Random Forest로 손글씨 분류하기
손글씨 데이터는 0~9 까지의 숫자를 손으로 쓴 데이터입니다.
데이터는 sklearn.datasets의 load_digits 를 이용해 받을 수 있습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2021) #실행할 때마다 동일한 난수 시퀀스가 생성
from sklearn.datasets import load_digits #sklearn.datasets 모듈에서 load_digits() 함수를 사용하여 손글씨 숫자 데이터셋을 불러온다.
digits = load_digits() #데이터셋에서 data와 target을 추출
#. data는 8x8 픽셀 이미지로 표현된 숫자 이미지 데이터이며, target은 해당 이미지가 나타내는 숫자 레이블을 뜻함
data, target = digits["data"], digits["target"] #data와 target 변수에 각각 이미지 데이터와 레이블을 저장데이터는 각 픽셀의 값을 나타냄!
data[0], target[0]
데이터의 크기를 확인하면 64인데 이는 8*8 이미지를 flatten 시켰기 때문!
data[0].shape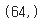
실제로 0부터 9까지의 데이터를 시각화하면 다음과 같이 나타납니다.
samples = data[:10].reshape(10, 8, 8)
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 10))
for idx, sample in enumerate(samples):
axes[idx//5, idx%5].imshow(sample, cmap="gray")해당 코드는 다음과 같은 작업을 수행함!
- data에서 첫 10개의 이미지 데이터를 추출하고, 각각 8x8 크기의 이미지로 재구성하여 samples 변수에 저장합니다.
- matplotlib.pyplot 모듈에서 subplots() 함수를 사용하여 2행 5열의 서브플롯을 생성하고, 각각의 subplot에 대한 참조를 axes 변수에 저장합니다.
- for 루프를 통해 samples에 저장된 각각의 이미지를 하나씩 가져와서, 해당 이미지를 그리드에 표시합니다.
- enumerate() 함수를 사용하여 현재 이미지의 인덱스를 idx에 저장합니다.
- axes[idx//5, idx%5]를 사용하여 현재 이미지를 표시할 subplot의 인덱스를 결정합니다.
- imshow() 함수를 사용하여 현재 이미지를 subplot에 그려줍니다. cmap="gray" 옵션을 사용하여 흑백으로 출력합니다.
- 이 코드는 손글씨 숫자 데이터셋에서 추출한 10개의 이미지를 시각화하여, 각 이미지가 어떻게 구성되어 있는지 확인할 수 있습니다. 이를 통해 데이터셋의 구성을 이해하고, 후속 분석 작업에 적절한 전처리를 수행할 수 있습니다.

Data split 데이터를 Train, Test로 나눠보자!
from sklearn.model_selection import train_test_split
train_data, test_data, train_target, test_target = train_test_split(
data, target, train_size=0.7, random_state=2021
)
print(f"train_data size: {len(train_target)}, {len(train_target)/len(data):.2f}")
print(f"test_data size: {len(test_target)}, {len(test_target)/len(data):.2f}")해당 코드는 다음과 같은 작업을 수행한다.
- sklearn.model_selection 모듈에서 train_test_split() 함수를 불러옵니다.
- train_test_split() 함수를 사용하여 데이터셋을 훈련 데이터와 테스트 데이터로 분리합니다.
- data와 target 변수에 저장된 데이터와 레이블을 입력으로 사용합니다.
- train_size=0.7 옵션을 사용하여 훈련 데이터셋의 크기를 전체 데이터셋의 70%로 설정합니다.
- random_state=2021 옵션을 사용하여 난수 시드를 설정합니다. 이를 통해 실행할 때마다 동일한 분할 결과가 생성됩니다.
t- rain_data, test_data, train_target, test_target 변수에 각각 훈련 데이터, 테스트 데이터, 훈련 데이터의 레이블, 테스트 데이터의 레이블을 저장합니다. - print() 함수를 사용하여 분할된 데이터셋의 크기와 비율을 출력합니다.
- f-string을 사용하여 출력 문자열의 형식을 지정합니다.
- len() 함수를 사용하여 각각의 데이터셋 크기를 계산하고 출력합니다.
- 소수점 둘째 자리까지 출력하도록 {:.2f} 포맷 지정자를 사용합니다.
이 코드는 데이터셋을 훈련 데이터와 테스트 데이터로 분리하고, 분리된 데이터셋의 크기와 비율을 출력합니다. 이를 통해 분석 작업에서 사용할 데이터셋의 구성을 확인할 수 있습니다.

Random Forest
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier()
random_forest.fit(train_data, train_target) #학습
random_forest.feature_importances_ #Feature Importance
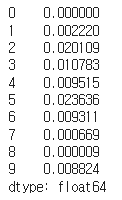
feature_importance = pd.Series(random_forest.feature_importances_)
feature_importance.head(10)randomforest 모델 객체의 fit() 메서드를 호출하여 train_data와 train_target 데이터를 사용하여 모델을 학습시킵니다.
random_forest 모델 객체의 feature_importances 속성을 사용하여 학습된 모델의 각 feature의 중요도를 계산합니다.
계산된 feature 중요도를 Pandas Series 객체로 변환하여 feature_importance 변수에 저장합니다.
feature_importance 변수에서 상위 10개의 feature 중요도를 출력합니다.
이 코드는 랜덤 포레스트 모델에서 학습된 각 feature의 중요도를 계산하고, 이를 통해 어떤 feature가 결과에 가장 큰 영향을 미치는지 확인할 수 있습니다. 이를 통해 feature engineering이나 모델링 방법 등을 조정할 수 있습니다.
feature_importance = feature_importance.sort_values(ascending=False)
feature_importance.head(10)feature_importance 변수에 저장된 feature 중요도를 내림차순으로 정렬하고, 상위 10개의 feature 중요도를 출력합니다.
이 코드를 통해 학습된 랜덤 포레스트 모델에서 가장 영향력 있는 feature 상위 10개를 확인할 수 있습니다. 이를 통해 데이터셋에서 어떤 feature가 예측에 가장 중요한 역할을 하는지 파악할 수 있습니다.

feature_importance.head(10).plot(kind="barh")해당 코드는 feature_importance 변수에서 상위 10개 feature의 중요도를 가로 막대 그래프로 시각화합니다.
plot() 메서드에 kind="barh" 옵션을 사용하여 가로 막대 그래프를 생성하고, head(10) 메서드를 사용하여 상위 10개 feature만 출력합니다.
이를 통해 상위 10개 feature의 중요도를 한 눈에 확인할 수 있습니다.
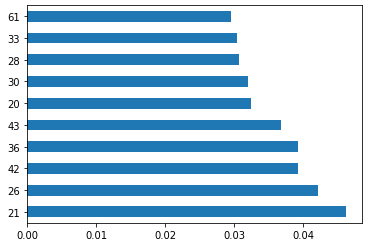
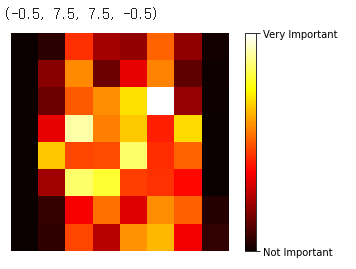
image = random_forest.feature_importances_.reshape(8, 8)
plt.imshow(image, cmap=plt.cm.hot, interpolation="nearest")
cbar = plt.colorbar(ticks=[random_forest.feature_importances_.min(), random_forest.feature_importances_.max()])
cbar.ax.set_yticklabels(['Not Important', 'Very Important'])
plt.axis("off")학습된 랜덤 포레스트 모델의 feature 중요도를 8x8 이미지로 시각화합니다.
featureimportances 속성에서 얻은 중요도 값을 8x8 행렬로 reshape합니다.
plt.imshow() 함수를 사용하여 중요도 값을 색으로 나타내는 이미지를 생성합니다. cmap=plt.cm.hot 옵션을 사용하여 색상을 설정합니다. interpolation="nearest" 옵션을 사용하여 이미지를 보정합니다.
colorbar를 추가하고, 최소와 최대 값의 tick을 설정합니다.
plt.axis() 함수를 사용하여 축을 제거합니다.
이를 통해 각 feature의 중요도가 이미지로 시각화되어, 어떤 feature가 더 중요한지 쉽게 파악할 수 있습니다. 또한, 이를 통해 feature engineering에 필요한 정보를 얻을 수도 있습니다.
예측 - 실제 데이터를 한 번 그려보자!
train_pred = random_forest.predict(train_data)
test_pred = random_forest.predict(test_data)
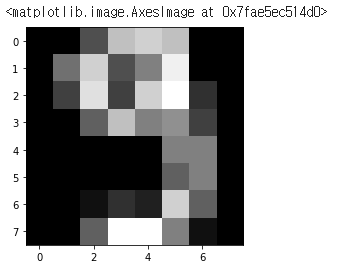
plt.imshow(train_data[4].reshape(8, 8), cmap="gray")
train_pred[4] #이 데이터에 대한 값을 보면 9로 잘 나오는 것을 볼 수 있다.학습된 랜덤 포레스트 모델을 사용하여 train_data에서 한 개의 데이터를 예측하고, 예측된 값을 출력합니다.
plt.imshow() 함수를 사용하여 train_data에서 4번째 데이터를 8x8 이미지로 시각화합니다.
random_forest.predict() 메서드를 사용하여 train_data에서 4번째 데이터의 예측값을 계산합니다.
예측값을 출력합니다.
이를 통해 랜덤 포레스트 모델이 train_data에서 4번째 데이터를 9로 예측한 것을 확인할 수 있습니다.
평가
from sklearn.metrics import accuracy_score
train_acc = accuracy_score(train_target, train_pred)
test_acc = accuracy_score(test_target, test_pred)
print(f"train accuracy is {train_acc:.4f}")
print(f"test accuracy is {test_acc:.4f}")학습된 랜덤 포레스트 모델의 정확도를 계산하고, 출력합니다.
sklearn.metrics 모듈에서 accuracy_score() 함수를 불러옵니다.
accuracy_score() 함수를 사용하여 train_data와 test_data에 대한 예측값과 실제값을 비교하여 정확도를 계산합니다.
계산된 train accuracy와 test accuracy를 출력합니다.
이를 통해 학습된 랜덤 포레스트 모델의 train data와 test data에 대한 예측 정확도를 쉽게 확인할 수 있습니다.

Best Hyper Parameter : 머신 러닝 모델의 최적의 성능을 발휘하는 하이퍼파라미터(Hyperparameter)의 값을 의미
- n_estimators
몇 개의 나무를 생성할 것 인지 정합니다. - criterion
어떤 정보 이득을 기준으로 데이터를 나눌지 정합니다.
"gini", "entropy" - max_depth
나무의 최대 깊이를 정합니다. - min_samples_split
노드가 나눠질 수 있는 최소 데이터 개수를 정합니다.
탐색해야할 argument들이 많을 때 일일이 지정을 하거나 for loop을 작성하기 힘들어집니다.
이 때 사용할 수 있는 것이 sklearn.model_selection의 GridSearchCV 함수이다!
# 랜덤 포레스트 모델을 사용하여 Grid Search를 수행하는 코드
from sklearn.model_selection import GridSearchCV
params = {
"n_estimators": [i for i in range(100, 1000, 200)],
"max_depth": [i for i in range(10, 50, 10)],
} #탐색할 값들의 argument와 범위를 정한다.
random_forest = RandomForestClassifier() #탐색에 사용할 모델을 생성
#탐색 시작 (cv는 k-fold의 k값을 말한다)
grid = GridSearchCV(estimator=random_forest, param_grid=params, cv=3)
grid = grid.fit(train_data, train_target)
#결과
print(f"Best score of paramter search is: {grid.best_score_:.4f}") #{'max_depth': 30, 'n_estimators': 300} 출력
print("Best parameter of best score is")
print(f"\t max_depth: {grid.best_params_['max_depth']}")
print(f"\t n_estimators: {grid.best_params_['n_estimators']}")위 코드는 랜덤 포레스트 모델을 사용하여 Grid Search를 수행하는 코드입니다.
먼저, GridSearchCV 함수를 사용하여 탐색할 값들의 argument와 범위를 정합니다. 이 경우, n_estimators와 max_depth에 대해 탐색할 값을 정해줍니다.
그리고 RandomForestClassifier()를 사용하여 모델을 생성합니다.
GridSearchCV 함수를 사용하여 모델과 탐색할 값들을 입력하고, cv 매개변수를 사용하여 k-fold의 k값을 정합니다. 그리고 fit() 함수를 사용하여 모델을 학습시키고 최적의 하이퍼파라미터를 찾습니다.
최적의 하이퍼파라미터와 그 때의 점수를 출력합니다.

예측
train_pred = best_rf.predict(train_data)
test_pred = best_rf.predict(test_data)평가
best_train_acc = accuracy_score(train_target, train_pred)
best_test_acc = accuracy_score(test_target, test_pred)
print(f"Best parameter train accuracy is {best_train_acc:.4f}")
print(f"Best parameter test accuracy is {best_test_acc:.4f}")
print(f"train accuracy is {train_acc:.4f}")
print(f"test accuracy is {test_acc:.4f}")
Feature Importance
#best_rf 모델의 feature importance를 시각화한 것
best_feature_importance = pd.Series(best_rf.feature_importances_)
best_feature_importance = best_feature_importance.sort_values(ascending=False)
best_feature_importance.head(10)
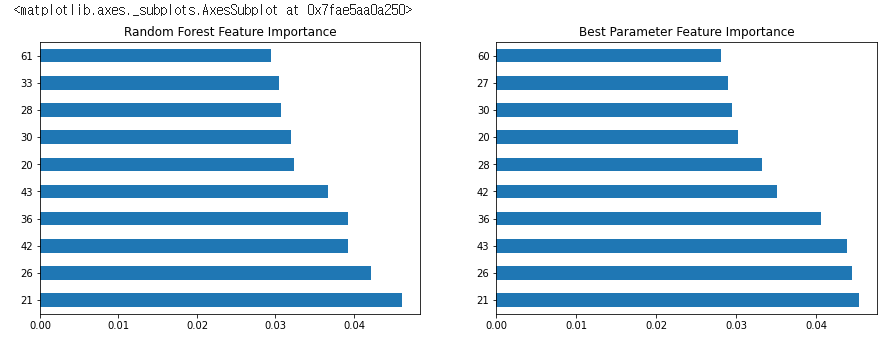
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 5))
feature_importance.head(10).plot(kind="barh", ax=axes[0], title="Random Forest Feature Importance")
best_feature_importance.head(10).plot(kind="barh", ax=axes[1], title="Best Parameter Feature Importance")위 코드는 best_rf 모델의 feature importance를 시각화한 것입니다.
먼저 best_rf 모델의 feature importance를 계산하고 내림차순으로 정렬합니다. 그리고 가장 영향력 있는 상위 10개 feature의 importance 값을 시각화합니다.
그 후, 위에서 구한 best_rf 모델의 feature importance와 이전에 생성한 random_forest 모델의 feature importance를 비교하기 위해 두 개의 subplot을 만듭니다. 좌측 subplot에는 random_forest 모델의 feature importance 상위 10개를, 우측 subplot에는 best_rf 모델의 feature importance 상위 10개를 시각화합니다.
즉, best_rf 모델에서 가장 영향력 있는 feature가 무엇인지, 그리고 이전 모델과 비교했을 때 best_rf 모델이 어떤 feature에 대해 더 큰 영향력을 가지는지 시각적으로 확인할 수 있습니다.