💡 데이터 변경 및 요약
◽ R reshape를 활용한 데이터 마트 개발
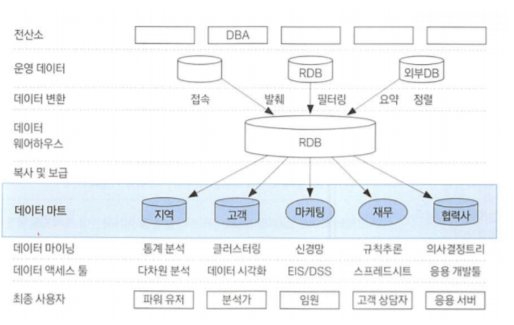
◾ 데이터 마트(Data Mart)
-
데이터 웨어하우스(DW)와 사용자 사이의 중간층에 위치 한 것으로, 하나의 주제 또는 부서 중심의 데이터 웨어하우스라고 할 수 있다.
-
대부분 DW로부터 복제, 그러나 자체 수집 가능 , 관계형 DB나 다차원 DB 이용하여 구축한다.
-
CRM 관련 업무 중 핵심이다.
-
데이터 마트의 구축 여부에 따라 분석효과 차이가 크다.
➡️ 최신 분석기법들을 사용하기에 분석가들 간 편차가 덜하기 때문이다.
◽ 요약변수(summary variables)
-
수집 된 정보를 분석에 맞게 종합(aggregation)한 변수이다.
-
많은 모델들이 공통으로 사용하기에 재활용성이 높다.
-
연속형 변수 를 범주화하여 사용해도 좋다.
-
합계, 횟수 같은 간단한 구조이므로 자동화하여 상황에 맞게 또는 일반적인 자동화 프로그램 으로 구축이 가능하다.
-
요약변수만으로도 세분화하거나 행동 예측을 하는데 큰 도움받을 수 있으나 기준값(threshold value)의 의미해석이 애매 할 수 있어서 연속형 변수를 자동으로 타깃에 맞춰 그루핑해주면 좋다.
-
마트를 만드는데 시간과 공간의 제약이 덜한 상황이라면 다양한 조합의 요약변수를 자동
으로 만드는 것이 적합하다.
◽ 파생변수(derived variables)
사용자(분석자)가 특정 조건을 만족하거나 특정 함수에 의해 값을 만들어 의미를 부여한 변수.
-
매우 주관적 일 수 있으므로 논리적 타당성을 갖추어 개발해야 한다.
-
파생변수는 특정 상황에만
유의미하지 않도록대표성 을 띄게 생성해야 한다. -
세분화, 고객행동 예측, 캠페인 반응 예측에 매우 잘 활용된다.
-
파생변수 자체로도 분석가능하나 이를 이용하면 데이터마이닝에 기여하는 바가 크다.
- 보다 많은 변수 를 잘 활용하는 것이 요즘 대세이다.
◽ reshape 활용
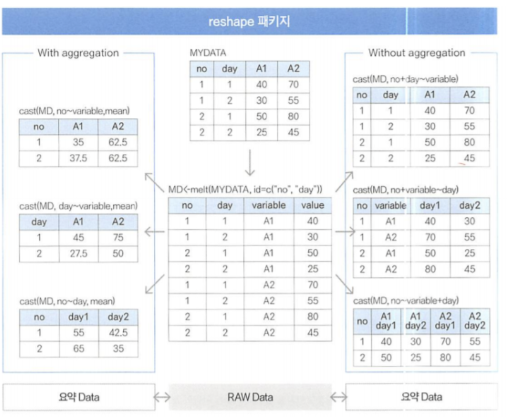
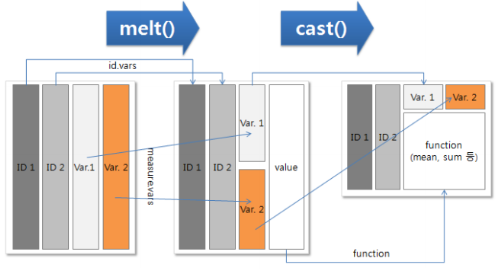
기존 거래 데이터(TR)구조를 column-wise 하게 전환하는데 크게 melt와 cast 단계로 구분
-
◾ melt()
melt( data , id , vars, na.rm = FALSE )
- 데이터를 원하는 방식대로 분석하기위해 식별자(ID), 측정변수(value)형태로 자료를 재구성하는 단계. 녹인다고 표현을 많이한다.
기준되는 변수를 제외한여러 Factor변수를 하나의 Dimension 변수와 하나의 Factor
변수로 변환하는 함수
- 데이터를 원하는 방식대로 분석하기위해 식별자(ID), 측정변수(value)형태로 자료를 재구성하는 단계. 녹인다고 표현을 많이한다.
-
◾ cast()
cast( data , id변수~variable변수, formula)
- melt로 녹인 데이터들을 분석자가 원하는 여러 형태의 column으로 변환하는 함수.
◽ sqldf를 이용한 데이터 분석
-
표준 SQL에서 사용되는 문장이 모두 가능하고 데이터 이름에 “.” 같은 특수문자가 들어간
경우 ‘ ’ 로 묶어주면 테이블처럼 간단히 처리 가능하다. -
R에서 sql 명령어 사용 패키지
sqldf("select * from [df] limit 10 where [col] like 'char%'")
head([df]) sqldf("select * from [df] limit 6") subset([df], grepl("qn%", [col])) sqldf("select * from [df] where [col] like 'qn%'") subset([df], [col] %in% c("BF","HF")) sqldf("select * from [df] where [col] in ('BF','HF')") rbind([df1], [df2]) sqldf("select * from [df1] union all select * from [df2]") merge([df1], [df2]) sqldf("select * from [df1], [df2]") df[order([df]$[col], decreasing=T),] sqldf("select * from [df] order by [col] desc")
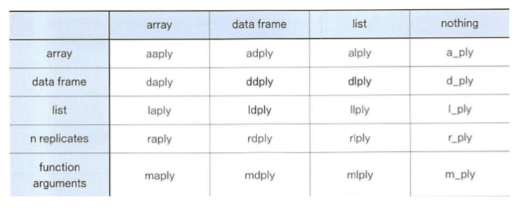
◽ plyr 활용
-
데이터를 분석하기 쉬운 형태로 분리 하고 처리한 다음 다시 결합해 새로운 형태로만들어 주는 가장 필수적인 데이터 처리기능 제공
-
데이터와 출력변수를 동시에 배열로 치환하여 처리하는 패키지
-
split - apply - combine : 데이터 분리하고 처리 후 다시 결합하는 필수적 데이터 처리기능 제공
-
apply 함수와 multi-core 사용 함수 이용하면
for loop사용하지 않고간단 하고 빠르게 처리 가능하다. -
ddply : plyr을 올리고 dataframe에서 dataframe으로 입출력 하는 함수
◽ data.table을 이용한 데이터 분석
-
큰 데이터를 탐색, 연산, 병합 하는 데 아주 유용하다.
-
기존 data frame 방식보다 월등히 빠른 속도
-
특정 column 을 key 값으로 색인을 지정한 후 데이터를 처리한다.
-
빠른 Grouping과 Ordering, 짧은 문장 지원 측면에서 데이터프레임보다 유용하다.
-
무조건 빠른 것이 아니므로특성에 맞게 사용해야 한다. -
데이터 테이블을 데이터프레임처럼 사용하면 성능은 비슷해진다.
◽ 데이터 가공
◾ Data Exploration
-
데이터 분석을 위해 구성된 데이터의 상태를 파악한다. head( ), summary( )
-
summary : 데이터가 어떻게 분포돼 있는지 보여준다.
-
디멘젼변수 : 각 멤버의 갯수, 결측치 개수(NA)
-
메져변수 : 최소값(Min), 1st Q(1사분위값), 중앙값(Median), 평균값(Mean), 3rd Q(3사분위값), 최대값(Max), 결측치 개수(NA)
-
plot : 차트
◾ 변수 중요도
-
모형을 생성하여 사용된 변수의 중요도를 살피는 과정이다.
-
개발 중인 모델에 준비된 데이터를 기준으로 한 번에 여러 개의 변수를 평가
-
klaR 패키지 : 특정 변수 주어졌을 때 클래스 분류 에러율 계산, 그래프로 결과 보여준다.
- greedy.wilks() : 세분화 위한 stepwise forward 변수선택
➡️ 효율적으로 정확도를 최소한 희생하면서 초기 모델링 빨리 실행 가능
- greedy.wilks() : 세분화 위한 stepwise forward 변수선택
-
wilk's lambda (집단 내 총분산) 활용하여 변수 중요도 정리
-
plineplot() 이용이 가능하다.
-
일반적으로 구간화 개수가 증가 하면 정확도는 높아지나 속도가 느려지고 추정오차(overestimation) 가 발생 가능하다.
-
기본적으로 40개정도를 구간화하고 이를 대상(target)과 비교해 유사한 성능 보이는 인접구간을 병합하는 것이 적합하다.
◾ 변수의 구간화
-
신용평가모형, 고객 세분화 등 시스템으로 모형을 적용하기 위해서는 각 변수들을 구간화해서 구간별로 점수를 적용할 수 있어야 한다.
-
bining: 연속형 변수 를 범주형 변수 로 변형하는 방식.
각각 동일한 개수의 레코드를 50개 이하의 구간에 데이터를 할당하여 구간들을 병합하면서 구간을 줄여나가는 방식의 구간화 방법이다.
-
의사결정나무 : 세분화 또는 예측에 활용되는 의사결정 모형을 사용하여 입력변수들을 구간화 할 수 있다.
동일한 변수를 여러번의 분리기준으로 사용 가능하기 때문에 연속변수가 반복적 으로 선택될 경우, 각각의 분리 기준값 으로 연속형 변수 를 구간화 할 수 있다.
💡기초분석 및 데이터 관리
◽ 데이터 EDA(Exploratary Data Analysis: 탐색적 데이터 분석)
- 데이터 분석에 앞서 전체적으로 데이터의 특징을 파악하고 데이터를 다양한 각도로 접근한다.
◽ 결측값(Missing value)

NA, 999999, '(공백)', Unknown, NotAnswer등으로 표현 결측값 처리를 위해 시간을 많이 사용하는 것은 비효율적 이다.
-
결측값 자체가 의미있는 경우도 있다.
-
결측값이나 이상값을
꼭 제거해야 하는 것은 아니기때문에 분석의 목적이나 종류에 따라 적절한 판단 이 필요하다.
◽ 결측값 처리 방법

◾ 1) 단순 대치법 (Single Imputation)
- complete analysis : 결측값이 존재하는 레코드를
삭제 해 버린다 ➡️ 데이터수가 줄어들어 효율성이 떨어진다.
◾ 2) 평균 대치법 (Mean Imputation)
-
관측 또는 실험을 통해 얻어진 데이터의 평균 으로 대치
-
비조건부 평균 대치법: 관측데이터의 평균 으로 대치
-
조건부 평균 대치법: 회귀분석 을 활용한 대치법
◾ 3) 단순확률 대치법(Single Stochastic Imputation)
-
평균 대치법에서 추정량 표준 오차의 과소문제 를 보완하고자 고완된 방법. Hot-deck 방법, nearest neighbor 방법 이 있다.
-
Hot-deck 방법: 관련된 비슷한 데이터 셋에서 랜덤 하게 선택한다.
-
nearest neighbor 방법: 최근접 이웃법 , 가장 가까운 데이터를 중심으로 종류를 정해주는 알고리즘
◾ 4) 다중 대치법(Multiple Imputation)
단순 대치법을 한번 하지 않고 m번의 대치를 통해 m개의 가상적 완전자료를 만드는 방법.
- 대치(Imptation Step) ➡️ 분석(Analysis Step) ➡️결합(Combination Step)의 3단계를 거친다.
◽ R에서 결측값 처리
랜덤포레스트는 결측값이 존재할 경우, 에러 발생: randomForest 패키지의 rfImpute() 함수를 활용하여 결측값을 대치 한 후 알고리즘에 적용한다.
|
complete.cases() |
데이터 내 레코드에 결측값이 있으면 FALSE , 없으면 TRUE 반환 |
|
is.na() |
결측값 이 NA인지 여부를 반환 |
|
DMwR::centralImputation() |
NA 값에 가운데 값(central value)으로 대치 |
|
DMwR::knnImputation() |
NA 값을 knn 알고리즘을 사용하여 대치. |
◽ 이상값(Outlier)
-
의도하지 않게 잘못 입력 한 경우
-
의도하지 않게 입력되었으나 분석 목적에 부합되지 않아 제거 해야 하는 경우
-
의도하지 않은현상이지만 분석에 포함해야 하는 경우 -
의도된 불량(fraud) 인 경우
-
분석에서 전처리를 어떻게 할지 결정할 때와 부정사용방지 시스템(Fraud Detection) 에서 규칙을 발견하는데 사용한다.
-
좀 더 시간되면 주요 dimension별로 플롯해보며 특성파악 가능하다.
◽ 이상값 탐지(detection)
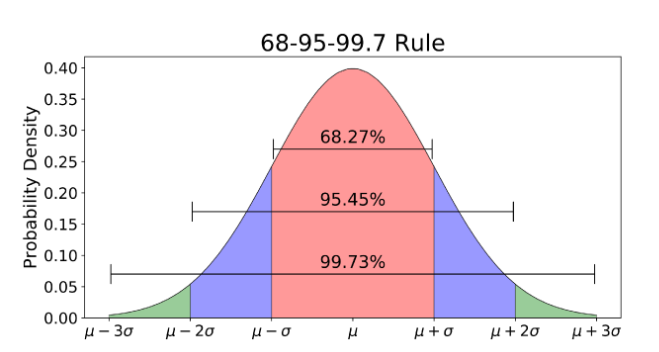
- ESD(Extreme Studentized Deviation): 평균으로부터 3 표준편차 떨어진 값
기하평균 - 2.5 표준편차 < data < 기하평균 + 2.5 표준편차
-1.5 IQR(Q3-Q1) < data < 1.5 IQR
위의 범위를 벗어나는 데이터는 이상치 로 인식한다.
- 변수들에 대해 summary 정도로 mean과 median값 파악해 Q1, Q3보고 1차 판단(분포)
◽ 극단값 절단(trimming)
-
기하평균을 이용한 제거
-
상, 하위 5%에 해당되는 데이터 제거
◽ 극단값 조정(winsorizing)
- 상한값과 하한값을 벗어나는 값들을 상한 , 하한값 으로 바꾸어 활용하는 방법
본 게시물에 포함된 내용은 한국데이터산업진흥원에서 발행한]
[데이터 분석 전문가 가이드,medium.com,0utlier.tistory.com/41,2019년 2월 8일 개정]에 근거한 것임을 밝힙니다.