💡분류 (Classification)
분류란❓
새롭게 나타난 현상을 검토, 기존의 분류, 정의된 집합에 배정하는 것
즉 객체를 정해놓은 범주로 분류하는데 목적이 있다.
-
분류기준과 선분류(preclassified)되어진 검증 집합에 의해 완성
-
의사결정나무(decision tree), memory-based reasoning
-
link analysis에 사용한다.
-
CRM에서는 고객행동예측, 속성파악에 응용. 다양한 분야에서 활용 가능한다.
◽ 분류분석(Classification Analysis)
-
데이터가 어떤 그룹에 속하는지 예측하는데 사용되는 기법이다.
-
클러스터링과 유사하지만, 분류분석은 각 그룹이 정의되어 있다.
-
교사학습(supervised learning)에 해당하는 예측기법이다.
-
특정 등급으로 나누는 점에서 군집분석과 유사하나 각 계급이 어떻게 정의되는지 미리 알아야 한다.
◽ 분류를 위해 사용되는 데이터마이닝 기법
-
회귀분석, 로지스틱 회귀분석 (Logistic Regression)
-
의사결정나무 (Decision Tree), CART(Classification and Regression Tree), C5.0
-
베이지안 분류 (Bayesian Classification), Naive Bayesian
-
인공신경망 (ANN, Artificial Neural Network)
-
지지도벡터기계 (SVN, Support Vector Machine)
-
K 최근접 이웃 (KNN, K-Nearest Neighborhood)
-
규칙기반의 분류와 사례기반추론(Case-Based Reasoning)
💡예측분석
-
시계열분석처럼 시간에 따른 값 두 개만을 이용해 앞으로의 매출 또는 온도 등을 예측하는 것
-
모델링을 하는 입력 데이터가 어떤 것인지에 따라 특성이 다르다.
-
여러 개의 다양한
설명변수(독립변수)가 아닌, 한 개의 설명변수로 생각하면 된다.
◽ 분류분석, 예측분석의 공통점과 차이점
◾ 공통점
- 레코드의 특정 속성의 값을 미리 알아맞히는 점이다.
◾ 차이점
-
분류 : 레코드(튜플)의 범주형 속성의 값을 알아맞히는 것이다.
-
예측 : 레코드(튜플)의 연속형 속성의 값을 알아맞히는 것이다.
◽ 분류, 예측의 예
◾ 분류
-
1. 학생들의 국어, 영어, 수학 점수를 통해 내신등급을 알아맞히는 것
-
2. 카드회사에서 회원들의 가입 정보를 통해 1년 후 신용등급을 알아맞히는 것
◾예측
-
1. 학생들의 여러 가지 정보를 입력하여 수능점수를 알아맞히는 것
-
2. 카드회사 회원들의 가입정보를 통해 연 매출액을 알아맞히는 것
◽ 의사결정나무
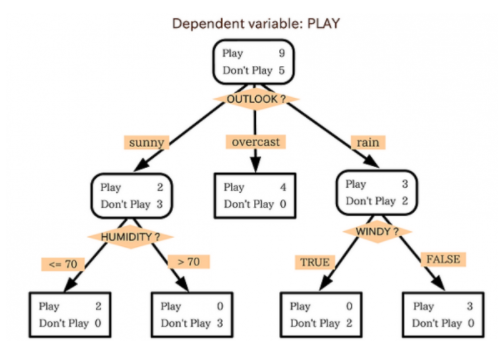
-
의사결정나무는 분류함수를 의사결정 규칙으로 이뤄진 나무 모양으로 그리는 방법이다.
-
나무구조는 연속적으로 발생하는 의사결정 문제를 시각화해 의사결정이 이뤄지는 시점과 성과를 한눈에 볼 수 있게 한다.
-
계산결과가 의사결정나무에 직접 나타나기 때문에 해석이 간편하다.
-
의사결정나무는 주어진 입력 값에 대하여 출력 값을 예측하는 모형으로 분류나무와 회귀나무 모형이 있다.
-
분류변수와 분류기준값의 선택이 중요하다.
◽ 의사결정나무의 활용
◾ 세분화
- 데이터를 비슷한 특성을 갖는 몇 개의 그룹으로 분할해 그룹별 특성을 발견하는 것이다.
◾분류
- 여러 예측변수들에 근거해 관측개체의 목표변수 범주를 몇 개의 등급으로 분류하고자 하는 경우에 사용하는 기법이다.
◾ 예측
- 자료에서 규칙을 찾아내고 이를 이용해 미래의 사건을 예측하고자 하는 경우이다.
◾차원축소 및 변수선택
- 매우 많은 수의 예측변수 중에서 목표변수에 큰 영향을 미치는 변수들을 골라내고자 하는 경우에 사용하는 기법이다.
◾ 교호작용효과의 파악
-
여러 개의 예측변수들을 결합해 목표변수에 작용하는 규칙을 파악하고자 하는 경우이다.
-
범주의 병합 or 연속형 변수의 이산화 : 범주형 목표변수의 범주를 소수의 몇 개로 병합하거나 연속형 목표변수를 몇 개의 등급으로 이산화 하고자 하는 경우이다.
◽ 의사결정나무의 예측력과 해석력
-
기대 집단의 사람들 중 가장 많은 반응을 보일 고객의 유치방안을 예측하고자 하는 경우에는 예측력에 치중한다.
-
신용평가에서는 심사 결과 부적격 판정이 나온 경우 고객에게 부적격 이유를 설명해야하므로 해석력에 치중한다.
◽ 의사결정나무의 특징
◾ 장점
-
결과를 누구에게나 설명하기 용이하다.
-
모형을 만드는 방법이 계산적으로
복잡하지 않다. -
대용량 데이터에서도 빠르게 만들 수 있다.
-
비정상 잡음 데이터에 대해서도
민감함이 없이분류할 수 있다. -
한 변수와 상관성 이 높은 다른 불필요한 변수가 있어도
크게 영향을 받지 않는다. -
설명변수나 목표변수에 수치형변수와 범주형변수를 모두 사용 가능하다.
-
모형 분류 정확도가 높다.
◾ 단점
-
새로운 자료에 대한 과대적합이 발생할 가능성이 높다.
-
분류 경계선 부근의 자료값에 대해서 오차가 크다.
-
설명변수 간의 중요도를 판단하기 쉽지 않다.
◽ 의사결정나무의 분석 과정
1) 성장 단계
- 각 마디에서 적절한 최적의 분류규칙(splitting rule)을 찾아서 나무를 성장시키는 과정으로 적절한 정지규칙(stopping rule)을 만족하면 중단한다.
2) 가지치기 단계
- 오차를 크게 할 위험이 높거나 부적절한 추론규칙을 가지고 있는 가지 또는 불필요한 가지를 제거하는 단계이다.
3) 타당성 평가 단계
- 이익도표(gain chart), 위험도표(risk chart), 혹은 시험자료를 이용하여 의사결정나무를 평가하는 단계이다.
4) 해석 및 예측 단계
- 구축된 나무모형을 해석하고 예측모형을 설정한 후 예측에 적용하는 단계이다.
✅ 나무의 가지치기(Pruning)
- 너무 큰 나무모형은 자료를 과대적합하고 너무 작은 나무모형은 과소적합할 위험이 있다.
- 나무의 크기를 모형의 복잡도로 볼 수 있으며 최적의 나무 크기는 자료로부터 추정하게 된다.
일반적으로 사용되는 방법은 마디에 속하는 자료가 일정 수(가령 5)이하일 때 분할을 정지하고 비용-복잡도 가지치기(cost complexity pruning)를 이용하여 성장시킨 나무를 가지치기하게 된다.
◽ 의사결정나무 알고리즘
◾CART (Classification and Regression Tree)
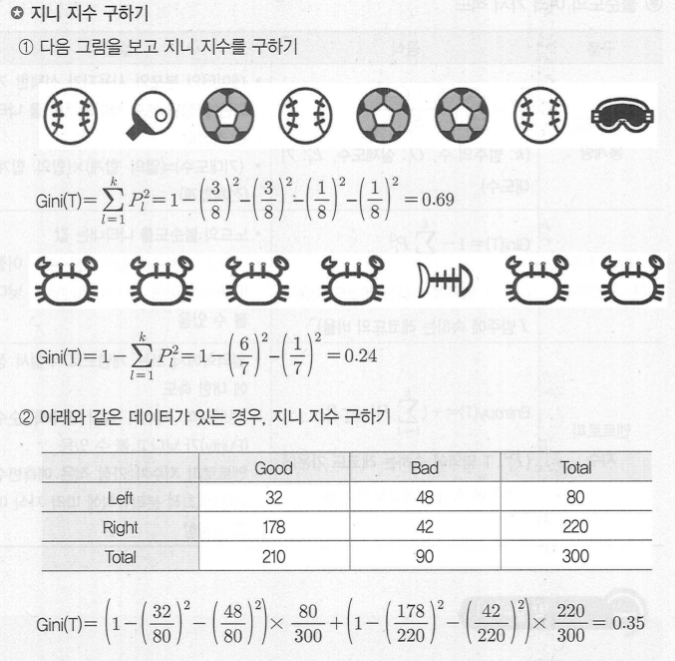
-
앞에서 설명한 방식의 가장 많이 활용되는 의사결정나무 알고리즘으로 불순도의 측도로 출력(목적) 변수가 범주형일 경우 지니지수를 이용, 연속형인 경우 분산을 이용한 이진분리(binary split) 를 사용한다.
-
개별 입력변수 뿐만 아니라 입력변수들의 선형결합들 중에서 최적의 분리를 찾을 수 있다.
◾ C4.5와 C5.0
-
CART와는 다르게 각 마디에서 다지분리(multiple split)가 가능하며 범주형 입력변수에 대해서는 범주의 수만큼 분리가 일어난다.
-
불순도의 측도로는 엔트로피지수를 사용한다.
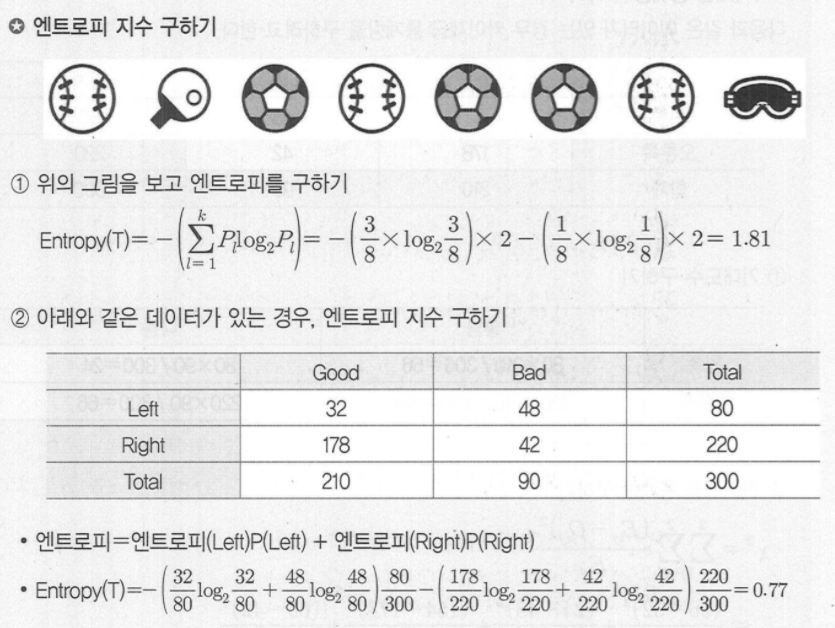
◾CHAID (CHI-squared Automatic Interaction Detection)
-
가지치기를 하지 않고적당한 크기에서 나무모형의 성장을 중지하며 입력변수가 반드시 범주형 변수이어야 한다. -
불순도의 측도로는 카이제곱 통계량을 사용한다.
본 게시물에 포함된 내용은 한국데이터산업진흥원에서 발행한]
[데이터 분석 전문가 가이드, 2019년 2월 8일 개정,]에 근거한 것임을 밝힙니다.