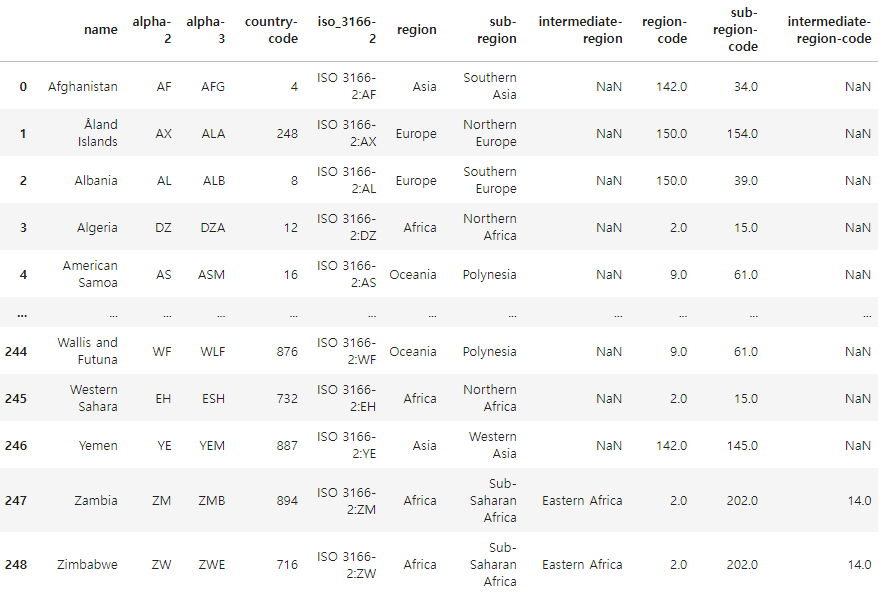
3-1 Region Data Preprocessing 01
- Condition 1: Because the country code of a specific country ('Namibia') is 'NA', when loading the DataFrame as above, the country code is treated as a NaN value. Change the country code of the country to 'NA'. (The type of the value must be string.)
Note Before changing the column name according to condition 3 below, the country code is in the 'alpha-2' column, and after the change, the country code is in the 'code' column. Country Name Column name is 'name'.
-
Condition 2: The df_region_drop_col below is a column that is not needed when analyzing data. - Refer to df_region_drop_col to drop the columns of df_region.
-
Condition 3: The df_region_rename_dict below consists of the existing column name and the key-value of the column name to be changed. - Refer to df_region_rename_dict to change the Column name of df_region.
-
Condition 4: Do not change the index or order.
# Con1 df_region.loc[df_region['name'] == 'Namibia', 'alpha-2'] = 'NA' # Con2 df_region.drop(df_region_drop_col, axis=1, inplace=True) # Con3 df_region.rename(columns=df_region_rename_dict, inplace=True)
Check
df_region
3-2 Merge Data
-
Condition 1: df, df_region, combine data with the same country code (value of 'code' Column).
-
Condition 2: Merging method as intersection (extract only when there are overlapping country codes).
-
Condition 3: Merge DataFrames in the Column direction.
-
Condition 4: Sort in ascending order based on the 'code' Column.
-
Condition 5 - The df_rename_dict below consists of the existing column name and the column name to be changed as key-value. - Refer to df_rename_dict to change the column name of df.
-
Condition 6 - new_col_order below has the column name as the value in the order of the column to be changed. - Refer to new_col_order to change the order of columns in df.
-
Condition 7: Please drop the 'name' Column.
-
Condition 8: Please reset the index.
-
Condition 9: The resulting DataFrame must have 6 columns ('country', 'incomeperperson', 'internetuserate', 'urbanrate', 'code', 'population').
-
Condition 10: Please specify the variable of the resulting DataFrame as 'df'.
# Con 1,2,3,4
df = df.merge(df_region, how='inner', on='code').sort_values('code')
# Con 5,6,7
df.rename(columns=df_rename_dict, inplace=True)
df.drop(df_drop_col, axis=1, inplace=True)
df = df[new_col_order]
# Con 8
df.reset_index(drop=True, inplace=True)Check
df
Step 4: Analyzing Data (Weighted Average & Variance)
Ues dataFrame (df) to find the weighted average according to the conditions for each regional continent (sub_region).
Reference (average funtion unb numpy)
Weighted average: When calculating the average of data, the average value calculated by reflecting the weight corresponding to the importance or influence of the data value
-
Condition 1: Use population Column for weights.
-
Condition 2: Please indicate the internet use rate (internet_use_rate) and income per person (income_per_person) of the regional continent (sub_region) in the form of an index and column as shown in the table below.
index = ['region', 'sub_region']
column = ['weighted_ave_internet', 'weighted_ave_income'] -
Condition 3: Please specify the variable of the result DataFrame as 'df_result'.
create weighted_ave_internet
def internet_ave(group):
return np.average(group['internet_use_rate'], weights=group['population'])
df_group1 = df.groupby(['region', 'sub_region']).apply(internet_ave).to_frame()
df_group1.rename(columns={0 : 'weighted_ave_internet'}, inplace=True)
df_group1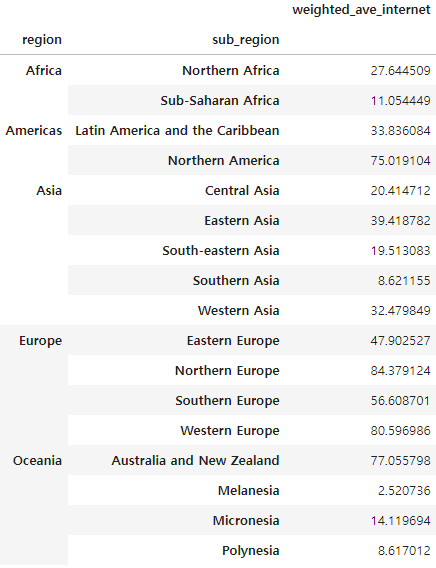
create weighted_ave_income
def income_ave(group):
return np.average(group['income_per_person'], weights=group['population'])
df_group2 = df.groupby(['region', 'sub_region']).apply(income_ave).to_frame()
df_group2.rename(columns={0 : 'weighted_ave_income'}, inplace=True)
df_group2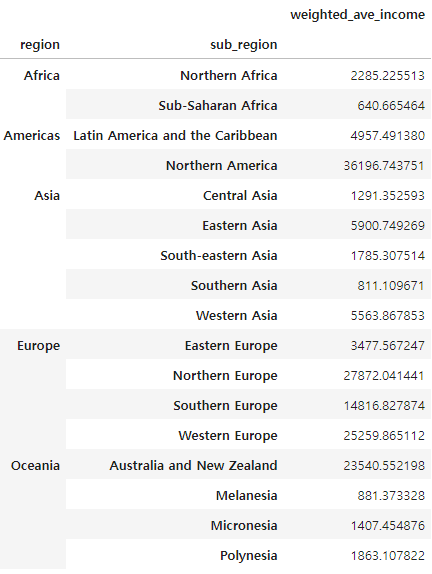
combine together
df_result = df_group1.merge(df_group2, how='inner', on=['region','sub_region'])
df_result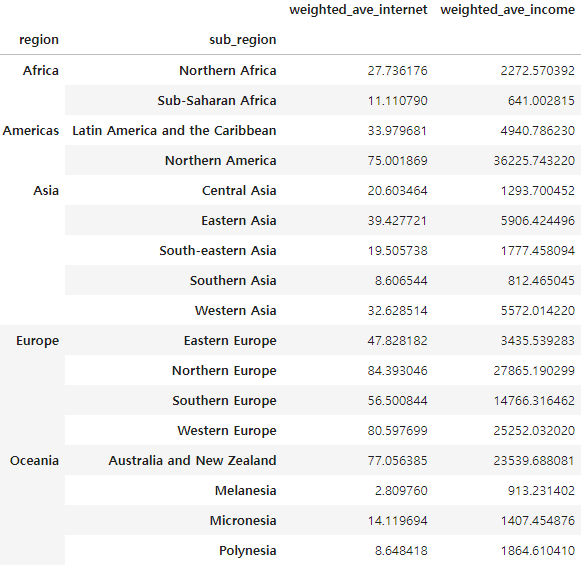
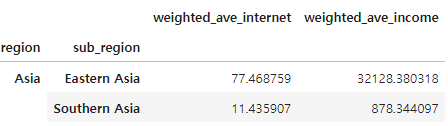
4-2 Calculate the standard average for specific conditions
Find the internet use rate (internet_use_rate) and income per person (income_per_person) in Eastern Asia and Southern Asia, excluding China and India, according to the conditions below.
-
Condition 1: Use population Column for weights.
-
Condition 2: Internet use rate (internet_use_rate) and income per person (income_per_person) in Asia (region) - Eastern Asia, Southern Asia (sub_region) excluding China (country code (code): 'CN) and India (country code: 'IN') ) in the form of an index and column as shown in the table below.
index = ['region', 'sub_region']
column = ['weighted_ave_internet', 'weighted_ave_income'] -
Condition 3: Please specify the variable of the result DataFrame as 'df_result'.
df_exclude = df[(df['code'] != 'CN') & (df['code'] != 'IN')]
df_Asia = df_exclude[(df_exclude['region'] == 'Asia')]
df_result = df_Asia[(df_Asia['sub_region'] == 'Eastern Asia') | (df_Asia['sub_region'] == 'Southern Asia')]
df_result