[논문 리뷰] Representing Long-Range Context for Graph Neural Networks with Global Attention (NeurIPS 2021)
Paper-review
Representing Long-Range Context for Graph Neural Networks with Global Attention
https://github.com/ucbrise/graphtrans
Representing Long-Range Context for Graph Neural Networks with Global Attention
Abstract
GNN은 구조화된 데이터 셋에서 강력한 구조이다. 그러나 현재 방법은 long-range dependencies를 표현하는데 어려움이 있다. GNN의 깊이와 넓이를 키우는 것은 더 큰 GNN이 기울기 소실과 표현 oversmoothing 같은 최적화 불안정성이 있기 때문에 표현력을 증가시키는데 충분하지 않고, pooling 기반의 접근 방식은 컴퓨터 비젼에서 만큼 일반적이지 않다. 이 연구에서, 우리는 global graph embedding을 얻기 위한 고유한 “readout” 방법을 사용하는 long-range pairwise relationship을 학습하기 위한 Transformer-based self-attention의 사용을 제안한다.
Introduction
GNN은 구조화된 데이터에서 심층 네트워크를 사용할 수 있게 해 주었다. GNN은 CNN과 유사하게 layer 층을 쌓아 가면서 receptive field를 확장해 local neighborhoods 넘어의 정보를 파악할 수 있다.
그렇지만 GNN의 성능은 depth가 깊어지면 급감한다. 이러한 한계는 GNN의 성능을 저하시킨다. 그렇지만 단순하게 GNN의 receptive field를 넓히는 것은 exponential 하게 증가하기 때문에 신호를 희석시키게 된다. 종종, 너무 깊은 GNN은 전체 그래프와 동일해 지는 oversmoothing 현상을 발생시킨다. 그러므로, 일반적인 GNN의 context size는 제한된다.
최근의 연구는 현대 CNN이 그러한 것 처럼 pooling operation을 사용해서 oversmoothing problem을 해결하고자 한다. Graph pooling은 점진적으로 이웃들을 하나의 node로 희석시킨다. 이론상 이런 과정은 중요하지 않은 정보를 필터링 하면서 long-range learning을 더 쉽게 해야 하지만, CNN에서처럼 일반적으로 사용될 만한 연산이 만들어 지지 않았다.
이 연구에서는 다른 접근 방법을 시도한다. 이것도 Computer Vision에서 Insight를 얻었다. 우리는 explicit하게 연관된 relational inductive biases가 encode된 기초적 연산을 Attention과 같은 purely learned opertion으로 대체했다.
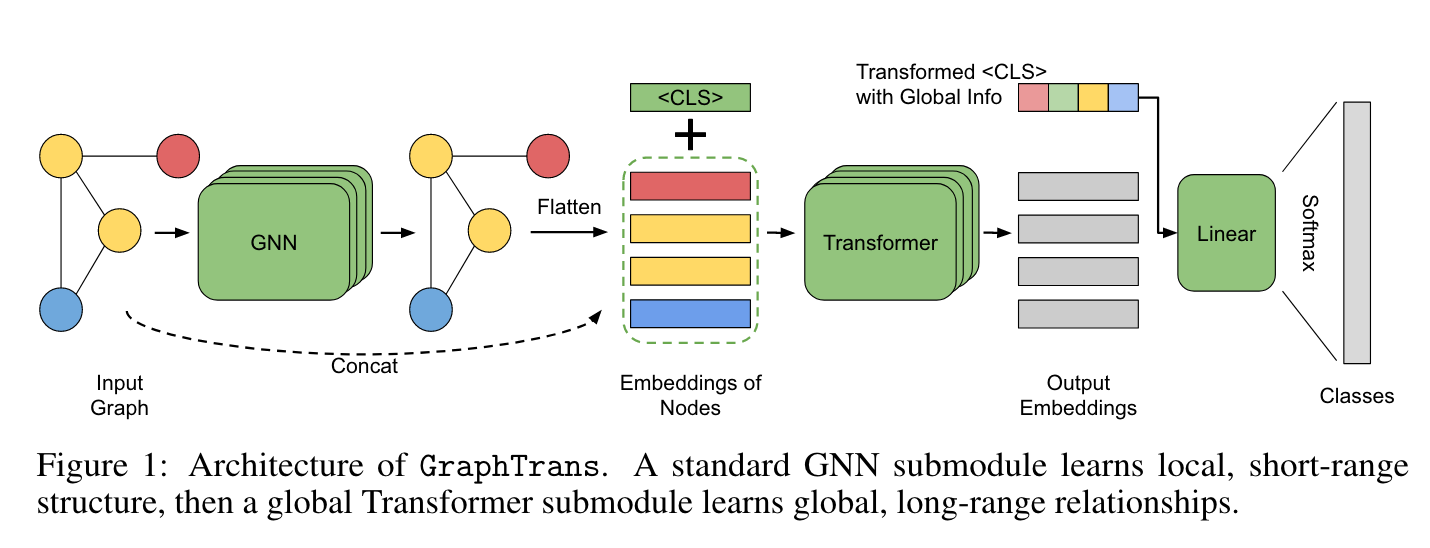
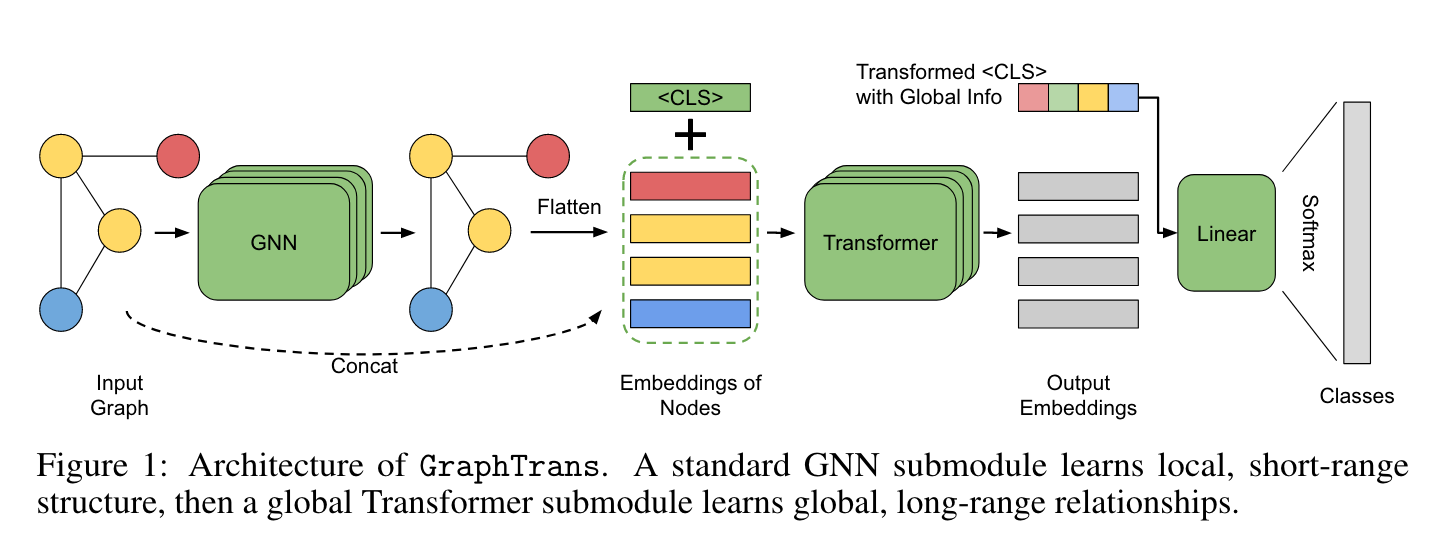
우리의 Graph Transoformer (i.e. GraphTrans)는 일반적인 GNN layer 위에 Transformer subnetwork를 쌓아 올렸다. 이 Transformer subnetwork는 explict 하게 position-agnositc fashion (position을 모르는 채로)으로 모든 pairwise node interactions을 계산한다. 이는 GNN이 local 정보를 학습하고 Transformer가 그 위의 global한 정보를 학습한다는 직관으로 이해된다. 이는 CV에서 강한 inductive bias가 단거리 패턴 인식에서는 중요하지만 long-range dependencies를 계산하는데에는 오히려 방해가 되는 것과 유사하다. positional encoding이 없는 Transformer는 permutation-invariant (순열 불변성)이기 때문에 graph에 자연스럽다. 게다가, GraphTrans는 어떤 특수한 모델과 구조도 필요로 하지 않고 존재하는 어떤 GNN backbone에 더해질 수 있다.
SOTA 달성했고 기존에 있던 복잡한 방법의 모델들을 앞지르는 성능을 보였다.
- Transformer를 통한 long-range reasoning이 GNN의 성능을 향상시켰다. Graph 내의 모든 pairwise node-node 상호작용을 모델링 하는 것이 large graph classification task에서 중요함을 제안한다.
- 고유한 GNN “readout module”을 제안한다. Transformer의 text-classification application에서 영감을 받아, output embedding이 모든 pairwise interactions을 통합하는 <CLS> token을 사용한다. 우리는 이러한 방법이 기존에 graph-specific pooling methods, “virtual node” approaches 같은 learned aggregation methods 뿐만 아니라 global pooling 같은 non-learned readout 방법들 보다 더 잘 작동함을 발견했다.
- GraphTrans를 사용해서 여러 OpenGraphBenchmark와 NCI biomolecular dataset에서 SOTA를 달성했다.
Related Work
Motivation: Modeling Long-Range Pairwise Interactions
GNN의 receptive field를 넓히고자 하는 연구는 계속 있었지만 제한적이었다.
이에 대한 해결책으로 최근 Computer VIsion 연구에서 찾아 볼 수 있다. Transformer가 전통적인 CNN convolution의 drop-in replacements (완전한 대체재)가 될 수 있다. attention layer가 local convolutions에서 유도되는 강한 relational inductive biases를 재생산 하도록 학습될 수 있다. 더 최근에는 전통 CNN backbone에 attention 스타일을 추가하는 SOTA 연구가 존재했다. 결과적으로 강한 relational inductive biases는 local, short- range correlations를 학습하는데는 유용하지만 long-range correlations를 학습하는데는 덜 유효하다.
우리는 이 insight를 GNN에 적용해서 GraphTrans를 만들었다. 우리의 Transformer application은 모든 node가 모든 다른 node를 attend를 하도록 만들었고 (다른 연구들은 이웃 노드에 대해서만 attention을 허용했음), favoring 인근 node가 아니라, 가장 중요한 node-node relationships을 학습하는 Transformer에 인센티브를 주도록 만들었다.
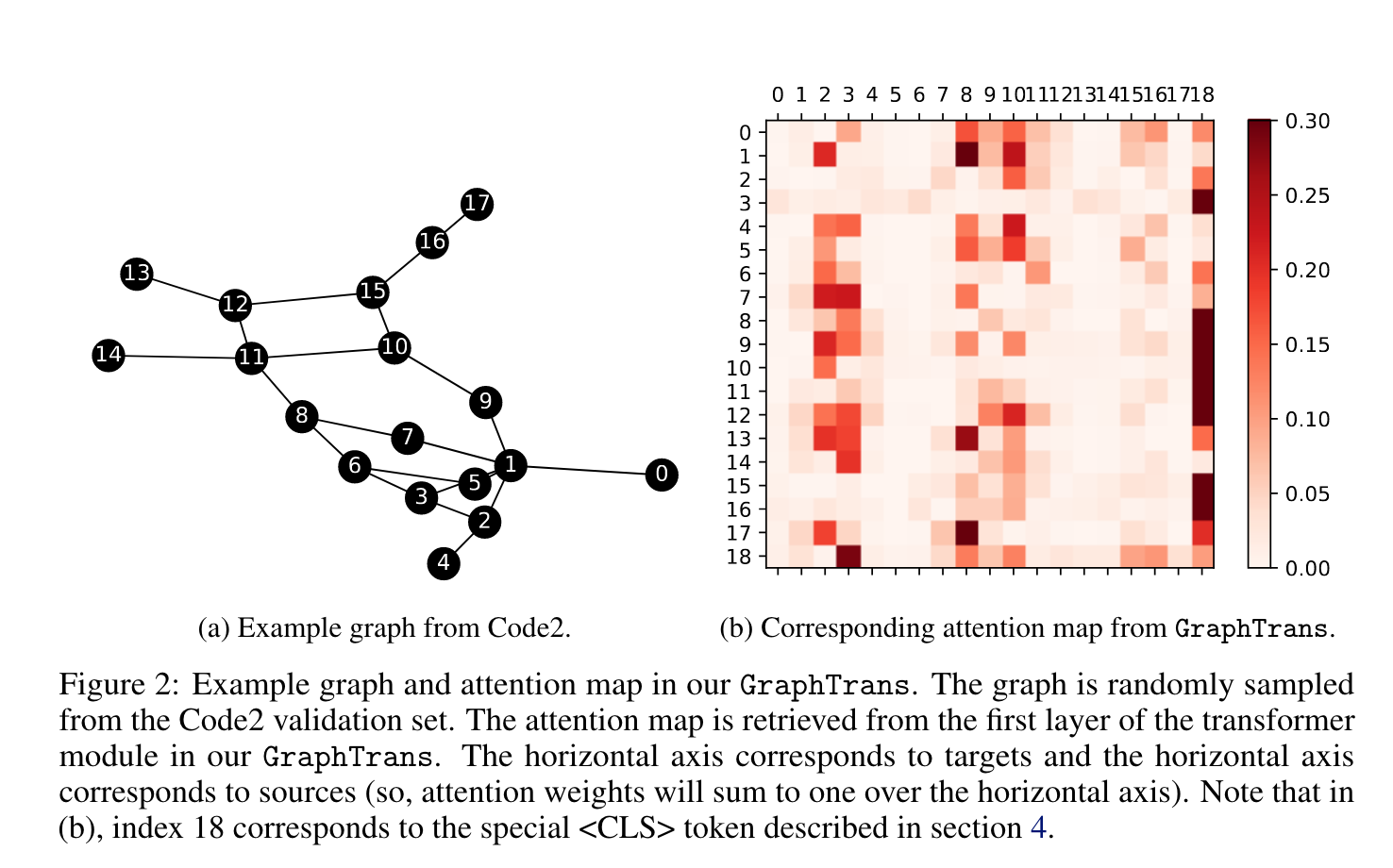
질적으로, 이 구조가 long-range relationship이 정말로 중요하다는 것을 보인다. Figure 2는 GraphTrans가 OGB Code2 dataset에 적용된 예시를 보여준다.
Learning Global Information With Graph Trans
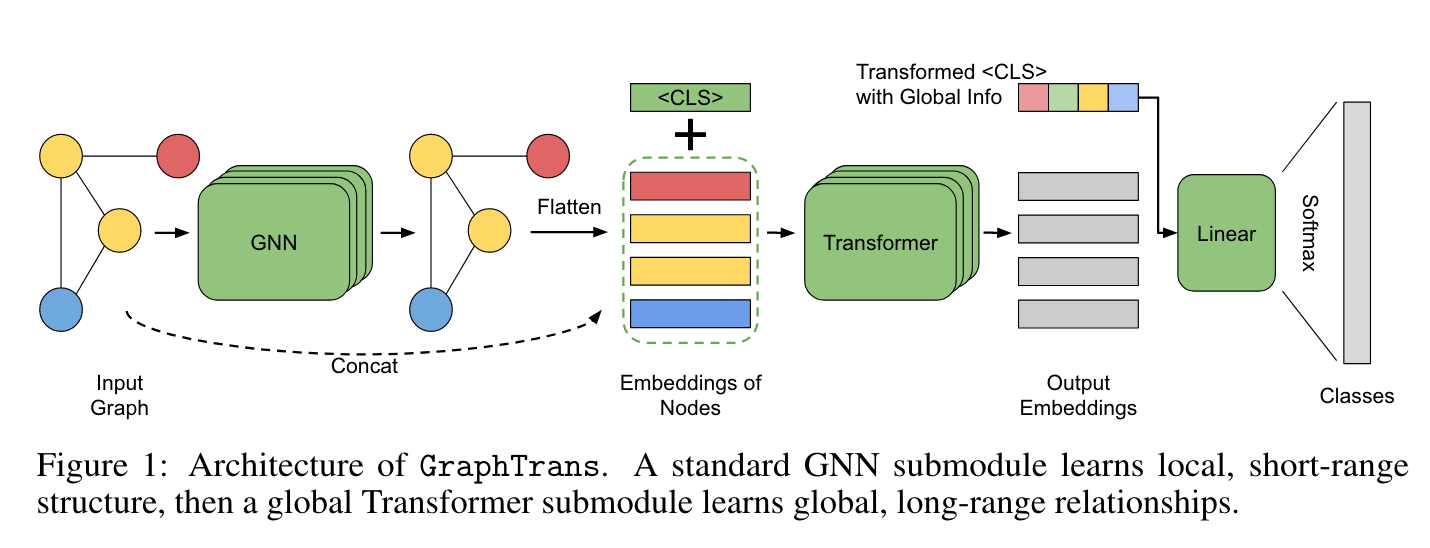
GraphTrans는 두 개의 주요한 모듈로 구성되어 있다 : GNN subnetwork, Transformer subnetwork.
GNN module
각각의 Graph 에 대해서 graph-specifit prediction target 가 있다고 생각하자. 각각의 노드 가 초기의 feature vector 를 가지고 있다. GraphTrans는 일반적으로 적용 가능한 framework여서 다양한 GNN과 함께 사용될 수 있기 때문에, Transformer로 들어오는 GNN에 대해서는 적은 가정만 포함하고 있다. 일반적인 GNN layer stack은 다음과 같이 표현된다.
은 GNN layer의 전체 수이고, 은 의 어떤 이웃이고, 은 neural network로 파라미터화 된 어떤 함수이다. 많은 GNN layer가 edge features를 포함하는데, 표현이 복잡해 지는걸 막기 위해 일단 여기서 논하지는 않겠다.
Transformer moduel
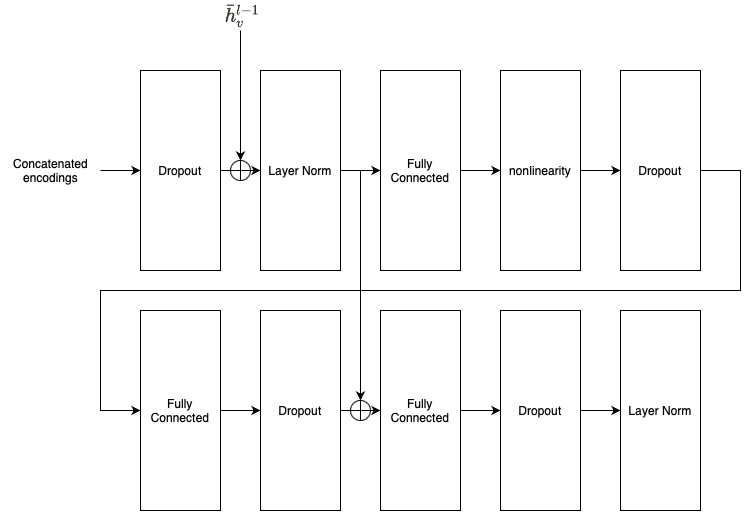
마지막 per-node GNN이 을 encoding하면, 우리는 이 값을 GraphTrans의 Transformer subnetwork로 보낸다. Transformer subnetwork는 다음과 같이 작동한다. 를 Transformer dimension으로 linear projection을 수행하고, embedding을 normalize하기 위해 Layer Normalization을 수행한다.
은 학습 가능한 weight matrix이고, 와 은 각각 Transformer dimension과 마지막 GNN의 dimension이다. 사영된 embedding 는 그리고 일반적인 Transformer layer stack에 추가적인 positional embeddings 없이 들어간다 - GNN이 이미 구조적인 정보를 node embeddings에 담았으리라 기대하기 때문이다.
은 각각 layer l 안의 single attention head를 위한 학습된 query, key, value matrix이다. 평균적으로, parallel attention head를 돌리고 per-head encoding의 결과인 를 concatenate한다. 합쳐진 encoding은 Dropout → Layer Norm → FC → nonlinearity → Dropout → FC → Dropout → FC → Dropout → Layer Norm sequence를 통과한다. 에서 첫번째 Dropout 다음, 첫 번째 FC sublayer에서 두번 째 FC sublayer 바로 다음에 나오는 곳으로 residual connections을 한다.
<CLS> embedding as a GNN “readout” method
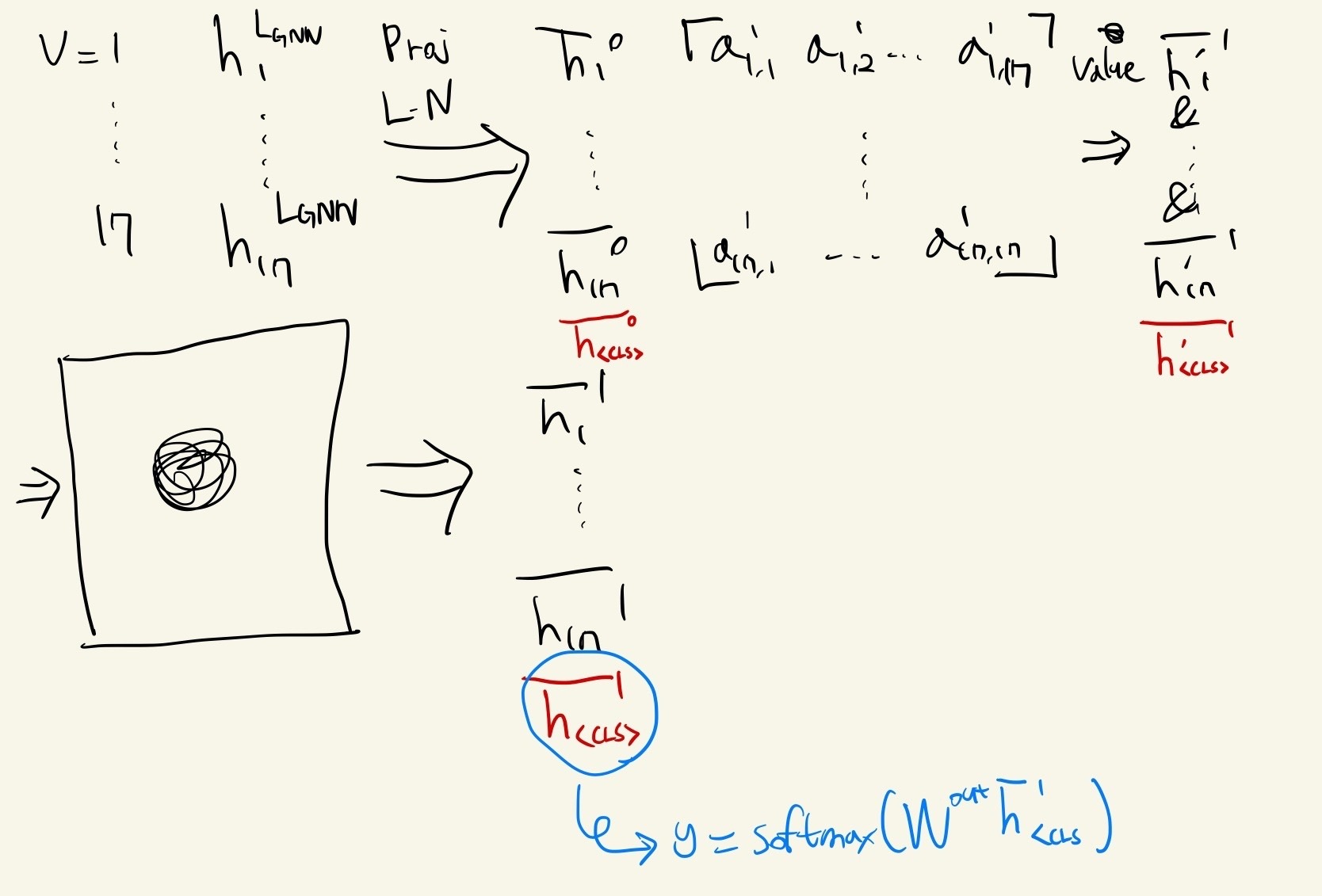
전체 그래프를 표현하기 위한 하나의 embedding을 필요로 한다. GNN에서는, 모든 node의 embedding이 하나의 embedding으로 표현되는 모듈을 “readout”이라고 한다. 가장 흔하게 사용되는 모듈은 simple mean, max pooling, 네트워크의 모든 다른 node들과 연결되는 “virtual node”가 있다.
이 연구에서, 다른 Transformer 적용 연구에서 사용된 것과 유사한 special-token readout moudule을 제안한다. Transformer의 text classification 작업에서, network로 보내기 전에 특수한 <CLS> token을 붙이는 관습이 있고, output embedding을 이 token의 포지션에 대응시켜서 전체 문장의 representation으로 사용한다. Transformer는 <CLS> token과 attention module에 있는 sentence 내의 각각의 다른 token의 one-to-one relationship을 계산함으로서 그 embedding의 정보를 종합하도록 학습하게 된다.
Special-token readout이 이와 유사하다. transformed per-node embeddings 를 feeding 할 때, sequence에 학습 가능한 를 추가하고, transformer output에서 오는 첫 번째 embedding 를 전체 그래프에 대한 representation으로 사용한다. (우리가 positional encodings을 포함하지 않기 때문에, speical token을 setence “앞에” 두는 것은 어떤 계산 상의 의미가 없음을 주목하라; 순서는 관습에 따라 정해졌다.) 마지막으로, prediction을 만들기 위해 softmax로 이어지는 linear projection을 적용한다.
는 Transformer layers의 수이다.
이러한 special-token readout mechanism은 virtual node readout의 “deep” 버젼으로 생각될 수도 있다. virtual node 방식은 그래프 내의 모든 노드가 자신의 정보를 virtual node로 보내야 하고, virtual node의 embedding을 제외한 graph node 사이의 pairwise relationship을 학습하지 않는다. (information bottleneck을 발생시킬 수도 있다.) 반면 Transformer-style special-token readout method는 차후 layer에서 distill하기 전에 network가 long-range node-to-node relationships을 초기 layer에서 학습할 수 있게 한다.
Experiments
biology, computer programming, chemistry에 적용.
Adam, lr = 0.0001, weight decay = 0.0001, = default.
, feedforward subnetwork의 hidden dimension = 512
- Biology → NCI1, NCI109. compound가 폐암 항암 활동을 하는지 예측.
- Chemistry → NCI, OGB의 molpcba. 분자의 다양한 성질을 예측.
- Computer programming → OGB의 Code2. Abstract Syntax Tress (ASTs). AST로 표현되는 method body로부터 method name을 예측.
Transformers can capture long-range relationships
Transformer module이 정말 long-range relatioship을 잡아 내는지 실험.
Transformer module이 GNN module에서 추가적인 정보를 학습하는지 확인.
GNN을 Code2 dataset에 수렴할 때까지 pretrain, GNN model을 freeze, Transformer model을 넣음. 고정된 GNN module 위에서 model을 training 시켜서 validation, test set에서 성능 향상. GNN module 단일로 학습하지 못하는 추가적인 정보를 얻을 수 있음.
Pretraine하고 GNN을 unfreeze하면, GraphTrans는 더 높은 F1-Score를 달성함. 이는 아마 long-range information은 Transformer module이 잡아내고, GNN module이 local structure 정보에 더 집중할 수 있기 때문이다.
Effectiveness of <CLS> embedding
Figure 2b의 row 18 (<CLS>)를 보면 많은 columns에 진한 붉은 색이 있는데, 전체 graph의 representatin을 학습하는데 중요한 nodes를 의미한다.
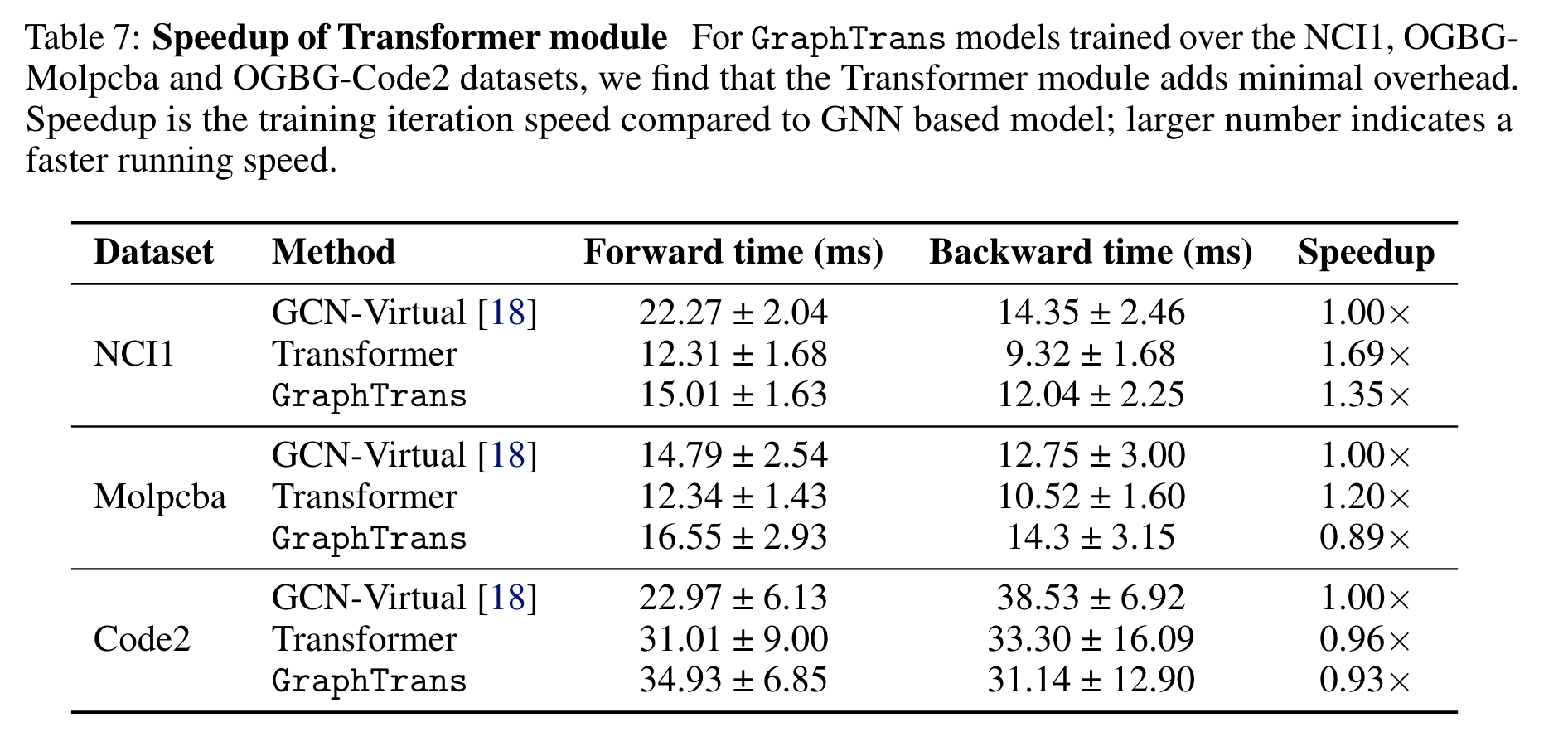
Computational efficiency
overhead는 얼마나 될까?
Conclusion
GraphTrans를 제안한다. 기존의 방법과 달리 일반적인 GNN 위에 Transformer module을 올린다. Transformer는 “readout” module로 작동하는데, graph nodes 사이의 pairwise interactions을 학습하면서 NLP Transformer에서 사용되는 special token embedding에 요약한다 (<CLS>). 훌륭한 성능을 보였다. 단순한 구조이기 때문에 long-range graph classification에 널리 사용될 수 있다. node와 edge classification에 대한 적용과 scalability improvements가 필요해 보인다.
References
On the Relationship between Self-Attention and Convolutional Layers
An Image is Worth 16x16 Words: Transformers for Image Recognition...
Relational inductive biases, deep learning, and graph networks
End-to-End Object Detection with Transformers
On the Relationship between Self-Attention and Convolutional Layers
