Ensemble(앙상블)의 정의
약한 분류기들을 결합하여 강 분류기로 만드는 것
즉, 앙상블(Ensemble)은 다수의 예측 모델을 조합하여 보다 정확한 예측을 하기 위한 기법입니다.
여러 개의 모델을 합치면 개별 모델보다 더욱 강력한 예측 모델을 만들 수 있습니다.
앙상블 방법에는 대표적으로 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking) 등이 있습니다.
Ensemble의 종류
1. 배깅(Bagging) : Bootstrap + Aggregation
즉, 약한 분류기들을 결합하여 강 분류기로 만드는 것
-> 무작위 복원 추출(Bootstrap)과 집계(Aggregation)를 결합하여 강한 분류기를 만드는 앙상블 기법
-> 약한 분류기(Weak Learner)들을 병렬적으로 학습시키고, 각 분류기들이 예측한 결과를 집계하여 최종 예측 결과를 도출
-> 대표적으로 랜덤 포레스트(Random Forest)가 있습니다
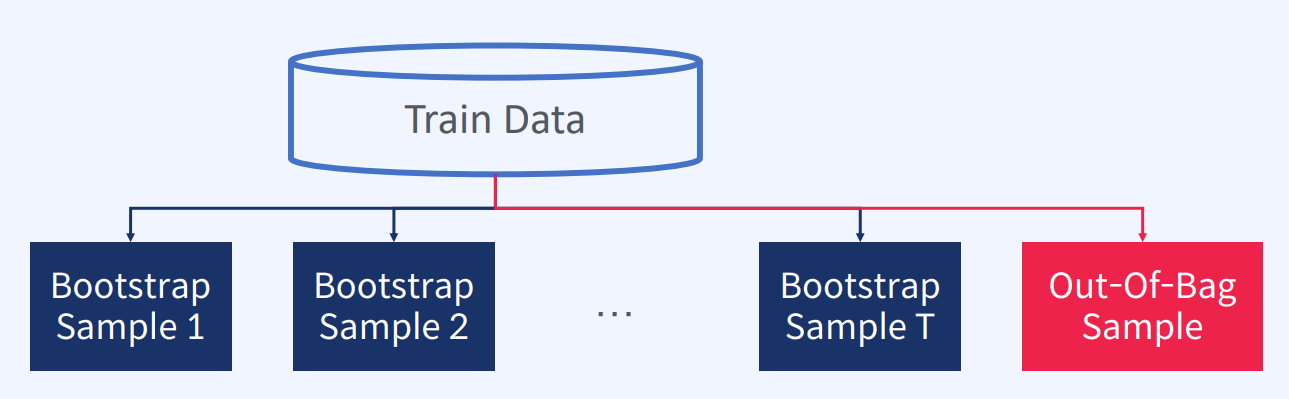
Bootstrap
1) Train Data 에서 여러 번 복원 추출하는 Random Sampling 기법
2) 추출된 샘플들을 부트스트랩 샘플이라고 부른다 -> 이렇게 추출된 샘플들을 이용하여 다수의 약한 분류기를 학습시킨다.
3) 이론적으로 36.8% 의 샘플이 뽑히지 않게 됨 (Out-Of-Bag 샘플)
참고로, OOB (Out-Of-Bag) 평가란?
-> 추출되지 않는 샘플(Out-Of-Bag(OOB) 샘플)을 이용해 Cross Validation(교차 검증)에서 Valid 데이터로 사용할 수 있다
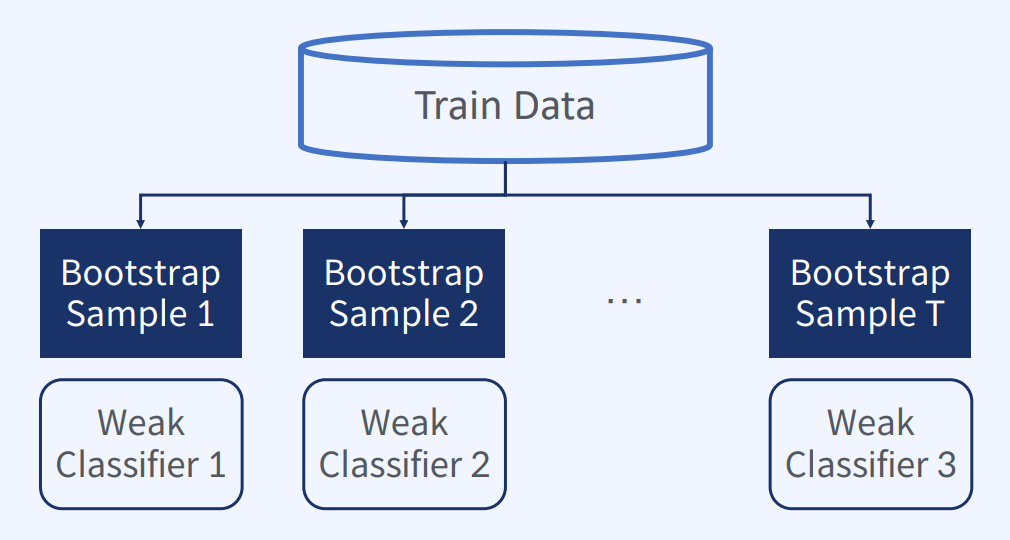
즉, 추출된 부트스트랩 샘플마다 약분류기를 학습한다. (약분류기 생성)
그 후, 생성된 약 분류기들의 예측 결과를 Voting을 통해 결합한다. (Aggregation)
이 방법을 Aggregation이라 한다!
정리하면,
약한 분류기들을 학습시키고 나서, 이들이 생성한 예측 결과를 집계(Aggregation)하는 과정이 필요합니다. 이를 위해 보통 다수결(Voting) 방식을 사용합니다. 다수결 방식은 여러 개의 분류기들이 예측한 결과 중 가장 많은 표를 얻은 클래스를 최종 예측 결과로 선택하는 방법입니다.
예를 들어, 만약 5개의 분류기가 예측한 결과가 각각 A, A, B, A, B라면 다수결 방식에 따라 클래스 A를 최종 예측 결과로 선택합니다. 이렇게 다수결 방식으로 여러 개의 분류기들이 생성한 예측 결과를 결합하여 최종 예측 결과를 도출합니다.
- Voting의 종류
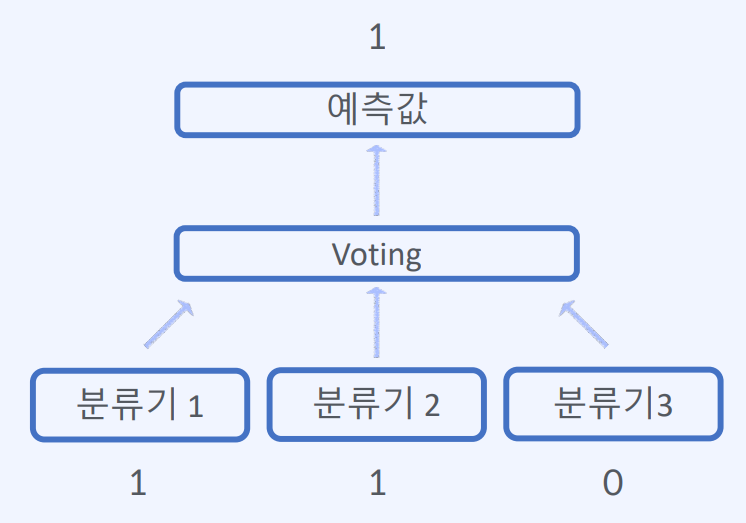
1) Hard Voting : 예측한 결과값 중 다수의 분류기가 결정한 값을 최종 예측값으로 선정
즉, 분류기들이 예측한 결과값 중 다수의 분류기가 결정한 값을 최종 예측값으로 선택
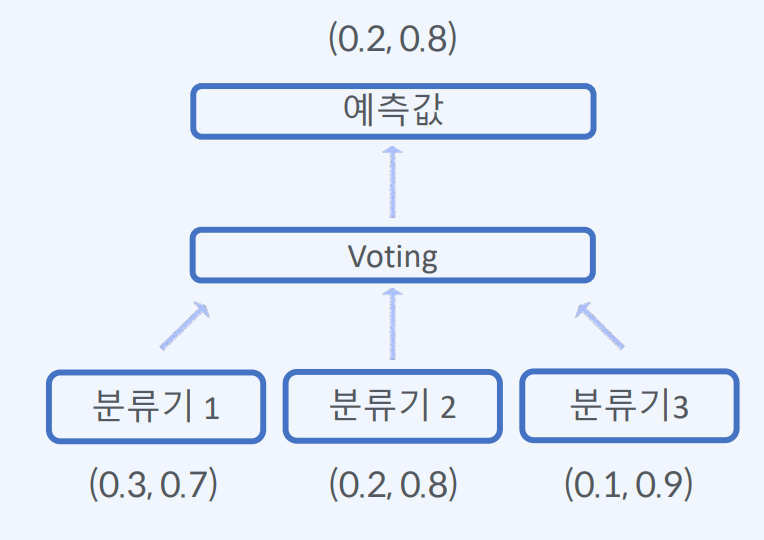
2) Soft Voting : 분류기가 예측한 확률 값의 평균으로 결정
즉, 분류기들이 예측한 클래스별 확률 값을 평균내어, 가장 높은 확률 값을 가진 클래스를 최종 예측값으로 선정하는 방법
예를 들어, 분류기 A, B, C가 예측한 클래스 A, B, A의 확률값이 각각 0.9, 0.7, 0.8이라면, 각 클래스별 확률 값을 평균내어 클래스 A가 가장 높은 평균 확률 값을 가지므로 최종 예측값으로 선택합니다.
참고로, Bagging의 장점!
- 분산을 줄이는 효과가 있음
- 원래 추정 모델이 불안정하면 분산 감소 효과를 얻을 수 있다!
- 과대 적합이 심한(High Variance) 모델에 적합
대표적인 예) Random Fores
- Decision Tree + Bagging
- 분산이 큰 Decision Tree + 분산을 줄일 수 있는 Bagging

Random Forest와 무작위성(Randomness)
- 무작위성을 더 강조하여서 의사결정나무들이 서로 조금씩 다른 특성을 갖음
- 변수가 20개가 있다면 5개의 변수만 선택해서 의사결정나무를 생성
- 의사결정나무의 예측들이 비상관화되어 일반화 성능을 향상시킨다 -> Overfitting이 될 가능성이 줄어든다!
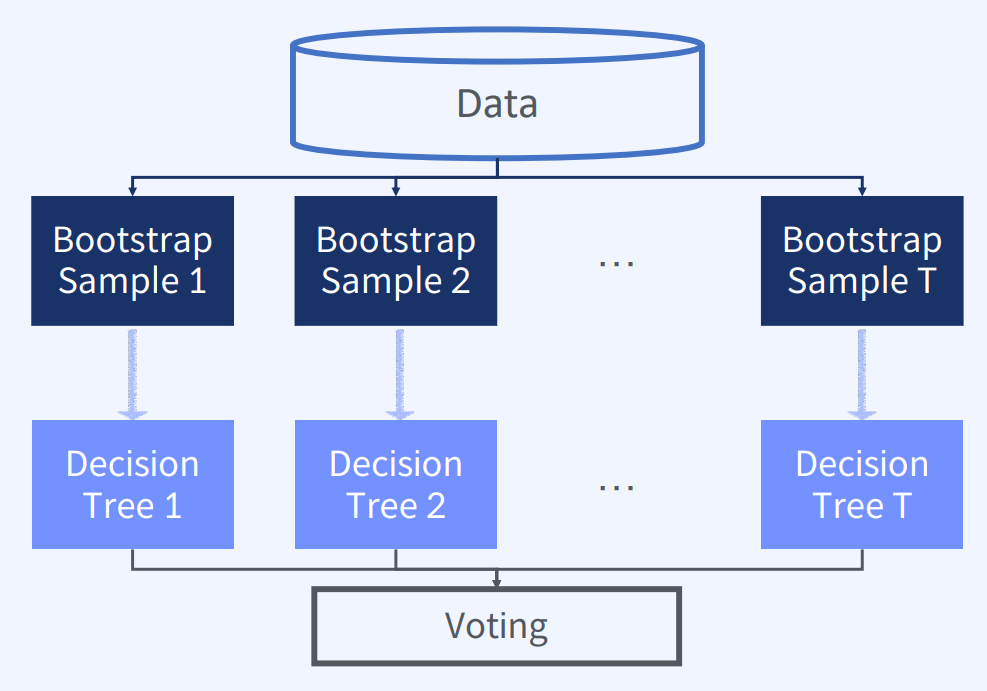
Random Forest 학습 방법
1. Bootstrap 방법으로 T 개의 부트스트랩 샘플을 생성한다.
2. T개의 의사결정나무들을 만든다.
3. 의사결정나무 분류기들을 하나의 분류기로 결합한다.
1. Random Forest 장점
- 의사결정나무의 단점인 Overfitting을 해결한다.
- 노이즈 데이터에 영향을 크게 받지 않는다.
- 의사결정나무 모델보다 복잡도가 적다.'
2. Random Forest 단점
- 모델의 예측 결과를 해석하고 이해하기 어렵다
2. 부스팅(Boosting)
: 여러 개의 약한 모델(Weak Learner)을 순차적으로 학습하여 강한 모델을 만듭니다. 매 순간 가장 예측이 어려운 샘플에 가중치를 더하여 학습 데이터셋에서 새로운 모델을 만듭니다. 대표적으로 에이다부스트(AdaBoost), 그래디언트 부스팅(Gradient Boosting) 등이 있습니다.
3. 스태킹(Stacking)
: 여러 개의 다른 모델들의 예측 결과를 기반으로, 하나의 모델을 더 학습시킵니다. 기존의 모델이 출력한 결과를 새로운 학습 데이터셋으로 만들어 새로운 모델을 학습시키는 것입니다. 스태킹은 단순한 앙상블 기법보다 높은 예측 성능을 보입니다.
