1. df 데이터 중 choice_description 값에 Vegetables 들어가지 않은 경우의 개수 출력
- ~ 취할때 갈호에 주의해야한다. sum()을 포함한 식에 ~ 해주면, -723이 나오는데 이는 true의 전체 합자체에 ~ 가 취해지기 때문
(~dc.choice_description.str.contains("Vegetables", na = False)).sum()2. ~Series : series 데이터 true ↔ false
- 보통 ~는 조건 필터링한 Boolean Series에만 적용한다.
3. 리스트 → str.len()
- 배열은 요소개수, str은 글자수 리턴
- str.split은 정규표현식을 사용할 수 있다.
#42. df 데이터 중 item_name 값의 단어개수가 15개 이상인 데이터 인덱싱
dc[dc.item_name.str.split(r"\s+").str.len() >= 15]4. kss
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "I am actively looking for Ph.D. students. and you are a Ph.D. student."
tokenized_sentence = word_tokenize(text)
print('단 어 토큰화 :',tokenized_sentence)
print('품 사 태깅 :',pos_tag(tokenized_sentence))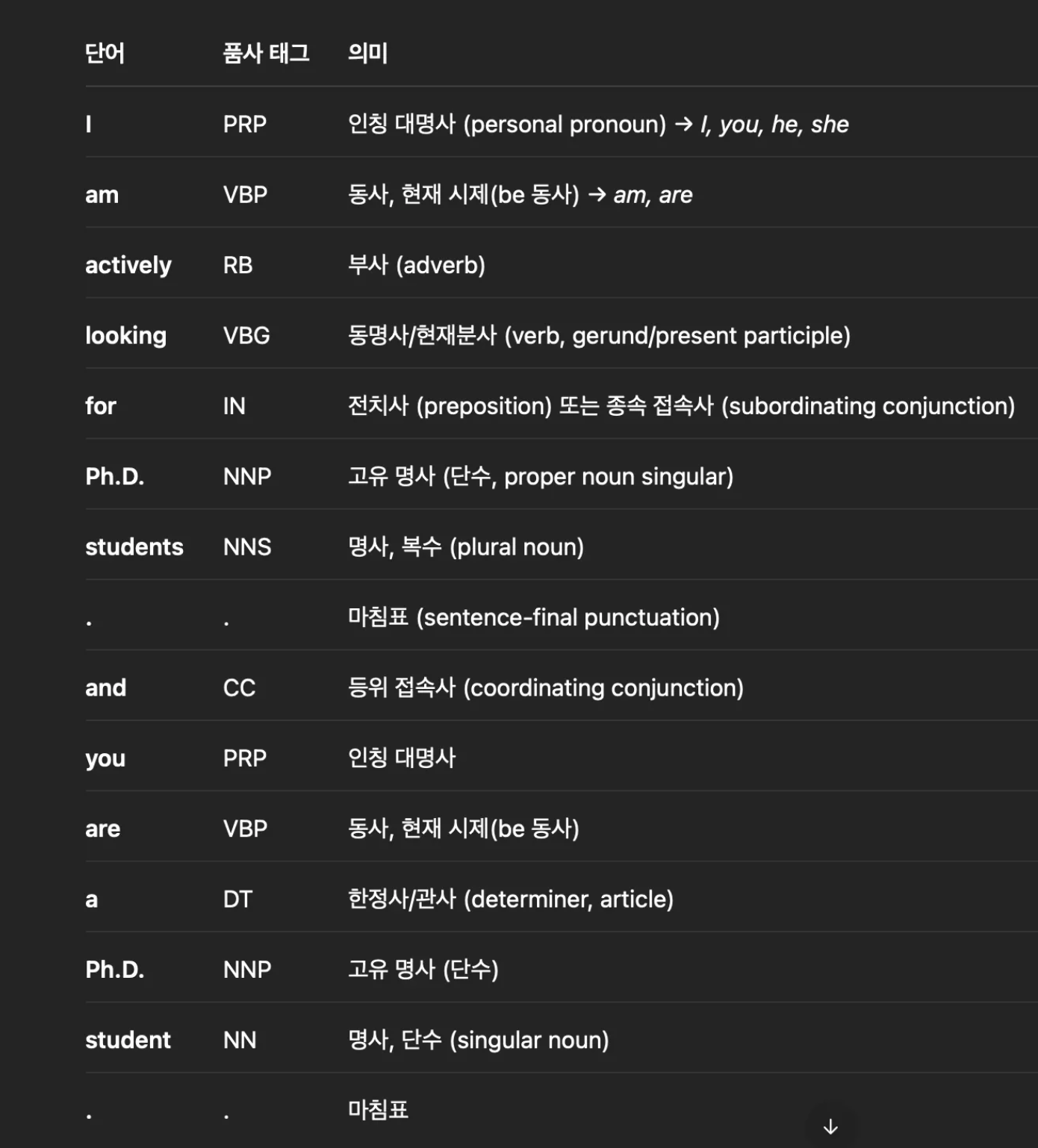
5. Series 로 for문을 돌리면 value 값만 나옴
- idx도 같이 뽑고 싶으면 Series.items() 를 이용한다.
for idx, sentence in sample_data['document'].items() :
if idx <= 10 :
print(sentence)6. np.hstack , np.vstack
import numpy as np
a = np.array([[1, 2],
[3, 4]])
b = np.array([[5, 6],
[7, 8]])
print("원본 a:\n", a)
print("원본 b:\n", b)
# hstack : 좌우로 붙이기
h = np.hstack([a, b])
print("hstack 결과:\n", h)
# vstack : 위아래로 붙이기
v = np.vstack([a, b])
print("vstack 결과:\n", v)
원본 a:
[[1 2]
[3 4]]
원본 b:
[[5 6]
[7 8]]
hstack 결과:
[[1 2 5 6]
[3 4 7 8]]
vstack 결과:
[[1 2]
[3 4]
[5 6]
[7 8]]8. bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
- curl이 GitHub에서 mecab.sh 내용을 가져옴
- <( … ) 문법으로 가져온 내용을 임시 파일처럼 전달
- bash가 그 내용을 즉시 실행

즐겁게 공부하고 사람들에게 도움을 주는 개발자가 되고 싶습니다.