일러두기
- 해당 논문에서
ModelTuning이라 하는 것은 finetuning과 같음: 모델의 parameter를 모두 학습하는 그 finetuning Prompt Tuning은 "The Power of Scale for Parameter-Efficient Prompt Tuning (Lester et al., 2021) 에서 나온 prompt tuning임- model parameter size 11 bln을 기준으로
Prompt Tuning이 finetuning의 성능과 비슷한가 아닌가를 판단하는데, 11 bln parameter size를 갖는 모델은T5 XXL임
0 Abstract
- novel prompt-based transfer learning approach 제안: SPoT: Soft Prompt Transfer
- SPoT의 구조
- 하나 또는 그 이상의 source task에서 prompt 학습하고 target task의 prompt에 initialization함
- SPoT을 이용했을 때 성능향상 있었음
- SuperGLUE에서 실험했을 때 모든 model size에서 finetuning 성능 갱신
- 왜 중요한가?
Prompt Tuning은 efficient하지만 model size가 큰 경우 (>11bln)에만 finetuning과의 성능이 비슷하고 작은 모델에서는 finetuning보다 성능이 못하기 때문
- ablation study: transfer learing이 의미 있음
- approach proposal: task embeddings를 이용하여 similar task를 identify하고, target task에 적합한 transferable source task를 가려낼 수 있음 (그다지 쓸모가 있는지는 모르겠음)
1 Introduction
- Finetuning
- BERT, T5, GPT-3 같은 모델, 너무 커서 downstream task에 finetuning하기에는 expensive
- Hard Prompting (Priming, according to (Lester et al., 2021))
- GPT-3 논문 (Brown et al., 2020) 를 보면
Prompt Design이 나오는데, frozen PLM에다가 manual text prompt 써서 inference 하는 것임 (hard prompting) - 그런데 GPT-3 & hard prompting에 관한 후속연구 (Zhao et al., 2021) 를 보면, hard prompting은 prompt를 어떻게 짜느냐에 따라 굉장히 unstable performance를 보임 (논문 자체는 이러한 unstable performance를 보완하기 위해 calibration이 필요함을 역설함)
- 게다가 hard prompting은 SoTA finetuning result에도 모자라는 성능
- GPT-3 논문 (Brown et al., 2020) 를 보면
- Soft Prompting
- GPT Understands, too. (Liu et al., 2021b):
P-Tuning, soft prompts가 input sequence와 [MASK] token 사이에 들어가는 형태, soft prompts는 prompt encoder를 통과함

- Learning how to ask: Querying LMs with mixtures of soft prompts. (Qin and Eisner, 2021): soft prompts를 ensemble했다는 듯함
- Prefix-tuning: Optimizing continuous prompts for generation. (Li and Liang, 2021):
Prefix-Tuning, task마다 다른 prefix soft prompts 학습 & 갈아끼우기
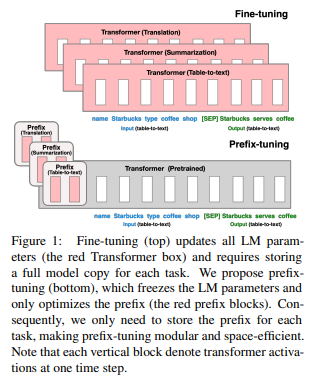
- The Power of Scale for Parameter-Efficient Prompt Tuning (Lester et al., 2021):
Prompt Tuning, 모델마다 다른 soft prompts를 ensemble하여 inference에 사용가능함, 이전에 제대로 안 읽어본 것 같음

- Lester et al. (2021) 의
Prompt Tuning같은 경우, 모델 크기가 11B 이상일 경우, finetuning과 성능 차이가 크게 없는데, 모델이 그보다 작으면 performance gap이 있음
- GPT Understands, too. (Liu et al., 2021b):
SPoT: Soft Prompt Transfer- 하나 이상의 src task에서 prompts 학습시킨 이후 tgt task의 prompt로 initialization함
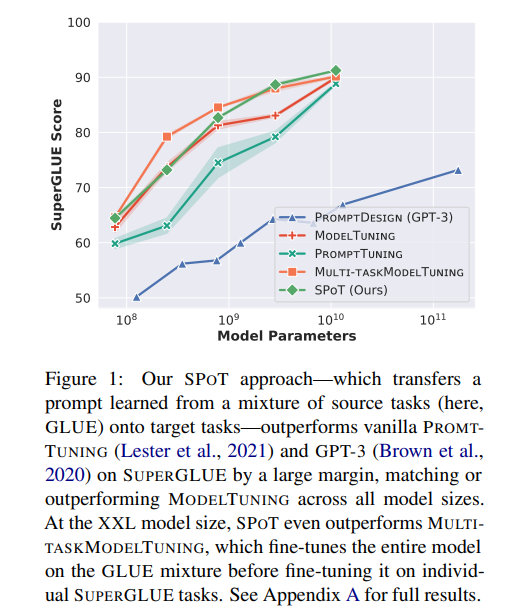
Prompt Tuning에SPoT을 끼워넣었을 때 task와 model size에 따라 performance improvements가 있었음- 또한, 모든 모델 (크기 별로 나열했을 때) 에 따라 finetuning과 성능이 비슷하거나 그보다 높았음
-
task 간 Prompt Transferability에 대한 가능성
RQ1: "For a given target task, when does initializing the prompt from a source task boost performance?"
- 실험은 26개 NLP task에 대해서 160개 combinations, 모델은 T5 사용
RQ2: "Can we use task prompts to efficiently predict which source tasks will transfer well onto a novel target task?"
- learned task prompts를 task embedding으로 구성하고, semantic space로 각 task의 task embedding을 올려보내서 task 간의 similarity를 탐구하였음. task embedding similarity를 계산하는 retrieval algorithm을 만들어 적절한 source task를 찾을 수 있게 하였음
-
Contributions
Contribution 1
SPoT을 제시하고 SuperGLUE에서Prompt Tuning이 모델 크기와 관계없이 finetuning보다 나을 수 있음을 보임
Contribution 2 systematic and large-scale study on task transferability
Contribution 3 task embeddings의 similarity를 계산해서 적절한 target task를 추천하는 retrieval method 제시
Contribution 4 코드 공개
2 Improving Prompt Tuning with SPoT
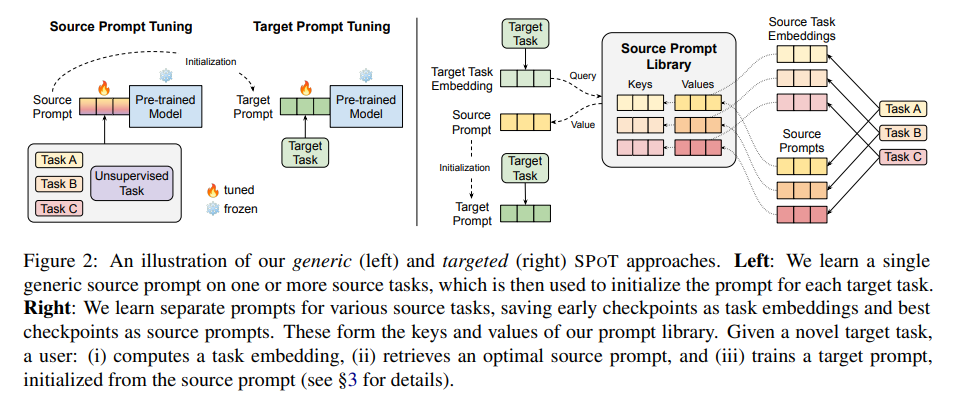
- 2에서는 single transferred prompt를 모든 target task에 쓰는 approach를, 3에서는 different target tasks에 different source prompts를 사용하는 targeted approach를 논의함
2.1 Experimental setup
- 모델은
T5 Small(60 mln),T5 Base(220 mln),T5 Large(770 mln),T5 XL(3 bln),T5 XXL(11 bln) 사용 - LM adapted version (prefix LM objective에 100k additional steps 학습한 checkpoints) 사용
2.1.1 Baselines
Prompt Tuning: Lester et al. (2021), independent prompt directly trained on each target taskModel Tuning(finetuning) &Multi-task Model Tuning(finetuned with multi-task learning):Multi-task Model Tuning은 SPoT과 똑같은 source tasks mixture에서 학습한 후 individual target task에서 finetune
2.1.2 Evaluation Datasets
- GLUE & SuperGLUE
- fixed number of steps에서 학습하고 validation set에 대한 results는 average하였음
2.1.3 Data for source prompt tuning
A single unsupervised learning task
- general purpose prompt 학습을 위해 C4 (Colossal Clean Crawled Corpus) dataset 사용, T5 with prefix LM objective
A single supervised learning task
- MNLI (sentence-level classification task에 효과적) 또는 SQuAD (QA task에 generalize well) 를 single source task로 설정
A multi-task mixture
- NLI, summarization, QA, sentiment analysis 등 C4 + 55 blabeled datasets를 구성하였음
2.1.4 Training details
- Lester et al, (2021) 과 비슷하게 진행
- shared prompt where stands for prompt length (100), stands for embedding size
- training step은 Lester et al, (2021)에서 30k로 설정했는데, 데이터가 커서 로 설정하였음
- prompt token embeddings는 sampled vocabulary (5,000 most common tokens) 에서 sample되었음
2.2 Effect of SPoT
SPoT significantly improves performance and stability of Prompt Tuning
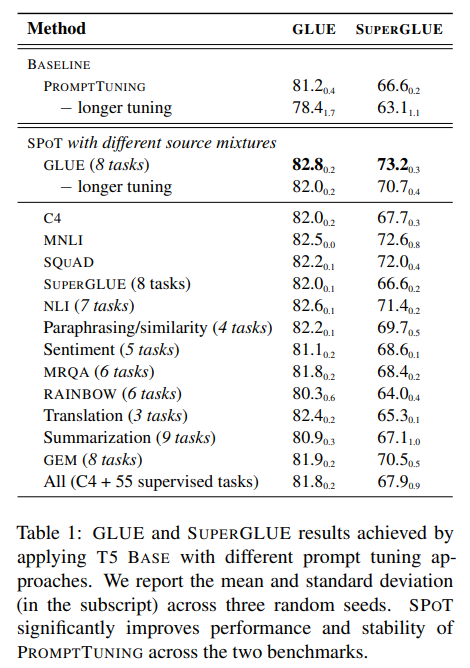
- table 1 을 참조하였을 때, SPoT이 없는 Prompt Tuning과 SPoT을 넣은 Prompt Tuning의 결과가 차이남
- GLUE, Unsupervised source (C4), MNLI, SQuAD 등에서 학습하는 것이 효과가 있었음
- 모든 task를 섞는 게 (table 1 가장 밑) 가장 효과적이지는 않았음
SPoT helps close the gap with finetuning across all model sizes
Prompt Tuning은 finetuning과 비슷한 성능을 낼 수 있긴 함 (Lester et al., 2021)- 다만, T5 XXL 에서나 그러하고 그보다 작은 크기의 모델에서는 finetuning과 performance gap이 있어서 SPoT이 그 gap을 메우는 데에 SPoT이 도움을 주었음
- 일부 모델과 task에서는 finetuning보다 더 높은 성능을 기록하기도 (당연하지만, computational efficiency는 그대로 유지하면서)
- SuperGLUE leaderboard에 올렸더니 GPT-3같은 parameter efficient adaptation은 다 뛰어넘고, finetuned T5 XXL과 거의 비슷한 성능 기록하였음
3 Predicting task transferability
- soft prompt transfer가 효과있는 것은 ok, 그런데 적절한 source task를 어떻게 찾을 것인가?
- chapter 2에서 MNLI나 GLUE에서 학습시킨 게 GLUE, SuperGLUE task에서 전반적으로 좋은 성능을 냈다는 것이 드러났지만, 만약 resource-constrained scenario라서 source task에 대한 exhaustive search가 불가능하다면?
- 위와 같은 상황을 대처하기 위해 target task에 어떤 source task가 transferable할 지 predict 하는 게 굉장히 중요할 수 있겠음
- 실험을 위해 26 NLP tasks에 대해 130개 task combination을 만들어서 실험하였으며, 이후 task embedding을 만들어 task의 semanticity를 이용해 similar task cluster를 만들었음, 이후 task embedding과 similar task cluster를 이용한 retrieval algorithm proposal
- 위에서 제시한 proposal을 사용했을 때 69%의 task search space를 eliminate할 수 있고, 90%의 best-case quality를 keep하였음
3.1 Measuring transferability
- src 및 tgt dataset에 대한 설명
- 왜 160개 task combination이냐: 16개 source dataset과 10개 target datset을 사용하였기 때문
- 16개의 src dataset의 경우, 사이즈가 크거나 선행연구에서 positive transfer를 기록하였던 것들을 중심으로 선정했음
- 10개의 tgt dataset의 경우, realistic scenario를 위해 low resource tasks (<10k size) 를 중심으로 선정하였다고 함
- experiment settings: 회의 steps, source task validation set에 대해서 highest result 뽑은 checkpoint 사용, random seed 3회
Tasks can benefit each other via prompt transfer
- case1: semantic relationship among sentences (e.g. MNLI)
- case2: source and target tasks are similar (e.g. CxC STS-B)
- case3: positive transfer observed even if source and target tasks are dissimilar (e.g. ReCoRD WSC, SQuAD MRPC, CxC WiC)
3.2 Defining task similarity through prompts
-
prompt가 source task에 대해서 update됐네?
learned prompts는 task-specific knowledge를 encoding했겠네?
learned prompts가 tasks의 성질(nature)와 relationships의 reasoning에 이용될 수 있겠네? -
위와 같은 로직을 검증하기 위해 taks specific prompts에 대해 task embedding을 구성해 semantic space에 올렸음 (10k training steps 했을 때)
-
두 task()의 similarity를 두 task의 embeddings() 사이의 cosine distance로 가정하였음: avg tokens cosSim, per-token avg cosSim
Cosine Similarity of Average Tokens
stands for prompt token length
Per-Token Average Cosine Similarity
Task embeddings cpature task relationships
- cosine similarity of average tokens metric을 이용해 tasks의 hierarhical clustering을 구성하였을 때 (figure 4), domain similarity보다는 type of task에 연관되어 묶이는 것을 확인할 수 있었음
3.3 Predicting transferability via similarity
: target task, target task embedding
: source prompts, source task embedding: source prompts를 의 similarity score 결과에 따라 내림차순으로 정리, 은 rank
: 의 embedding
- 모든 src task에 대해서 random seed 3번씩 했으니, 총 16(src task) 3 = 48 개의 src prompts가 도출되며, 이 48개의 src prompt를 모두 사용
- 위와 같은 방법으로 도출된 ranking을 3가지 방법으로 이용: Best of Top-k, Top-k Weighted Average, Top-k Multi-task Mixture
- Best of Top-k
- top-k src prompt를 선정, 각각 tgt prompt의 initialization으로 사용하고 그 중 가장 좋은 결과를 evaluation으로 사용
- Top-k Weighted Average
- top-k src prompts를 weighted average ()하여 tgt prompt initialization에 사용, 따라서 tgt task에 대한 실험은 단 한 번
weights
- top-k src prompts를 weighted average ()하여 tgt prompt initialization에 사용, 따라서 tgt task에 대한 실험은 단 한 번
- Top-k Multi-task Mixture
- Top-k 개의 prompt에 해당하는 dataset(task)와 target dataset(task)를 모두 mix해서 sampling (T5의 방식과 동일)
- 위의 multi-task mixture에 source prompt tuning
- 위의 source prompt tuning 중 final prompt checkpoint를 선정해 target prompt tuning에 사용
- 각 method는 all tasks에 대해 average하고 baseline (target task prompt tuning only) 에 대한 improvement를 기록하여 report
- 이외에도 top-k 방식을 사용하지 않고 48개 source prompts에 대한 brutal force algorithm을 사용한 결과도 실었음
Correlation betweent ask similarity and tasktransferability
- 10개 중 4개 target task만 task embedding similarity와 task transferability의 positive correlation을 발견할 수 있었음
- 따라서 task similarity 외에 다른 factor도 task transferability에 영향을 미칠 수 있음을 시사함
Retrieving targeted source tasks via task embeddings is helpful

- 3개 method 중에서 "Best of Top-k" method가 전반적으로 가장 좋았음 (table 3)
- "Best of Top-k" 중에서도 "Per-Token Average Cosine Similarity"의 task embedding similarity가 높을 때 좋은 성능이 나왔음
- "Best of Top-k"에서 k가 커질수록 Brute Force와 성능이 비슷해지는데, 그래도 2/3 정도의 src prompt를 제거함으로써 computational efficiency를 챙길 수 있음
- "Top-k Weighted Average"의 결과는 "Best of Top-k (when )"와 비슷했는데, 이는 multiple prompt tuning runs가 불가능할 때 선택할 수 있는 대안으로 사용할 만함
- "Top-k Multi-task Mixture"의 결과는 보다 성능이 좋았음
4 Related Work
Parameter-efficient transfer learning
- LLM(BERT, RoBERTa, XLNet, ALBERT, T5, GPT, DeBERTa)을 practically apply하기 위한 시도들: 모델을 어떻게 경량화할지, 혹은 어떻게 모델의 일부분만을 바꿀지 고민
- 초창기에는 compression technique를 사용해 lightweight model 획득: Distilbert, TinyBERT, LayerDrop (Fan et al., 2020), Movement Pruning (Sanh et al., 2020)
- Bitfit: 모델의 일부만을 update
- Adapter, Hyperformer: adapter와 같은 task-specific module을 사용
- Compacter, Lora: 다른 연구의 경우 low-rank structure를 사용
- Hard Prompting
- GPT3 논문에서
Prompt Design(hard prompting) 제안 - Schick and Schuetze, 2021: manually handcrafted prompts
- Jiang et al., 2020b: prompt mining & paraphrasing
- AutoPrompt: gradient-based search for improved prompts
- Gao et al., 2021: automatic prompt generation
- Zhao et al., 2021, Liu et al., 2021b: 위와 같은 연구에도 hard prompts는 sub-optimal & prompt 선택에 sensitive 할 수밖에 없다는 한계
- GPT3 논문에서
- Soft Prompting
- Liu et al., 2021: systematic survey on soft prompting
- Liu et al., 2021b, Qin and Eisner, 2021, Prefix-Tuning, Lester et al., 2021: learnable parameters injected into the model (대표적인 soft prompting 논문들)
- Prompt Transfer
- PPT (Gu et al., 2021): hand-crated pretraining tasks tailored to specific types of downstream tasks -> less extensible to novel downstream tasks
- 본 논문에서는 src task로 이미 존재하는 것들을 사용하고, src task와 tgt task 간 task type이나 input/output format이 달라도 prompt transfer가 의미있음을 보여주었다는 데에 큰 차이가 있음
Task transferability
- 보통 src task는 data-rich, requires complex reasoning and inference, similar to tgt task 임
- task transferability prediction에는 task embeddings나 adapter based alternatives가 사용된 바 있음
- 본 논문에서는 task specific components를 덧붙이지 않고 똑같은 모델을 사용하고, t2t format을 사용하면서 task space modeling이 잘 되었음
- 덧붙여, prompt-based task embedding이 cheaper..
5 Limitations & Future work
- 특정 케이스에서 다른 모델들이
Prompt Tuning의 성능을 뛰어넘었는데, SPoT 또는 SPoT과 비슷한 모델이 전술한 모델들에도 확장될 수 있는지 여부 Prompt Tuning만의 장점 (갑자기 왜 이게 나오지.. 디펜스 하는건가..)- most parameter efficient approach
- simpler than other models (Prefix-Tuning (Li and Liang, 2021) 의 경우에는 Transforemrs encoder와 decoder block 전부에 prefix를 넣어야함) + allows mixed-task inference and facilitates transfer learning between tasks
- 모델 크기가 커질수록
Prompt Tuning의 성능과 finetuning의 성능 gap이 작아지고, 다른 모델은 그러지 않음 - soft prompt could be interpreted as natural language instructions
- future work: task transfer에 영향을 미치는 다른 factor를 찾는 연구
6 Conclusions
- 본 연구는 prompt tuning에서의 transfer learning에 관하여 탐구하였음
- 모델의 크기와 관계없이
Prompt Tuning이 finetuning과 비슷하거나 더 나은 성능을 낼 수 있는 방안을 제시하였음 - large scale study를 통해 task 간 prompt transferability가 가능함을 확인
- task prompt를 task embedding으로 바꾸어서 task 간 similarity 계산을 할 수 있음을 확인
- 간단하면서도 효율적인 approach를 사용해 src-tgt task 사이에 transferability prediction을 수행하였음
다음에 읽어볼 논문들
"The Power of Scale for Parameter-Efficient Prompt Tuning" (Lester et al., 2021)
