Iris 데이터와 KNN
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2021)
#Data Load
from sklearn.datasets import load_iris
iris = load_iris()
data = iris.data
target = iris.target
print(target)
print(target != 0)
data.shape
data = data[target != 0, 2:]
target = target[target != 0]
data.shape
data = pd.DataFrame(data)
target = pd.DataFrame(target)
~data.duplicated()
target = target.loc[~data.duplicated()].values.flatten()
data = data.loc[~data.duplicated()].values
data.shape
plt.scatter(data[:, 0], data[:, 1], c=target)해당 코드는 iris 데이터셋을 로드하고, 데이터와 타겟 배열을 추출하는 작업을 수행합니다.
타겟 배열은 iris의 종류를 나타내는 라벨(0, 1, 2)을 포함하고 있습니다.
이 코드는 라벨이 0인 샘플을 제외하고, 라벨이 1과 2인 샘플만을 남기도록 데이터와 타겟 배열을 필터링합니다.
이후 데이터 배열에서 세 번째와 네 번째 열만을 선택하도록 슬라이싱 합니다.
이 두 열은 꽃잎의 길이와 너비를 나타냅니다. 데이터 배열에서 중복된 행이 있는지 확인하고, 있다면 제거합니다.
결과적으로 생성된 데이터와 타겟 배열은 산점도 그래프로 나타내어져, 타겟 값에 따라 점의 색깔이 달라집니다.
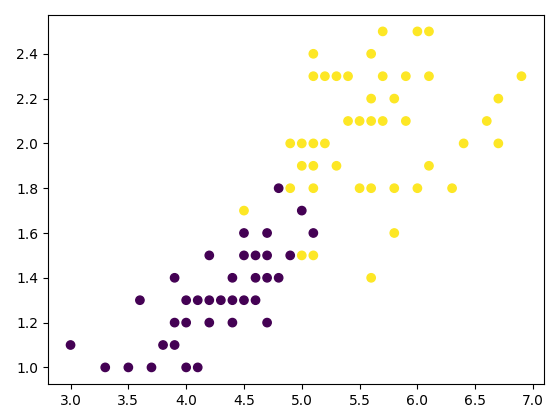
시각화 데이터
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))위 코드는 데이터를 그래프로 표현하기 위해 필요한 x, y좌표 범위를 설정하는 부분입니다.
x_min : x 좌표의 최소값에 1을 빼서 x 범위를 조정합니다.
x_max : x 좌표의 최대값에 1을 더해서 x 범위를 조정합니다.
y_min : y 좌표의 최소값에 1을 빼서 y 범위를 조정합니다.
y_max : y 좌표의 최대값에 1을 더해서 y 범위를 조정합니다.
이렇게 범위를 설정하면, np.meshgrid() 함수를 이용하여 각 x, y좌표를 만들어냅니다. np.arange() 함수를 이용하여 x좌표 범위와 y좌표 범위에서 0.02씩 간격을 두고 값을 생성하고, np.meshgrid() 함수를 이용하여 이 값들을 조합해 각 점들의 좌표값을 만들어냅니다. 이렇게 생성된 x, y좌표값들은 그래프 상의 모든 점들을 대상으로 예측 값을 계산하는 데 사용됩니다.
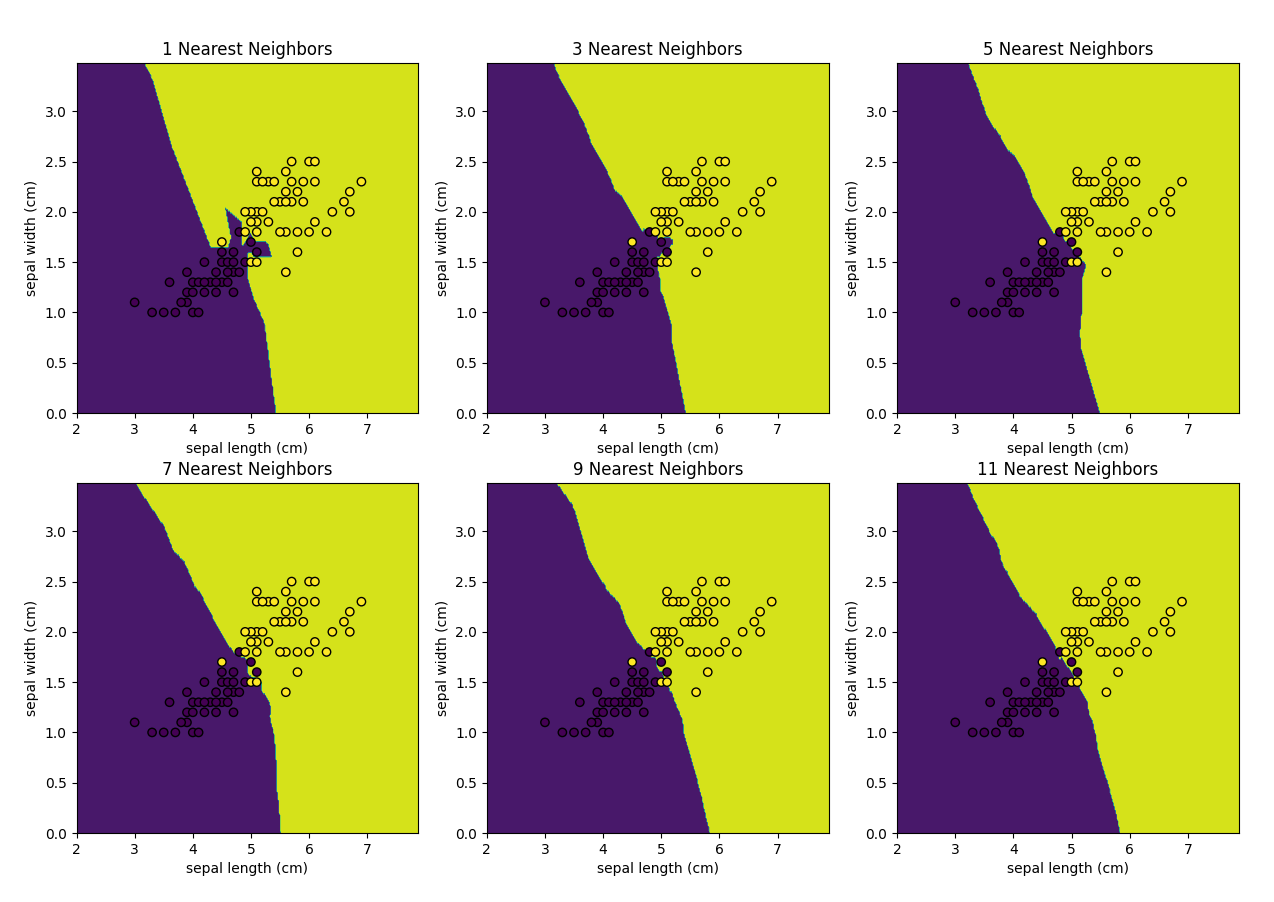
k 값에 따른 knn의 결정경계를 그려봅니다.
k 가 작을수록 overfitting이 k가 클수록 underfitting이 됩니다.
from sklearn.neighbors import KNeighborsClassifier
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(15, 10))
for idx, n in enumerate(range(1, 12, 2)):
# knn 생성 및 학습
knn = KNeighborsClassifier(n_neighbors=n)
knn.fit(data, target)
# 시각회 데이터 예측
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax = axes[idx//3, idx%3]
# 영역 표시
ax.contourf(xx, yy, Z)
# 데이터 표시
ax.scatter(
data[:, 0], data[:, 1], c=target, alpha=1.0, edgecolor="black"
)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title(f"{n} Nearest Neighbors")위 코드는 k-최근접 이웃 분류기를 사용하여 데이터를 분류하고 시각화하는 코드입니다.
먼저, 2행 3열의 그래프를 생성합니다. 그리고 1부터 11까지 2간격으로 k값을 변경하면서 각각의 k에 대한 k-최근접 이웃 분류기를 생성하고 학습합니다.
다음으로, np.c_를 사용하여 xx와 yy를 1차원 배열로 바꾼 다음 np.ravel() 함수를 사용하여 1차원 배열로 펼칩니다. 이렇게 만들어진 1차원 배열은 knn.predict() 함수의 입력값으로 사용됩니다. knn.predict() 함수를 사용하여 xx,yy를 포함하는 2차원 평면상의 모든 점에 대한 예측 값을 구합니다.
그런 다음 Z를 다시 xx의 shape로 reshape하고, ax.contourf() 함수를 사용하여 예측된 영역을 색상으로 표시합니다.
마지막으로 ax.scatter() 함수를 사용하여 데이터를 표시합니다. 2차원 평면상의 모든 점에 대해 예측 값을 구한 후 예측된 영역과 함께 데이터를 시각화하면 각 k 값에 대한 데이터 분류를 시각적으로 확인할 수 있습니다.
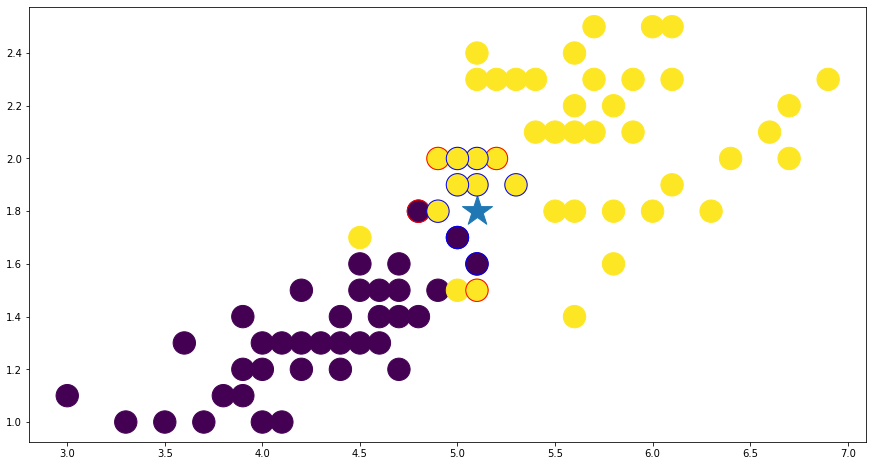
나의 가장 가까운 이웃은? KNN의 거리의 종류는 p를 통해서 바꿀 수 있습니다.
p=1 #맨해튼 거리
p=2 #유클리드 거리
Euclidean Distance
train_data, train_target = data[:-1], target[:-1]
test_data = data[-1:]
len(train_data), len(test_data)
euclid_knn = KNeighborsClassifier(n_neighbors=10)
euclid_knn.fit(train_data, train_target)
euclid_knn.kneighbors(
test_data, n_neighbors=1, return_distance=False
).ravel()
euclid_neighbors_idx = euclid_knn.kneighbors(
test_data, n_neighbors=10, return_distance=False
).ravel()
euclid_neighbors = train_data[euclid_neighbors_idx]
euclid_neighbors_label = train_target[euclid_neighbors_idx]
print(test_data)
print(euclid_neighbors)
print(euclid_neighbors_label)
euclid_knn.predict(test_data)
euclid_knn.predict_proba(test_data)
plt.figure(figsize=(15, 8))
plt.scatter(train_data[:, 0], train_data[:, 1], c=train_target, s=500)
plt.scatter(test_data[0, 0], test_data[0, 1], marker="*", s=1000)
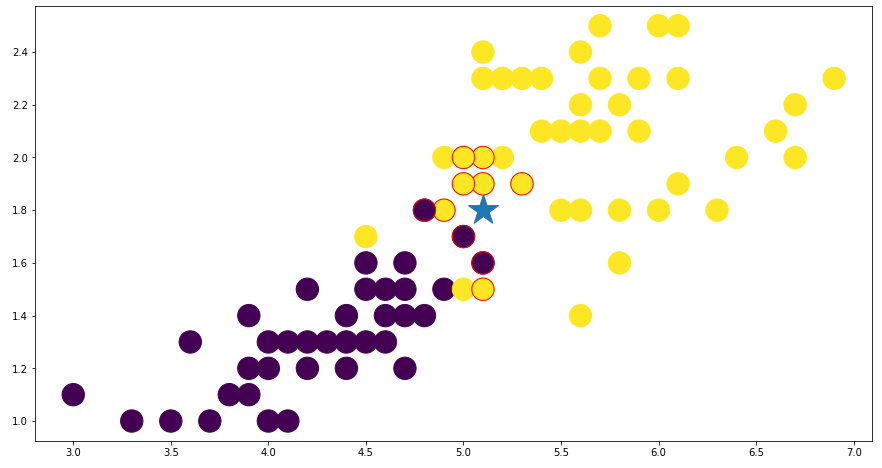
plt.scatter(euclid_neighbors[:, 0], euclid_neighbors[:, 1], c=euclid_neighbors_label, edgecolors="red", s=500)이 코드는 KNN 분류기를 사용하여 iris 데이터셋을 분류하는 예제입니다.
data는 iris 데이터셋의 feature 값들이 저장된 배열이고, target은 각 feature 값들이 어떤 iris 종류에 해당하는지 저장된 배열입니다. train_data는 data에서 마지막 row를 제외한 모든 row를 선택하고, train_target은 target에서 마지막 값을 제외한 모든 값을 선택하여 훈련 데이터를 생성합니다. test_data는 data에서 마지막 row만 선택하여 테스트 데이터를 생성합니다.
다음으로, euclid_knn 객체를 생성하고, 이 객체를 사용하여 KNN 분류기를 학습합니다. n_neighbors는 이웃의 개수를 지정하는 파라미터입니다.
그 다음으로, euclid_knn.kneighbors() 메서드를 사용하여 test_data에 대한 가장 가까운 이웃을 찾습니다. n_neighbors 파라미터를 1로 지정하면 가장 가까운 하나의 이웃만 반환합니다. 이를 통해 분류기가 테스트 데이터를 어떻게 분류할지에 대한 감을 얻을 수 있습니다.
euclid_knn.kneighbors() 메서드를 다시 호출하여 test_data에 대한 10개의 가장 가까운 이웃을 찾습니다. 이웃 데이터와 해당 이웃의 클래스 레이블을 변수에 저장하고, 이를 출력합니다.
마지막으로, 이웃 데이터와 테스트 데이터, 그리고 훈련 데이터를 시각화합니다. plt.scatter() 메서드를 사용하여 데이터 포인트를 표시하고, marker와 s 파라미터를 사용하여 테스트 데이터와 이웃 데이터를 구분합니다. 이웃 데이터의 클래스 레이블은 c와 edgecolors 파라미터를 사용하여 구분합니다.
Manhattan Distance
manhattan_knn = KNeighborsClassifier(n_neighbors=10, p=1)
manhattan_knn.fit(train_data, train_target)
manhattan_neighbors_idx = manhattan_knn.kneighbors(
test_data, n_neighbors=10, return_distance=False
).ravel()
manhattan_neighbors = train_data[manhattan_neighbors_idx]
manhattan_neighbors_label = train_target[manhattan_neighbors_idx]
manhattan_neighbors
manhattan_neighbors_label
manhattan_knn.predict_proba(test_data)
plt.figure(figsize=(15, 8))
plt.scatter(train_data[:, 0], train_data[:, 1], c=train_target, s=500)
plt.scatter(test_data[0, 0], test_data[0, 1], marker="*", s=1000)
plt.scatter(manhattan_neighbors[:, 0], manhattan_neighbors[:, 1], c=manhattan_neighbors_label, edgecolors="red", s=500)이 코드는 유클리드 거리 대신 맨해튼 거리를 사용하여 KNN 분류기를 훈련하고 시각화하는 코드입니다. 맨해튼 거리는 유클리드 거리와 달리 각각의 특성 차이의 절댓값을 더하여 구하는 방식입니다.
먼저 manhattan_knn 변수에 n_neighbors=10과 p=1을 지정하여 맨해튼 거리를 사용하여 KNN 분류기를 생성합니다. 그런 다음 manhattan_knn.kneighbors 메서드를 사용하여 테스트 데이터의 10개의 가장 가까운 이웃의 인덱스를 찾습니다. 이웃들과 해당 레이블을 manhattan_neighbors와 manhattan_neighbors_label에 저장합니다.
마지막으로, plt.scatter 함수를 사용하여 학습 데이터, 테스트 데이터, 그리고 맨해튼 거리 분류기에서 찾은 이웃 데이터를 시각화합니다.
비교
euclid_neighbors_idx
manhattan_neighbors_idx
set(euclid_neighbors_idx) - set(manhattan_neighbors_idx)
set(manhattan_neighbors_idx) - set(euclid_neighbors_idx)
diff_neighbors_idx = list(set(euclid_neighbors_idx) - set(manhattan_neighbors_idx))
diff_neighbors_idx.extend(list(set(manhattan_neighbors_idx) - set(euclid_neighbors_idx)))
diff_neighbors_idx
diff_neighbors = train_data[diff_neighbors_idx]
diff_neighbors_label = train_target[diff_neighbors_idx]
same_neighbors_idx = list(set(euclid_neighbors_idx) & set(manhattan_neighbors_idx))
same_neighbors_idx
same_neighbors = train_data[same_neighbors_idx]
same_neighbors_label = train_target[same_neighbors_idx]
plt.figure(figsize=(15, 8))
plt.scatter(train_data[:, 0], train_data[:, 1], c=train_target, s=500)
plt.scatter(test_data[0, 0], test_data[0, 1], marker="*", s=1000)
plt.scatter(diff_neighbors[:, 0], diff_neighbors[:, 1], c=diff_neighbors_label, edgecolors="red", s=500)
plt.scatter(same_neighbors[:, 0], same_neighbors[:, 1], c=same_neighbors_label, edgecolors="blue", s=500)위 코드는 유클리드 거리와 맨하탄 거리 두 가지 거리 척도를 사용하여 KNN 분류기를 훈련하고, 테스트 인스턴스의 10개 최근접 이웃을 찾아서 이웃들의 레이블과 함께 시각화하는 과정입니다.
먼저 euclid_knn과 manhattan_knn을 각각 생성하여 각각의 거리 척도로 KNN 분류기를 훈련합니다. 그리고 test_data를 이용하여 각각의 분류기에서 10개의 최근접 이웃을 찾습니다. set() 함수와 - 연산자를 이용하여 두 리스트의 차집합과 교집합을 구하고, 이를 diff_neighbors_idx와 same_neighbors_idx에 저장합니다. 이를 이용하여 두 분류기에서 다르게 예측한 이웃들과 같은 예측을 한 이웃들을 시각화합니다.