
KNN으로 음수 가능 여부를 판단하기
이번 실습에서 사용할 데이터는 음수가 가능한지를 판단하는 데이터 입니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2021)
#data load (water_potability.csv 파일을 불러와서 변수 data와 label에 할당)
water = pd.read_csv("water_potability.csv")
data = water.drop(["Potability"], axis=1)
label = water["Potability"]
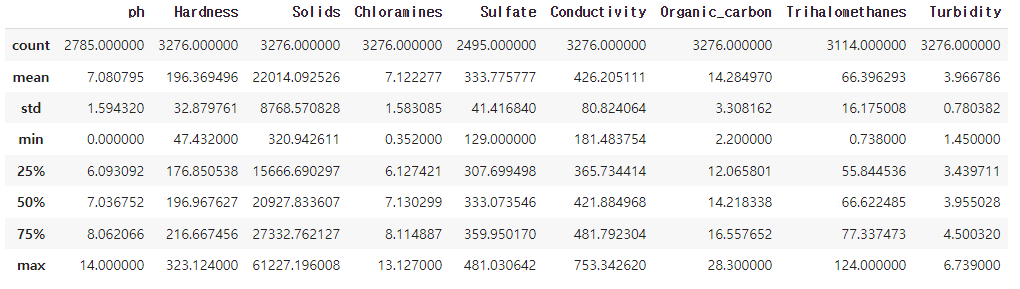
data.describe() #데이터의 변수들을 확인(데이터의 변수들의 통계 정보를 출력)
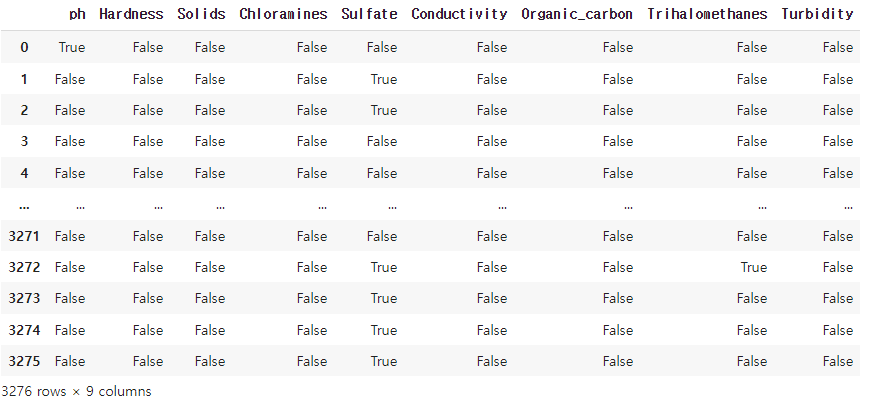
data.isna() #값이 비어있는 데이터의 개수를 확인(값이 비어있는 데이터의 위치를 True로, 값이 있는 데이터의 위치를 False로 반환)
data.isna().sum() #값이 비어있는 데이터의 개수를 확인
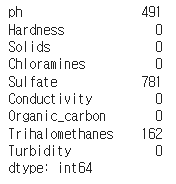
Data Preprocess
빈 데이터를 제거하는 전처리를 수행하려 합니다. 빈 데이터를 처리하는 방법은 row를 제거하는 법과 column을 제거하는 방법이 있습니다.
1) row를 제거하는 방법
data.isna().sum(axis=1) #각 행마다 값이 비어있는 데이터의 개수를 반환
na_cnt = data.isna().sum(axis=1) #각 행마다 값이 비어있는 데이터의 개수가 할당
print(na_cnt) #결과값으로는 각 행마다 값이 비어있는 데이터의 개수가 출력
drop_idx = na_cnt.loc[na_cnt > 0].index # na_cnt 변수에서 값이 비어있는 데이터의 개수가 1개 이상인 행의 인덱스를 추출
drop_row = data.drop(drop_idx, axis=0) #drop_idx를 사용하여 data에서 값이 비어있는 데이터가 있는 행을 제외한 데이터를 할당
drop_row.shape #drop_row의 행과 열의 개수를 반환
data.shape #원래 data의 행과 열의 개수를 반환
column을 제거하는 방법
na_cnt = data.isna().sum()
drop_cols = na_cnt.loc[na_cnt > 0].index
data = data.drop(drop_cols, axis=1)위 코드는 data에서 값이 비어있는 데이터가 있는 열을 제외한 데이터를 할당하는 코드입니다.
우선, isna() 함수와 sum() 함수를 사용하여 값이 비어있는 데이터의 개수를 열별로 구합니다.
na_cnt 변수에는 각 열마다 값이 비어있는 데이터의 개수가 할당됩니다.
drop_cols 변수에는 na_cnt에서 값이 비어있는 데이터의 개수가 1개 이상인 열의 이름을 추출합니다.
data = data.drop(drop_cols, axis=1) 코드는 drop_cols를 사용하여 data에서 값이 비어있는 데이터가 있는 열을 제외한 데이터를 할당합니다. 이때, axis=1은 열 방향으로 제외하라는 뜻입니다.
Data Split - 데이터를 Train, Test로 나누겠습니다.
from sklearn.model_selection import train_test_split
train_data, test_data, train_label, test_label = train_test_split(
data, label, train_size=0.7, random_state=2021
)
print(f"train_data size: {len(train_label)}, {len(train_label)/len(data):.2f}")
print(f"test_data size: {len(test_label)}, {len(test_label)/len(data):.2f}")위 코드는 scikit-learn 라이브러리에서 제공하는 train_test_split 함수를 사용하여 데이터를 훈련용과 테스트용으로 분리하는 코드입니다.
train_test_split 함수는 데이터와 레이블을 입력받아, 입력된 비율에 따라 데이터를 무작위로 분리합니다. 이때, train_size는 훈련용 데이터의 비율을 나타냅니다.
random_state는 무작위로 데이터를 분리할 때 사용되는 난수의 시드값을 설정합니다. 이를 통해 결과의 재현성을 보장할 수 있습니다.
train_data, test_data, train_label, test_label 변수에는 train_test_split 함수의 결과값으로 나뉘어진 데이터와 레이블이 할당됩니다.
마지막으로, f-string을 사용하여 train_data와 test_data의 크기와 데이터셋의 크기에 대한 비율을 출력합니다.
KNN
KNeighborsClassifier에서 탐색해야 할 argument들은 다음과 같습니다.
- n_neighbors
몇 개의 이웃으로 예측할 것 인지 정합니다. - p
거리를 어떤 방식으로 계산할지 정합니다.
1: manhattan distance
2: euclidean distance
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
#탐색범위 선정
params = {
"n_neighbors": [i for i in range(1, 12, 2)],
"p": [1, 2]
}
#탐색
grid_cv = GridSearchCV(knn, param_grid=params, cv=3, n_jobs=-1)
grid_cv.fit(train_data, train_label)
#결과
print(f"Best score of paramter search is: {grid_cv.best_score_:.4f}")
grid_cv.best_params_
print("Best parameter of best score is")
print(f"\t n_neighbors: {grid_cv.best_params_['n_neighbors']}")
print(f"\t p: {grid_cv.best_params_['p']}")
#예측
train_pred = grid_cv.best_estimator_.predict(train_data)
test_pred = grid_cv.best_estimator_.predict(test_data)
#평가
from sklearn.metrics import accuracy_score
train_acc = accuracy_score(train_label, train_pred)
test_acc = accuracy_score(test_label, test_pred)
print(f"train accuracy is {train_acc:.4f}")
print(f"test accuracy is {test_acc:.4f}")위 코드는 scikit-learn 라이브러리에서 제공하는 GridSearchCV 함수를 사용하여 KNN 분류기의 최적의 하이퍼파라미터를 탐색하는 코드입니다.
GridSearchCV 함수는 매개변수 그리드를 지정하여 하이퍼파라미터 탐색 범위를 설정합니다. 이때, cv는 교차검증의 폴드 수를 의미합니다.
n_jobs는 사용할 CPU 코어의 수를 지정합니다. -1로 설정하면 가능한 모든 코어를 사용합니다.
grid_cv.fit(train_data, train_label) 코드는 GridSearchCV 함수를 사용하여 탐색을 수행하고, 최적의 하이퍼파라미터와 최상의 교차검증 점수를 반환합니다.
마지막으로, f-string을 사용하여 최적의 하이퍼파라미터와 교차검증 점수 및 훈련 데이터와 테스트 데이터의 정확도를 출력합니다.
Scaling을 할 경우
KNN은 거리를 기반으로 하는 알고리즘이기 때문에 데이터의 크기에 영향을 받습니다.
Scaling을 진행해 크기를 맞춰줍니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(train_data)
scaled_train_data = scaler.transform(train_data)
scaled_test_data = scaler.transform(test_data)
#탐색
scaling_knn = KNeighborsClassifier()
scaling_grid_cv = GridSearchCV(scaling_knn, param_grid=params, n_jobs=-1)
scaling_grid_cv.fit(scaled_train_data, train_label)
scaling_grid_cv.best_score_
scaling_grid_cv.best_params_
#평가
scaling_train_pred = scaling_grid_cv.best_estimator_.predict(scaled_train_data)
scaling_test_pred = scaling_grid_cv.best_estimator_.predict(scaled_test_data)
scaling_train_acc = accuracy_score(train_label, scaling_train_pred)
scaling_test_acc = accuracy_score(test_label, scaling_test_pred)
print(f"Scaled data train accuracy is {scaling_train_acc:.4f}")
print(f"Scaled data test accuracy is {scaling_test_acc:.4f}")
#마무리
print(f"test accuracy is {test_acc:.4f}")
print(f"Scaled data test accuracy is {scaling_test_acc:.4f}")이 코드는 머신러닝 모델인 k-NN(K-Nearest Neighbors)를 사용하여 수질 데이터(water_potability.csv)를 분류하는 작업을 수행합니다.
데이터 전처리 단계에서는 데이터셋에서 결측치를 제거하고, 훈련 데이터와 테스트 데이터로 나누어줍니다.
그리드 서치(GridSearchCV)를 사용하여 최적의 k와 거리 측정 방법을 선택하고, 최적화된 모델로 훈련 데이터셋을 학습합니다.
이후, StandardScaler()를 사용하여 데이터를 표준화하고, 다시 그리드 서치와 k-NN 모델을 사용하여 최적의 k와 거리 측정 방법을 선택하고, 최적화된 모델로 훈련 데이터셋을 학습합니다.
최종적으로, 각각의 모델의 정확도(accuracy)를 출력합니다.
