로지스틱 회귀(Logistic Regression)는
이진 종속 변수(또는 결과 또는 반응 변수로도 알려짐)와 하나 이상의 독립 변수(또는 예측 변수 또는 설명 변수로도 알려짐) 간의 관계를 분석하고 모델링하는 데 사용되는 통계적 방법입니다.
로지스틱 회귀 모델은 일반화 선형 모델의 일종으로,
독립 변수의 선형 조합을 로지스틱 함수를 사용하여 종속 변수에 대한 확률 점수로 변환합니다.
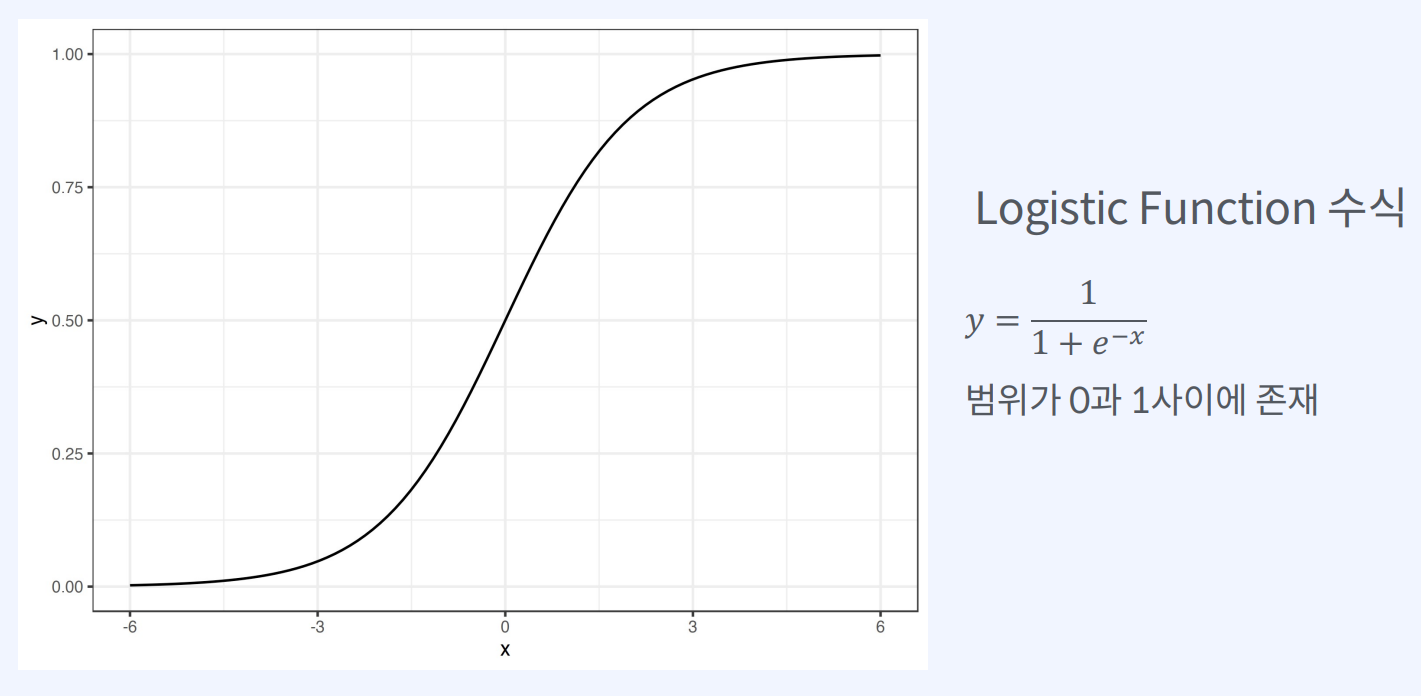
로지스틱 함수는 시그모이드 함수라고도하며, 입력 값을 0과 1 사이의 값으로 매핑하여
종속 변수가 1의 값을 취할 확률로 해석할 수 있습니다.
로지스틱 회귀 모델은 독립 변수의 계수(즉, 기울기 매개 변수)를 추정합니다.
이 계수는 해당 독립 변수의 한 단위 변화에 대한 종속 변수의 로그 오즈 변화를 나타내며,
다른 모든 변수를 일정하게 유지하는 동안 적용됩니다.
로지스틱 회귀는 이진 및 다중 클래스 분류 문제뿐만 아니라 시그모이드 패턴을 따르는 연속 결과 모델링에도 사용될 수 있습니다.
의학, 경제, 사회과학 등 다양한 분야에서 널리 사용됩니다.
데이터의 형태
-
연속형 데이터 -> Linear Regression
키, 몸무게, … -
비연속형(범주형) -> Linear Regression..?
성별, …
범주형 데이터와 선형 회귀
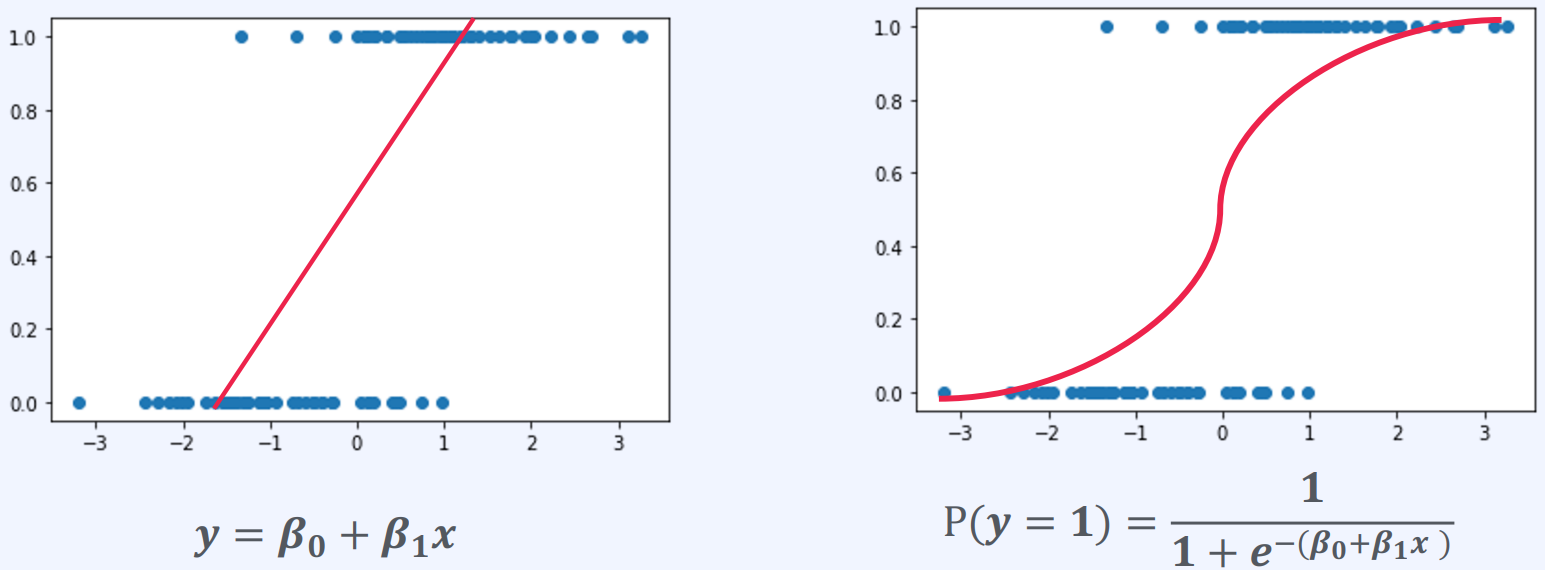
- 정답의 범위가 0과 1 사이임
- 단순 선형 회귀의 예측값의 범위는 −∞~∞
- 0과 1사이를 벗어나는 예측은 예측의 정확도를 낮추게 됨
- 예측의 결과가 0과 1사이에 있어야 한다!
범주형 데이터는 선형 회귀 모델에 직접 적용할 수 없습니다.
이유는 범주형 변수는 명목형 변수와 순서형 변수로 구분되며, 순서형 변수의 경우 순서 정보를 나타내기 위해 정수형으로 인코딩할 수 있지만 명목형 변수는 이처럼 인코딩 할 수 없습니다.
대신, 명목형 변수를 포함한 범주형 데이터를 다루기 위해 로지스틱 회귀와 같은 분류 모델을 사용하는 것이 좋습니다.
로지스틱 회귀는 독립 변수와 종속 변수 간의 관계를 모델링하는 데 사용되며, 결과는 종속 변수의 확률값으로 나타냅니다.
따라서 로지스틱 회귀 모델은 범주형 변수와 연속형 변수 모두를 다룰 수 있습니다.
Logistic Regression의 정의
- Linear Regression + Logistic Function
- 정답이 범주형일 때 사용하는 Regression Model
즉, Logistic Regression은 Linear Regression에 로지스틱 함수를 적용한 모델입니다. Linear Regression은 연속형 종속 변수와 연속형 독립 변수 간의 관계를 모델링하는 데 사용되며, Logistic Regression은 이진 분류 문제와 같이 범주형 종속 변수와 연속형 또는 범주형 독립 변수 간의 관계를 모델링하는 데 사용됩니다.
로지스틱 함수는 S자 모양의 곡선으로, 입력값을 0과 1 사이의 값으로 제한합니다.
Logistic Regression은 이 함수를 사용하여 종속 변수가 각 클래스에 속할 확률을 예측하며, 이 예측 결과를 기반으로 분류를 수행합니다.
이러한 이유로 Logistic Regression은 분류 모델 중 하나로 자주 사용됩니다.

Threshold의 정의
- 확률값을 범주형으로 변환할 때의 기준
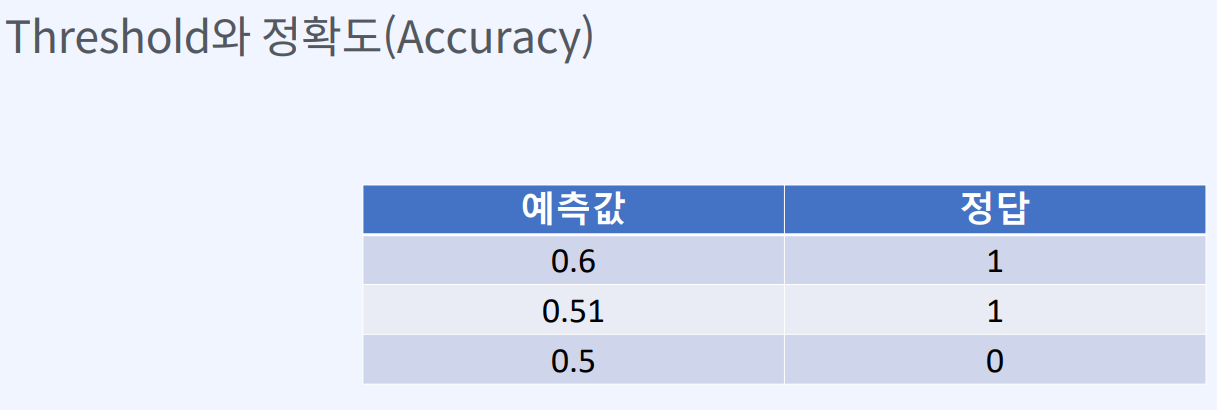
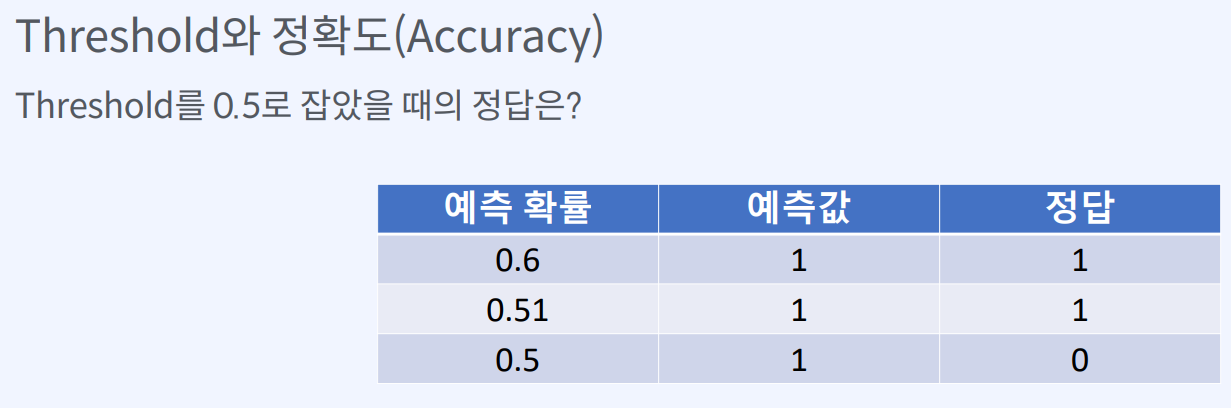
Threshold는 확률값을 범주형 값으로 변환할 때 사용되는 기준값입니다.
로지스틱 회귀 모델에서는 종속 변수의 확률 값을 0과 1 사이의 값으로 출력합니다.
이 확률 값은 임계값(Threshold)을 기준으로 0 또는 1로 변환됩니다.
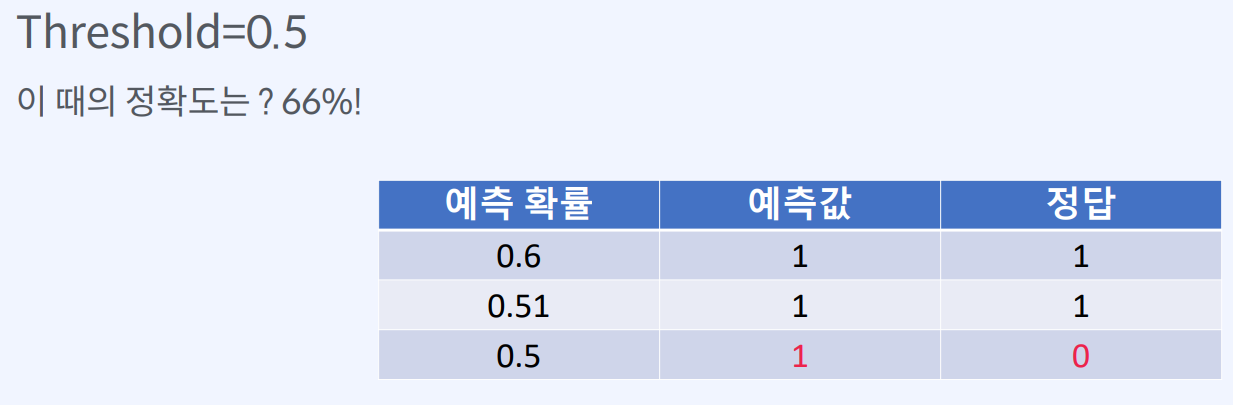
이를 예로 들면, 이진 분류 문제에서 예측된 확률 값이 0.6인 경우, 일반적으로 0.5를 Threshold로 사용합니다. 따라서 확률 값이 0.6보다 크면 1로, 작으면 0으로 예측하게 됩니다.
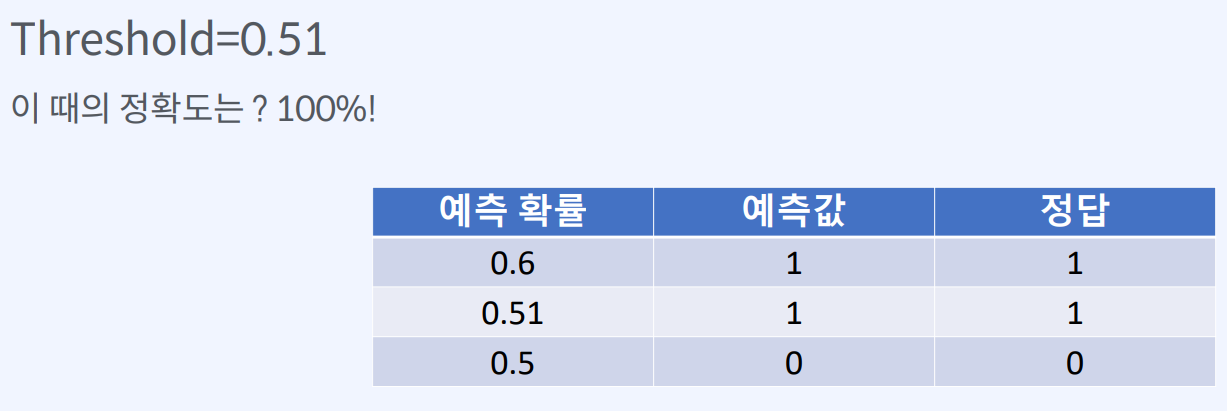
하지만 Threshold 값은 문제의 성격에 따라 다르게 설정될 수 있으며,
Threshold 값의 변화에 따라 모델의 정확도, 정밀도, 재현율 등의 평가 지표가 달라질 수 있습니다.
따라서 Threshold 값의 설정은 모델 성능 향상에 중요한 역할을 합니다.
AUROC (Area Under ROC)
정확도는 Threshold에 따라 변하기 때문에 지표로서 부족할 때가 있다.
이를 보완하기 위한 Threshold에 의해 값이 변하지 않는 지표가 AUROC
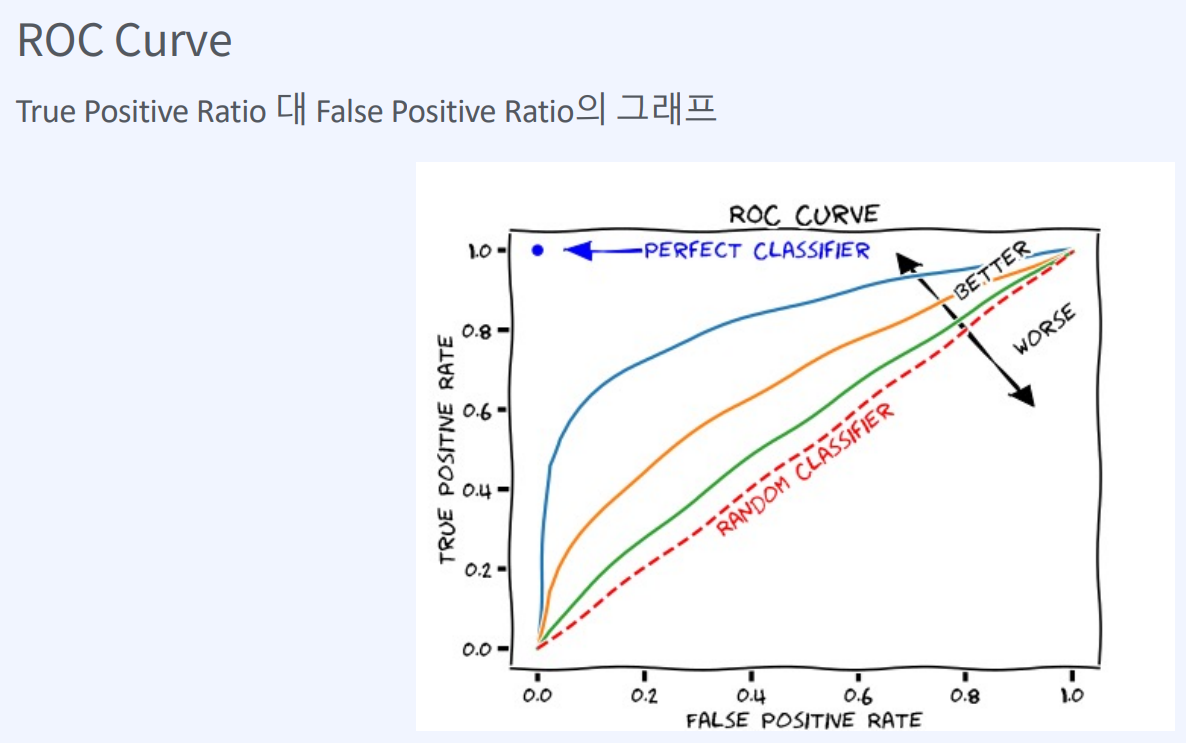
AUROC(Area Under ROC Curve)는 분류 모델의 성능을 평가하는 지표 중 하나로
ROC Curve의 아래 면적을 계산한 값입니다.
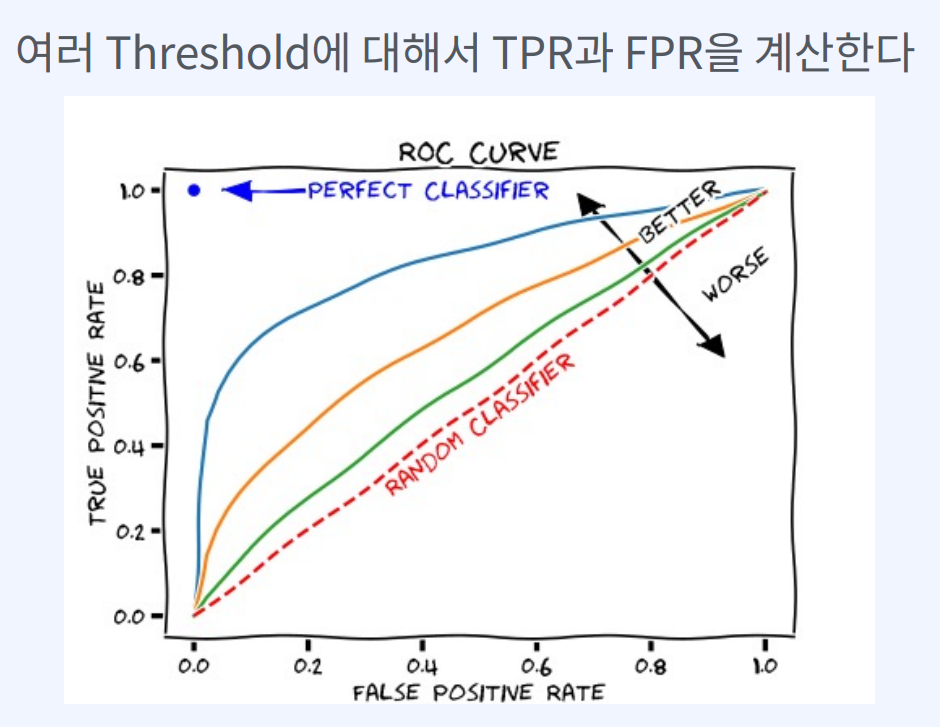
ROC Curve는 분류 모델의 Threshold를 변화시키면서,
분류 모델의 성능을 시각적으로 나타낸 그래프입니다.
이 곡선은 False Positive Rate(FPR)을 x축으로, True Positive Rate(TPR)을 y축으로 나타냅니다.
AUROC는 Threshold 값의 변화에 따라 값이 변하지 않기 때문에 Threshold의 영향을 받지 않는 지표입니다.
AUROC가 1에 가까울수록 분류 모델의 성능이 좋은 것으로 판단할 수 있습니다. AUROC가 0.5에 가까울수록 무작위로 예측하는 것과 다를 바 없으며,
AUROC가 0.5보다 낮으면 분류 모델의 성능이 더 나쁜 것으로 판단합니다.
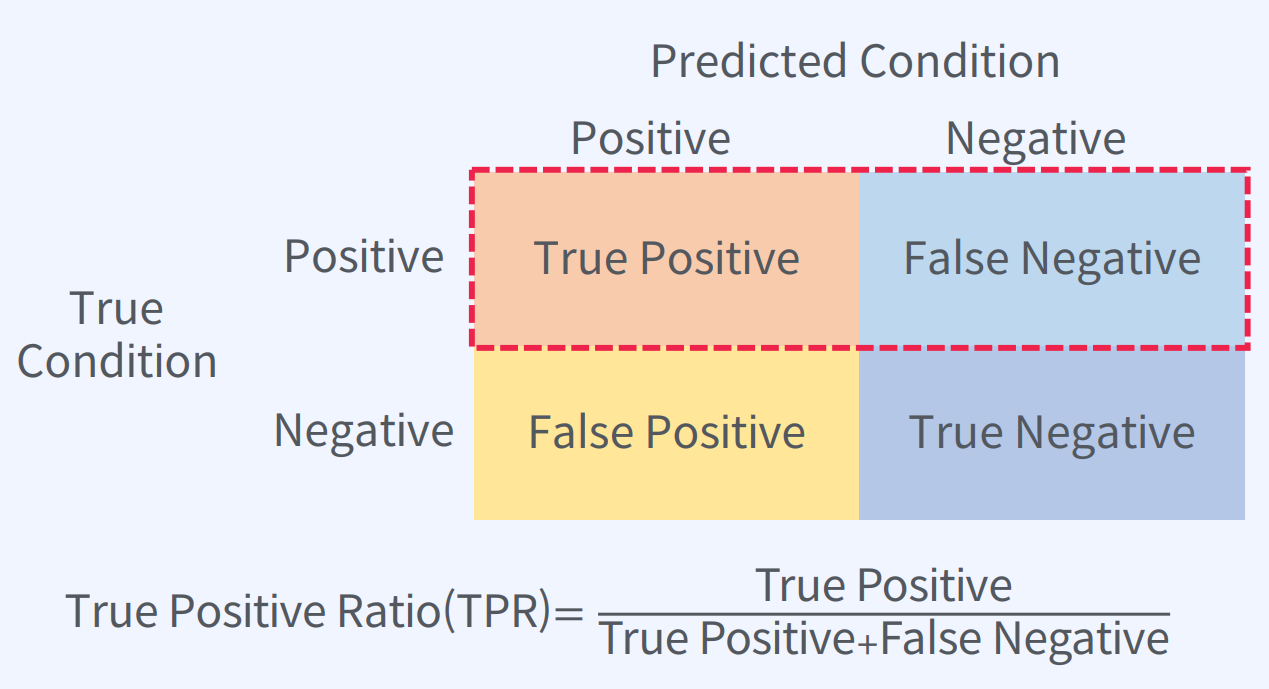
True Positive Ratio(TPR)은 분류 모델에서 실제 Positive인 데이터 중에서 모델이 Positive로 예측한 데이터의 비율을 나타내는 지표입니다.
TPR은 민감도(Sensitivity) 또는 재현율(Recall)이라고도 불립니다.
TPR = TP / (TP + FN)
여기서, TP는 True Positive의 수이고, FN은 False Negative의 수입니다.
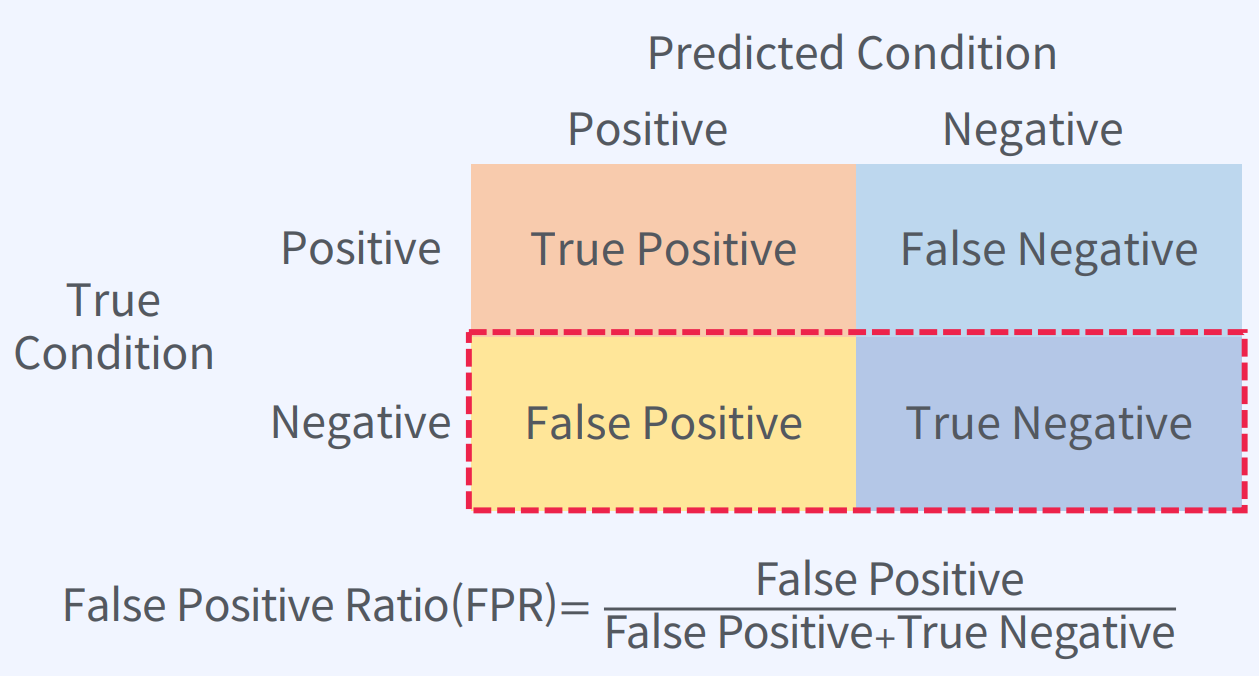
False Positive Ratio(FPR)은 분류 모델에서 실제 Negative인 데이터 중에서 모델이 Positive로 잘못 예측한 데이터의 비율을 나타내는 지표입니다. FPR은 1에서 특이도(Specificity)를 뺀 값과 같습니다.
FPR = FP / (FP + TN) = 1 - Specificity
여기서, FP는 False Positive의 수이고, TN은 True Negative의 수입니다.
FPR은 0에 가까울수록 분류 모델이 Negative로 예측한 것과 실제 Negative인 것이 일치하는 것이며, 1에 가까울수록 분류 모델의 성능이 나쁜 것입니다.
True Positive
실제 1을 1이라고 예측한 수

False Negative
실제 1을 0이라고 예측한 수

False Positive
실제 0을 1이라고 예측한 수

True Negative
실제 0을 0이라고 예측한 수

True Positive Ratio(TPR) = 2/3=0.66
False Positive Ratio(FPR) = 1/3 = 0.33
우리가 이항 분류 문제를 가지고 있다고 가정해봅시다.
이 때 실제 레이블은 다음과 같습니다:
실제 양성: 3
실제 음성: 6
우리 모델이 다음과 같은 레이블을 예측한다고 가정해봅시다:
예측한 양성: 4
예측한 음성: 5
그럼, 우리는 다음과 같이 True Positive Ratio (TPR)와 False Positive Ratio (FPR)을 계산할 수 있습니다:
TPR = TP / (TP + FN) = 2 / 3 = 0.67
여기서 TP는 실제로 양성인데 예측도 양성인 경우 (즉, 양성으로 예측한 것이 실제로 양성인 경우)의 수를 말하며, FN은 실제로 양성인데 예측은 음성인 경우 (즉, 음성으로 예측한 것이 실제로 양성인 경우)의 수를 말합니다.
FPR = FP / (FP + TN) = 1 / 6 = 0.17
여기서 FP는 실제로 음성인데 예측은 양성인 경우 (즉, 양성으로 예측한 것이 실제로 음성인 경우)의 수를 말하며, TN은 실제로 음성인데 예측도 음성인 경우 (즉, 음성으로 예측한 것이 실제로 음성인 경우)의 수를 말합니다.
TPR과 FPR의 계산에서는 모델의 확률 점수를 이진 예측으로 변환하기 위한 특정 임계값을 가정합니다. 임계값을 변경하면 TPR과 FPR 값도 변경될 수 있음을 유의해야 합니다.
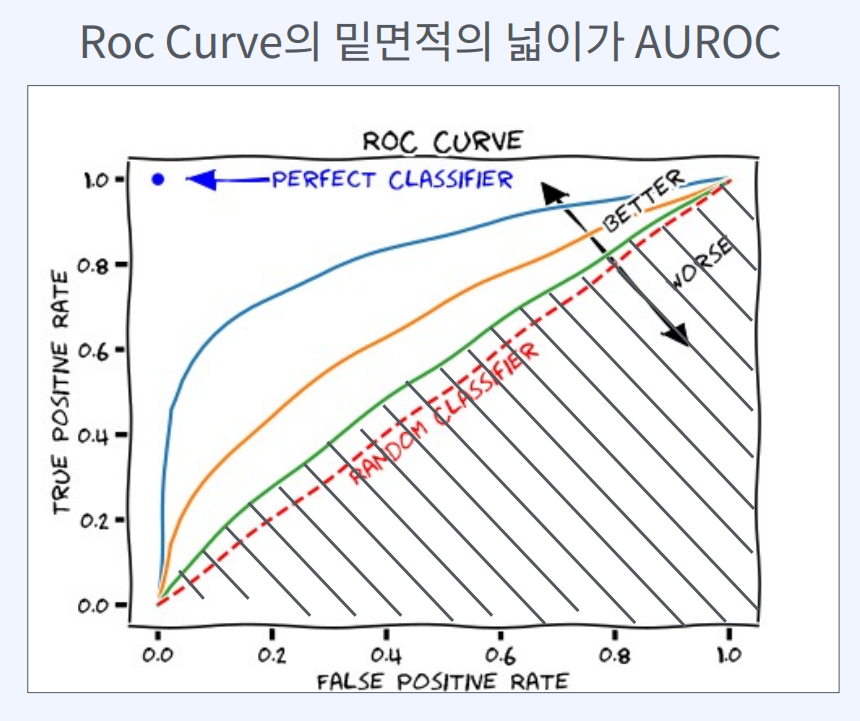
ROC 곡선 아래 면적(Area Under ROC Curve, AUROC)은 분류 모델의 성능을 나타내는 지표 중 하나로, 분류 모델의 TPR(True Positive Rate)과 FPR(False Positive Rate) 사이의 trade-off를 고려하여 분류 모델의 성능을 종합적으로 평가합니다.
AUROC는 0부터 1까지의 값을 가지며, 1에 가까울수록 모델의 성능이 우수합니다.
AUROC 값이 0.5에 가까울 경우 모델의 분류 성능이 무작위 수준에 가깝다는 것을 의미
즉,
J = (True Positive)/(True Positive + False Negative + True Negative + False Positive - 1)
여기서 True Positive은 실제로 양성이며 양성으로 예측된 인스턴스 수를 나타내고, False Negative는 실제로 양성이지만 음성으로 예측된 인스턴스 수를 나타내며, True Negative은 실제로 음성이며 음성으로 예측된 인스턴스 수를 나타내며, False Positive는 실제로 음성이지만 양성으로 예측된 인스턴스 수를 나타냅니다.
J의 값은 -1에서 1까지 범위를 가지며, 1은 완벽한 분류를 나타내며, 0은 무작위 분류를 나타내고, -1은 완전한 오분류를 나타냅니다.

성공 여부와 같이 범주가 2개인 경우, 0과 1과 같은 이진 숫자로 표현됩니다. 성공과 실패를 나타내는 경우에는 일반적으로 1이나 0으로 표시됩니다.
반면에, 혈액형과 같이 범주가 3개 이상인 경우, 숫자로 직접 대응하기가 어려울 수 있습니다.
이런 경우, 일반적으로 각 범주마다 서로 다른 값을 부여해 표현합니다.
예를 들어, A형은 0, B형은 1, O형은 2, AB형은 3과 같이 부여할 수 있습니다.
이러한 방식을 Label Encoding이라고 합니다. 다른 방식으로는 One-Hot Encoding이 있으며, 각 범주를 나타내는 새로운 feature(열)을 만들어 해당하는 범주에는 1을, 나머지 범주에는 0을 부여하는 방식입니다.

One or Nothing은 범주형 데이터를 이진 분류로 변환하는 방법 중 하나입니다.
이 방법은 각 범주별로 하나의 이진 변수를 생성하는 것입니다.
예를 들어, 혈액형 A, B, O, AB가 있는 경우, 이를 One or Nothing 방법으로 변환하면 A or Not, B or Not, O or Not, AB or Not와 같이 4개의 이진 변수를 생성할 수 있습니다.
이 방법은 다중 분류 문제를 이진 분류 문제로 간단하게 해결할 수 있어서 많이 사용됩니다.
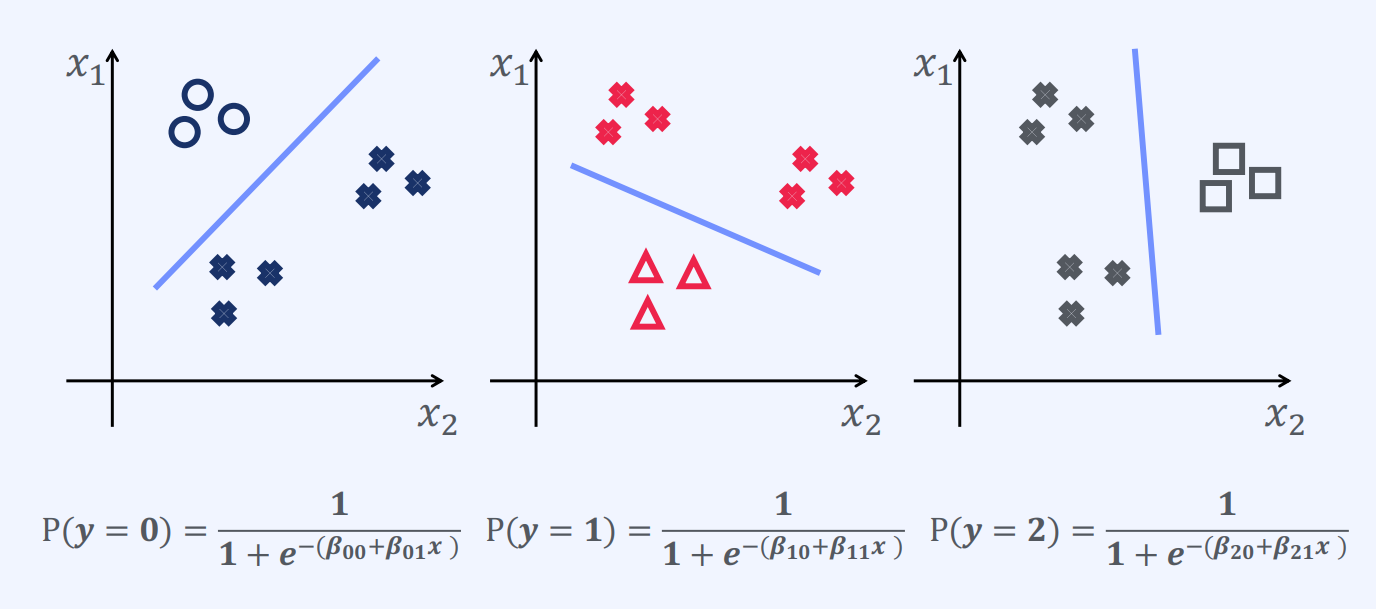
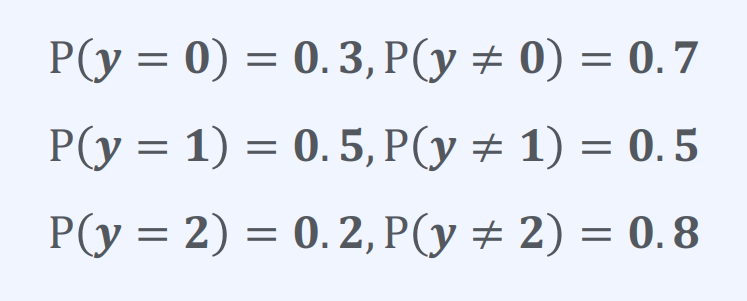


이 문제는 3가지 범주가 있고, 각 범주의 확률이 주어졌을 때,
확률이 가장 높은 범주를 선택하는 문제입니다.
주어진 확률값에 따라 각 범주의 확률은 다음과 같습니다:
P(y=0) = 0.3
P(y=1) = 0.5
P(y=2) = 0.3
따라서, 확률이 가장 높은 범주는 y=1이 됩니다.
즉, 모델은 범주 y=1을 선택할 것입니다.
이 문제에서는 단순히 가장 높은 확률값을 갖는 범주를 선택하는 것이지만,
실제로는 모델이 예측하는 각 범주의 확률값을 활용하여 조금 더 정확한 예측을 수행할 수 있습니다.
