💡 데이터 마이닝의 개요
Data mining은 대용량 데이터에서 의미있는 데이터 패턴 을 파악하거나 예측하여 의사결정에 활용하는 방법이다.
-
거대한 양의 데이터 속에서 쉽게 드러나지 않는 유용한 정보를 찾아내는 과정
-
기업이 보유한 고객, 거래, 상품데이터 등과 이외의 기타 외부 데이터를 기반으로 감춰진 지식, 새로운 규칙 등을 발견하고 이를 비즈니스 의사결정 등에 활용하는 일련의 작업
◽ 통계분석과의 차이점
-
통계분석은 가설이나 가정에 따른 분석이나 검증을 하지만 데이터마이닝은 다양한 수리 알고리즘 을 이용해 데이터베이스의 데이터로부터 의미있는 정보를 찾아내는 방법으로 통칭한다.
-
가설이나 가정에 따른 분석이나 검증, 통계학 전문가가 사용하는
도구도 아니다.
◽ 데이터마이닝의 종류
◾ 정보를 찾는 방법론에 따른 종류
인공지능(Artificial Intelligence), 의사결정나무(Decision Tree), K-평균군집합(K-means Clustering), 연관분석(Association Rule), 회귀분석(Regression), 로짓분석(Logit Analysis), 최근접이웃(Nearest Neighborhood)
◾ 분석대상, 활용목적, 표현방법에 따른 분류
시각화분석(Visualization Analysis), 분류(Classification), 군집화(Clustering), 포케스팅(Forecasting)
◽ 사용분야
-
병원에서 환자 데이터를 이용해서 해당 환자에게 발생 가능성이 높은 병을 예측
-
기존 환자가 응급실에 왔을 때 어떤 조치를 먼저 해야 하는지를 결정
-
고객 데이터를 이용해 해당 고객의 우량/불량을 예측해 대출적격 여부 판단
-
세관 검사에서 입국자의 이력과 데이터를 이용해 관세물품 반입 여부를 예측
◽ 데이터마이닝의 최근 환경
- 데이터마이닝 도구가 매우 다양하고 체계화돼있어 도입환경에 적합한 제품을 선택,활용가능하다.
-
알고리즘에 대한 깊은
이해가 없어도분석에큰 어려움이 없다. -
데이터 마이닝을 통한 분석 결과의 품질은 분석가의 경험 과 역량 에 따라 차이나기 때문에 때문에 분석 과제의 복잡성이나 중요도가 높으면 풍부한 경험 을 가진 전문가에게 의뢰할 필요가 있다.
-
국내에서 데이터마이닝 적용된 시기는 1990년대 중반이다.
-
2000년대에 비즈니스 관점에서 데이터마이닝이 CRM의 중요한 요소로 부각되었다.
-
대중화를 위해 많은 시도가 있었으나, 통계학 전문가와 대기업 위주로 진행되었다.
◽ 데이터 마이닝 추진 단계
| 1단계. 목적 정의 | 데이터 마이닝의 명확한 목적 설정 무엇을 왜 하는지 목적 설정 |
| 2단계. 데이터 준비 | 데이터 정제, 데이터 양을 충분히 확보 |
| 3단계. 데이터 가공 | 목적변수를 정의하고 개발환경 구축, 모델링을 위한 데이터 형식으로 가공 |
| 4단계. 데이터 마이닝 기법 적용 | 모델을 목적에 맞게 선택 기법을 적용하여 정보를 추출 |
| 5단계. 검증 | 결과에 대한 검증 |
■1단계 : 목적 설정
-
도입 목적을 분명히. 데이터마이닝을 통해 무엇을 왜 하는지 명확한 목적 설정
-
목적 정의 단계부터 시작, 목적은 이해 관계자 모두가 동의하고 이해 가능하다.
-
가능하면 1단계부터 전문가가 참여해 목적에 따라 사용할 데이터 마이닝 모델 과 필요데이터를 정의하는 것이 바람직하다.
-
■ 2단계 : 데이터 준비
-
데이터 정제를 통해 데이터의 품질을 보장하고 필요하다면 보강해 데이터의 양을 충분히 확보해 데이터 마이닝 기법을 적용하는데
문제없도록 해야 한다.- 고객정보, 거래정보, 상품 마스터 정보 등 필요. 웹로그 데이터, SNS데이터도 활용 가능하다.
- 필요하면 데이터를 다른 서버에 저장 운영
■ 3단계 : 가공
-
모델링 목적에 따라 목적변수를 정의하고 필요한 데이터를 데이터마이닝 sw에 적용할 수 있도록 적합한 형식으로 가공해야 한다.
- 모델 개발단계에서 데이터 읽기, 데이터 마이닝에 부하 걸림 ➡️ 모델링 일정계획을 팀원 간
잘 조정해야한다.
- 모델 개발단계에서 데이터 읽기, 데이터 마이닝에 부하 걸림 ➡️ 모델링 일정계획을 팀원 간
■ 4단계 : 기법 적용
-
앞 단계를 거쳐 준비한 데이터와 데이터 마이닝 sw를 활용해 목적하는 정보 추출
- 적용할 데이터 마이닝 기법은 1단계에서 이미 결정됐어야 바람직하다.
- 적용할 데이터 마이닝 기법은 1단계에서 이미 결정됐어야 바람직하다.
-
데이터 마이닝 모델을 목적에 맞게 선택하고 sw사용하는데 필요한 값을 지정한다.
- 어떤 기법을 활용하고 어떤 값을 입력하느냐 등은 데이터 분석가의 전문성에 따라 다르다.
- 데이터 마이닝 적용 목적, 보유 데이터, 산출되는 정보 등에 따라 적절한 sw와 기법 선정
■ 5단계 : 검증
-
마이닝으로 추출한 정보를 검증하는 단계
-
테스트 마케팅이나 과거 데이터 활용 가능하다.
-
-
검증됐으면 자동화 방안을 IT부서와 협의해 상시 데이터 마이닝 결과를 업무에 적용할 수
있게 해야 하며 보고서를 작성해 경영진에게 기대효과를 알릴 수 있어야 한다.
◽ 데이터 마이닝의 기능
◾ 분류(Classification)
-
새롭게 나타난 현상을 검토하여 기존의 분류 , 정의된 집합 에 배정하는 것
-
잘 정의된 분류기준과 선분류되어진 검증 집합이 필요하다.
-
기법 : 의사결정나무, memory-based reasoning, link analysis 등
◾ 추정(Estimation)
-
'수입, 수준, 신용카드 잔고' 등 연속된 변수의 값을 추정 하는 것
-
주어진 데이터를 활용해
알려지지 않은결과값을 추정한다 -
기법 : 신경망 모형
◾ 예측(Prediction)
-
분류와 추정과 유사하지만, 미래의 값 이라는 차이가 있다.
-
예측 작업의 정확성을 알아보는 방법은 기다리고 지켜보는 것 뿐이다.
-
기법 : 장바구니 분석, memory-based reasoning, 의사결정나무, 신경망 등이 모두 사용될 수 있다.
(입력 데이터의 성격에 따라 기술의 사용이 결정된다)
◾ 연관 분석(Association Analysis)
-
'같이 팔리는 물건'과 같이 아이템의 연관성을 파악하는 분석
-
기법 : 장바구니 분석
◾ 군집(Clustering)
-
모집단을 동질성 을 지닌 그룹으로 세분화 하는 것
-
선분류 되어있는 기준에
의존하지 않는다는 점이 분류와의 차이 -
레코드 자체가 지니고 있는 다른 레코드와의 유사성 에 의해 그룹화 되고, 이질성에 의해 세분화 된다.
-
주로 데이터 마이닝이나 모델링의 준비단계로서 사용된다.
◾ 기술(Description)
-
데이터가 가지고 있는 의미를 단순하게 기술하여, 의미를 파악할 수 있도록 함
-
데이터가 암시하는 바에 대해 설명이 가능해야 하며, 설명에 대한 답을 찾아낼 수 있어야 한다.
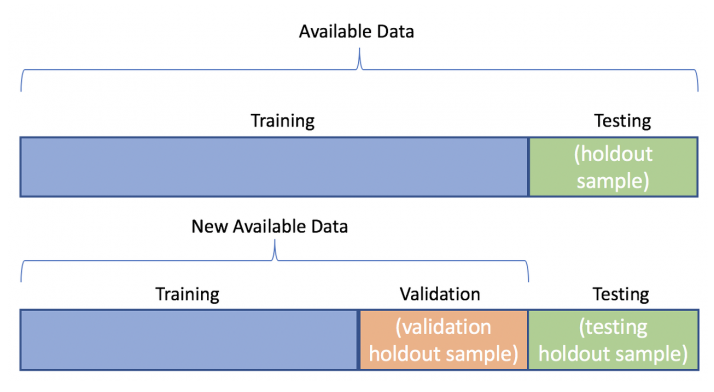
◽ 데이터마이닝을 위한 데이터 분할
모델 평가용 테스터 데이터 와 구축용 데이터 로 분할하여, 구축용 데이터로 모형을 생성하고, 테스트 데이터로 모형이 얼마나 적합한지를 판단한다.
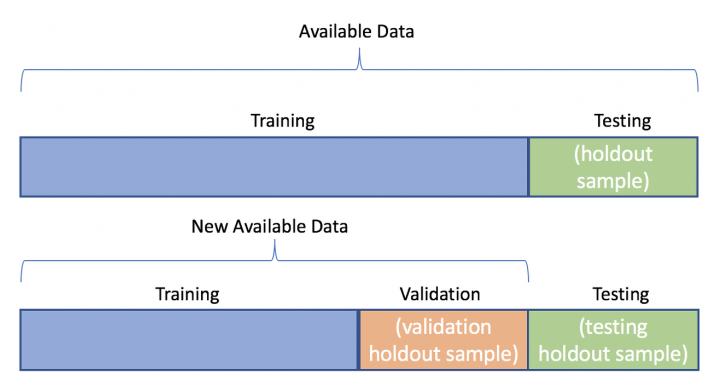
◾ 1) 구축용(training data 50%)모형 생성
추정용, 훈련용 데이터라고 불리며 데이터 마이닝 모델을 만드는데 활용한다.
◾ 2) 검정용(validation data, 30%)
구축된 모형의 과대추정 또는 과소추정 을 미세 조정을 하는데 활용한다.
◾ 3) 시험용(test data, 20%)모형 적합도 판단
테스트 데이터나 과거 데이터를 활용하여 모델의 성능을 검증하는데 활용한다.
◾ 4) 데이터의 양이 충분하지 않거나 입력 변수에 대한 설명이 충분한 경우
- 홀드아웃(hold-out)방법 : 주어진 데이터를 랜덤하게 두 개의 데이터로 구분하여 사용하는 방법으로 주로 학습용(training data) 과 시험용(test data) 로 분리하여 사용한다.
- 교차확인(cross-validation)방법: 주어진 데이터를 k개의 하부집단으로 구분하여 K-1개의 집단을 학습용(training data) 으로 나머지는 하부집단으로 검증용으로 설정하여 학습한다.
k번 반복 측정한 결과를 평균낸 값을 최종값 으로 사용한다. 주로 10-fold 교차분석 을 많이 사용한다.
💡 성과분석
◽ 오분류 추정치
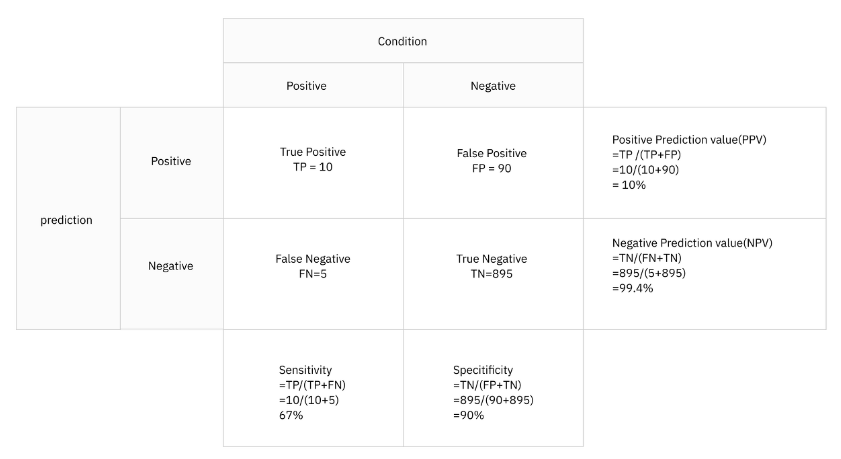
- 오분류에 대한 추정치 : 정분류율, 오분류율, 특이도, 민감도, 정확도, 재현율, F1 Score
매트릭
|
계산식
|
의미
|
Precision
정확도
|
TP / (TP + FP)
|
Y로 예측된 것 중 실제로도 Y인 비율
|
Accuracy
정분류율
|
TP + TN / (TP + FP + FN + TN)
|
전체 예측에서 옳은 예측의 비율
|
Recall(Sensitivity)
재현율(민감도)
|
TP/ (TP + FN)
|
실제로 Y인 것들 중 예측이 Y로 된 경우의 비율
|
Specificity
특이도
|
TN / (FP + TN)
|
실제로 N인 것들 중 예측이 N으로 된 경우의 비율
|
FP Rate
|
FP / (FP + TN)
|
Y가 아닌데 Y로 예측된 비율
= 1 - Specificity
|
F1
|
2 × Precision × Recall
/
(Precision + Recall)
|
Precision과 Recall의 조화평균.
시스템의 성능을 하나의 수치로 표현하는 점수
0 ~ 1 사이의 값을 가짐
|
Kappa
|
Accuracy - P(e) / (1 - P(e))
|
두 평가자의 평가가 얼마나 일치하는지 평가하는 값
0 ~ 1 사이의 값을 가짐
|
◽ ROCR 패키지로 성과분석
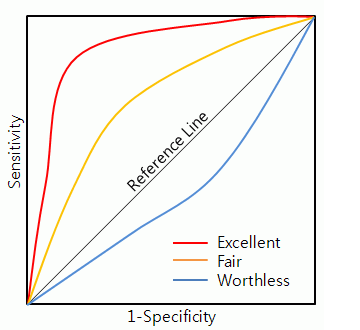
◾ Roc Curve( Reciver Operating Caracteristic curve) 수신기 작동 특성
-
가로축을 FPR(Flase Positive Rate=1-특이도) 값으로 두고, 세로축을 TPR(True Positive Rate=민감도) 값으로 두어 시각화한 그래프이다.
-
2진 분류(Binary classification)에서 모형의 성능을 평가하기 위해 많이 사용되고 있는 척도 이다.
-
그래프가 왼쪽 상단에 가깝게 그려질수록 올바르게 예측한 비율이 높고, 잘못 예측한 비율 은 낮음 을 의미한다.
-
ROC 곡선 아래에 면적을 의미하는 AUROC(Area Under Reciver Operating Caracteristic) 값이 크면 클수록 (1에 가까울수록) 모형의 성능이 좋다고 판단한다.
-
TPR(True Positive Rate , 민감도) 1인 케이스 에 대한 1로 예측 한 비율
-
FPR(False Positive Rate, 1-특이도) 0케이스에 대한 1로 잘못 예측 한 비율
◾ AUROC(Area Under Receiver Operating Curve) 를 이용한 정확도의 판단 기준
| 기준 | 구분 |
| 0.9~1.0 | Ecellent (A) |
| 0.8~0.9 | good |
| 0.7~0.8 | fair |
| 0.6~0.7 | Poor |
| 0.5~0.6 | fail |
◽ 이익도표
-
이익도표는 분류모형의 성능을 평가하기 위한 척도로, 분류된 관측치에 대해 얼마나 예측이 잘 이루어졌는지 를 나타내기 위해 임의로 나눈 각 등급별로 반응검출율, 반응률, 리프트 등의 정보를 산출하여 나타내는 도표이다.
-
이익도표의 각 등급은 예측확률에 따라 매겨진 순위이기 때문에, 상위 등급 에서는 더 높은 반응률을 보이는 것이 좋은 모형이라고 평가할 수 있다.
본 게시물에 포함된 내용은 한국데이터산업진흥원에서 발행한]
[데이터 분석 전문가 가이드, 2019년 2월 8일 개정]에 근거한 것임을 밝힙니다.